

Let me set the record straight before anyone accuses me of bias or not being an OpenTelemetry supporter. Cribl loves OpenTelemetry! We’ve written lots of blogs about It; we have vendor-specific OpenTelemetry Destinations (with more to come!), and we support automatic batch parsing for easier data manipulation and re-batching for network transport efficiency of logs, metrics, and traces. We even support automatically translating dimensional metrics, like Prometheus and statsd, into OpenTelemetry Metrics format.
As huge fans of vendor-agnostic telemetry, customers and prospects often ask about using the OpenTelemetry Collector. Should they use it? How should they use it? Does OpenTelemetry require the OpenTelemetry Collector? The answer is “it depends,” except for the last question. OpenTelemetry does not require the use of the OpenTelemetry Collector. It is an example agent model, not a prescriptive approach.
When this question was posed to us recently, it was a particular scenario – Which is better for processing logs, the OpenTelemetry Collector deployed in Gateway mode or Cribl Stream, when sending those logs to S3 and OpenSearch?
Now, that’s something we can test! And we did. We set up a single instance of the OpenTelemetry Collector and a Cribl Stream Worker, limiting both environments to a maximum of 1 CPU core capacity while allowing multi-threading. Using an AWS c7g.4xlarge (16 CPUs, 32 GB RAM, AWS Graviton3 ARM64), we created the environment using Docker and standardized on Syslog RFC 5424 formatted logs with 2 million messages read from the local disk. Each of those 2 million messages averaged about 250 bytes each.
The result? Cribl Stream is better than the OpenTelemetry Collector in the three test scenarios.
Shocked? I bet. Especially if open-source agents are a passion, read on! Let’s talk about the definition of better and review the facts.
Define “Better”
At Cribl, the ethos includes choice, control, and flexibility. As a customer said at CriblCon 2024, “It’s your data. You shouldn’t have to work for it. It should work for you.” Whether it is OpenTelemetry Traces, Prometheus Metrics, Palo Alto firewall logs, SNMP Traps, or data accessible only via API, Cribl believes that the data should be accessible in a way that unlocks opportunities to use it, not locked within proprietary formats, protocols, or platforms.
How does that help define “better”? Simple. In our testing, we measured CPU and memory usage, CPU time, and Events per Second (EPS) in the various scenarios. To make a fair resource comparison, we normalized the Events Per Second (EPS) rate across both tools to ensure the tests were evaluated on an equal workload without requiring multiple instances for the OpenTelemetry Collector. We did this so that it was an apples-to-apples comparison and to save you from doing the mental math.
Think about it like choosing a flight: “better” might mean “cheaper” or “faster”. A direct flight to your destination might cost 30% more than a flight with one layover, so the layover flight is better for cheapness. You’d be trading extra time spent on a layover against price, and if you can afford that time, the 30% increase for a direct flight won’t make sense. If budget is a hard constraint, then even 1% may not be justifiable for the direct flight. On the other hand, when time efficiency is the most critical factor, direct flight is the best option. Spending 30% more to avoid a known layover or the added risk of a delayed flight, lost baggage, or weather mishap, not to mention that you might need to pay for meals and services along the way.
So, what is better? It simply means that the same outcome can be achieved using one method vs. another as measured by operational efficiency.
The Facts. Just the Facts.
In each set of tests, we sent syslog 5424 through either the OpenTelemetry Collector Contrib or Stream and then on to OpenSearch and/or S3. Why syslog 5424 vs. traces or some other application-aligned signal or format? The customer who initially asked about performance comparisons wanted syslog to go to a SIEM and S3, and we used OpenSearch as a proxy for an SIEM. Depending on the vendor and implementation, a real-life SIEM might add backpressure to this scenario, but it won’t likely be faster than OpenSearch.
