
Collection agents emerged to alleviate the pain of having log files distributed around your application servers. However, they brought new problems since each log analysis tool wanted its own agent, trading in its own protocols and/or formats, usually targeting only a single use case. Meaning you had to install multiple agents for different use cases. Onboarding data and managing all these agents seems to be an afterthought. Finally, they were a pain to keep up to date: You’re the log geek, not the software update monkey!
A Solution: Cribl Edge

What if you could optimize to one agent for all your collection needs? To be 100% clear, Cribl will work with just about any agent you want. Our goal for you is to collect exactly once and route, filter, aggregate, and transform as needed from that single collection. All while using open formats and protocols. Using Cribl Edge as your one agent does all that and gives you superpowers. Like…
Open data formats. Cribl doesn’t lock you in with proprietary storage and formats. Stop giving ownership of your log data to a closed third-party system. It’s your data; you should be able to pack it up and move it to a new vendor whenever they show more value to you.
Ease of management through a common, intuitive, and easy interface. A PhD in Kafka shouldn’t be required to build your logging estate. Cribl offers an easy interface, mostly low-code, and always free training to back it all up. Wouldn’t having one place to control your entire collection be nice?
Stay Up to Date: Cribl’s interface includes update control, putting Edge and Stream updates at your fingertips.
Search data where it lives without having to move it first. Cribl Search can communicate back to Edge nodes (through the Edge Node <> Leader connection) and search files, events, or metrics that have never been ingested. Check out Disk Spooling for even more money-saving goodness.
Kubernetes logs and metrics collection. Cribl Edge can run as a daemon on your K8s pods, making low-code data collection and clean-up easy.
Now, let’s discuss the ” how.” We’ll start by setting up the (intermediate) receiver in Cribl Stream.
Edge Tips: Receiving from Edge
Architecture Brief: Direct Delivery or Ride the Stream?
Before we start setting up, we need to consider the path your data will take on its way to your destinations. Edge can deliver directly to object stores and the same bunch of other tools as Cribl Stream, but our best practice is to use Stream with Edge in tandem.
Deliver to Cribl Stream first so that any filtering, transforming, routing, aggregation, and delivery happens on a dedicated server cluster working exclusively on those tasks. Don’t bother your app servers with extra work. It also generally means easier firewall management with fewer sources sending to the final, often external, endpoints.
ℹ️ That’s not to say Cribl Edge delivery to final destinations is taboo. It may very well be the best option in your use case. We are incredibly flexible! But consider carefully. This post discusses the Cribl Edge -> Cribl Stream -> [destinations] flow.
TIP: Reviewing above… use Cribl Stream as an aggregation point for your logging estate. Let Stream do the heavy lifting. Leave your (Edge) agents to collect and ship logs only, staying out of the way of the servers’ primary work.
Your Cribl-to-Cribl Connections
When sending the data from Cribl Edge to Cribl Stream, what protocol should you use? You can send data using any of the protocols Cribl supports. However, the Cribl TCP and Cribl HTTP protocols offer a distinct advantage in Cribl-to-Cribl conversations. Namely, they do not introduce another ingestion point in accounting. The only requirement is that the sending Edge Node and the receiving Stream Node must be connected to the same Leader.
TIP: The transport from Cribl Edge to Cribl Stream should be Cribl HTTP. It’s the same as the HTTP source – open JSON over HTTP posts – but you get the 0-cost ingest benefit. Since it’s HTTP-based, it can traverse most proxies with no issue. And it’s hyper-efficient with compression. Finally, it’s simple to load balance internally or with external LB appliances.
Preparing for Cribl-to-Cribl Delivery
If you’re sending to Stream Workers in Cloud, a Cribl HTTP source is ready, listening on 10200. Enable it if it’s not already. You can see this in the Data Sources settings area on the Cloud Portal. Note that you will need to have provisioned the workers. The address provided for Cloud-based Cribl HTTP is a VIP on a load balancer with TLS enabled, so there is no need to worry about either of those issues. Noice.
If you’re sending to Stream Workers that you manage yourself, you’ll need to enable the default endpoint for Cribl HTTP or create a new one. You will also want TLS enabled. Cribl makes it easy. Go forth and TLS all the things. The default port for Cribl HTTP is 10200, but feel free to choose any you want.
Regardless of self-managed vs. cloud decisions, we should have ports listening to our Stream Workers, aka the receiving side. You can check the port is up and reachable by testing a connection from an Edge node (the sending side):
$ nc -zv hostname port
You can check that the server is starting a TLS handshake by using OpenSSL:
$ openssl s_client -connect hostname:port
TIP: You are going to enable TLS, right? Yes, you are. Because we live in high society. Create certificate objects in Group Settings -> Security -> Certificates, then enable TLS and select the cert you created. You can reuse the cert on multiple inputs or use unique certs for each source.

Load balancing from the sending side will be a concern. It’s handled automatically in the Cloud. For self-hosted Worker Nodes, you have a few load-balancing options. Choose one:
Use a load-balancing application or appliance. F5, HAProxy, etc.
List out the worker nodes host-by-host in the destination config.
Use a DNS name that resolves to all the Worker IP addresses. If you choose this route, turn down the TTL for the record to something very short. If you need to update it, you don’t want the senders caching old info for three days.
TIP: I prefer option 2 above with a script to quickly update the Edge configs via API. No extra hardware is needed, no extra hop in your data path, and no extra complexity to manage and support. I prefer to be in control of all my domains.
Here’s an example HTTP conversation for replacing the host list in my out_cribl_http destination in the Fleet named default_fleet. I’ve specified two receiving hosts of equal weights:
PATCH https://myleadernode/api/v1/m/my_fleet/system/outputs/out_cribl_http
content-type: application/json
accept: application/json
Authorization: Bearer myverylongbearertoken
{
"urls":[
{"weight":1,"url":"https://stream1:10020"},
{"weight":1,"url":"https://stream2:10020"}
],
"id":"out_cribl_http",
"type":"cribl_http"
}This could be incorporated into deployment orchestration with some elbow grease and creativity.
Routing Data at the Stream Tier
Cribl Stream and Edge offer two ways of routing data:
Data Routes: You can match any part of the events’ raw data, metadata, and source connection to decide what to do with the data.
Quick Connect: Tells Cribl to take ANY data from a source and send it to 1 or more destinations.
Most often in Stream, you’ll find Data Routes that are more up to creating more specific routes.
However, the Quick Connect routing option makes sense on the Edge side. Remember, we are trying to reduce the work Edge Nodes do. To this end, we will wholesale shuffle all collected data to Stream for processing, content inspection, filtering, routing, etc. There is no need for the capabilities the Routing Table offers.
ℹ️ Our documentation has an excellent overview of the differences.
TIP: Use QC for Edge Nodes and Data Routes on Stream Nodes. This configuration option is in the source settings under Connected Destinations.
Speaking of routing, an aside: All the data arriving at a Cribl HTTP source will be labeled with an __inputId of cribl_http:in_cribl_http or similar. The original metadata from the collection point has been moved to __forwardedAttrs:
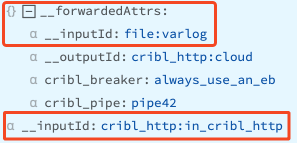
As always, you can filter based on that information. You can also use the original fields in your data. Finally, you can define new fields in your source configuration. See further down below for an example.
Edge Tips: Sending from Edge
Destination: Stream
Start the Edge config by setting up the Edge destination first. We’re using the Cribl HTTP destination to point to your Stream workers. Go to the Fleet’s Collect tab, and set up the new destination there. Most often, you won’t need anything special here. Enable TLS because you already enabled it earlier on the receiving side, and again, you’re a gentleman or lady of high society.
TIP: You won’t usually need to enable persistent queues on Edge because the use case most often collects logs already written to disk. If the destination (Cribl Stream HTTP) goes down, Edge will stop reading files, wait for the situation to resolve, and then pick up where it left off. However, a dedicated disk queue on the destination may be a good option if your logs have short roll times compared to when you could be down.
Spooling
TIP: Check out the Disk Spool destination! In combo with Cribl Search, this is a valuable option for rarely searched data and doesn’t need to be retained for any time. Once you have a Disk Spool config, you can point system metrics at it. Using Search, you can query the disk spool data without ever being ingested or stored outside the Edge node.
Once you have the destination ready, you can move on to Sources.
Defining Sources
In your Fleet settings, go to Collect. Click Add Source to add a new source or use the pre-configured file monitor source, in_file_auto. If you hover over the tile, you can click on the Configuration screen.
TIP: The auto file monitor is niftier input than your typical one. It polls the system for open files and will match the “Filename allowlist” to identify files that need to be monitored. See our fantastic documentation for more info on File Monitors (and other sources).
Classify and tag your data
TIP: Qualify your data in the collection/pipeline process as early as possible. This makes routing and filtering much more accessible, especially in Cribl Stream. Use the Fields option in your collection source to add your identifying field, and your routing table will be cleaner and easier to manage. Since it’s a blue-stripe field, you can use any JS expression, including the C-expressions. Go nuts. This example is very simple:
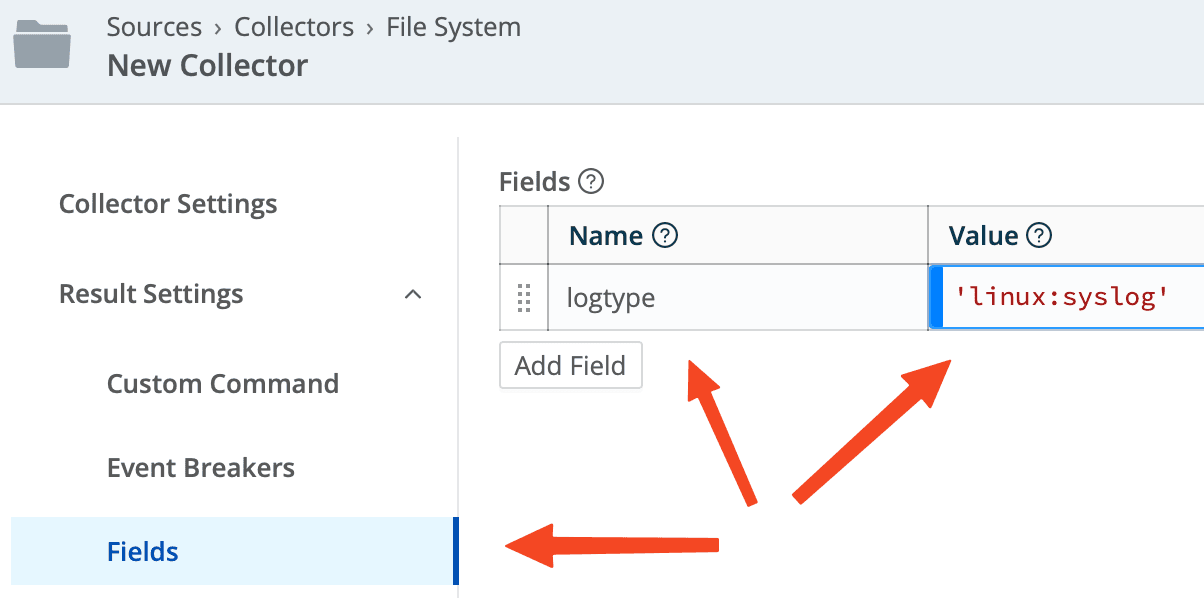
With that in place, filters in Stream become simple and easy to grok at a glance:

Connect the Dots to Route
After saving your source configuration, you can drag and drop to connect the source to the destination. Target the Stream HTTP destination you created previously. Commit and deploy, and you’re off to the data collection races.
Clicking on a connection line will allow you to add a Pipeline or a Pack to the flow. If you disconnect the destination side and drop it in the white space between, you will be prompted to confirm the route’s deletion.
Wrapping It Up
Cribl Edge is like getting a cheat code in metrics, events, logs, and telemetry collection. In combination with Cribl Stream, it gives you ultimate customization. As demonstrated above, starting at the receiving end and working backward helps me make sense of the data flow as I build it out.
Understand and define, if needed, the Destinations Stream will be sent to
Define or identify your Sources in Stream that Edge will be delivering to
Use Cribl HTTP as the transport between Cribl instances
Define the Destinations in Edge pointing to the Sources in Stream
The Cribl HTTP Source above
Define the Sources in Edge that will point to the Destinations in Stream
Label your sources with simple tags to make routing and filtering easier
Once data is flowing, optionally build any Pipelines and/or Packs in Stream to fix up, jazz up, and otherwise make your events awesome
You can learn more about Cribl Stream and Edge in our sandboxes. If you’d like to discuss Cribl, you can find me and other Cribl Goats in our community Slack.