Test Scenario 1 – OpenSearch & S3
Winner: Cribl by 3.8x
This scenario involved sending syslog events to OpenSearch and S3. As in all scenarios, we sent 2,000,000 events and 500,000 in each of 4 consecutive test runs that ran back-to-back. The OpenTelemetry Collector Contrib only enabled batching with a timeout and no memory limits. We went big with send_batch_size: 500000 and timeout: 30s, at least for this first round of tests.
Fellow OpenTelemetry nerds may be asking, “Why no memory limits? That’s not the recommendation!” We did a test with a default (no configuration) OpenTelemetry Collector Contrib install, a Collector configured with both memory limits and batching, and then just batching. The performance metrics below represent the best test results – the ‘batching only’ configuration. The zero-config Collector performed 30x worse than Cribl, and the memory limits and batching performance were 8x worse than Cribl. We opted to show the details for the best performance.
The “Normalized EPS Multiplier” is needed to make the EPS rate consistent across both environments. Because we were limiting our testing to a single CPU, running the OTel Collector at the same EPS rate would have required setting up a load balancer and multiple instances of the Collector to test. Specifically, we would have needed 4 OTel Collector instances (5 if we wanted N-1) behind a load balancer. We thought that was a bit of an unfair advantage; Cribl Workers can scale up to 4 instances by changing a single line in the UI or config file, so we decided to work on the assumption that performance would scale linearly across memory and CPU at the same rate as EPS.
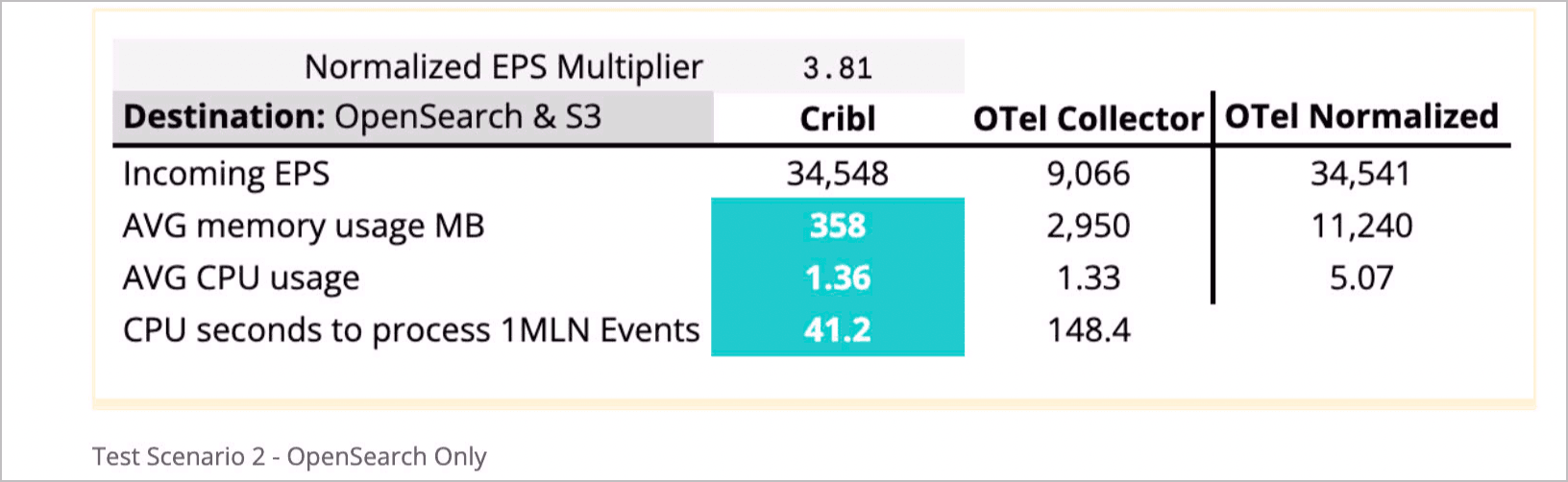
Test Scenario 2 – OpenSearch Only
Winner: Cribl by 3.75x
To eliminate S3 or OpenSearch slowing down the processing for the other, we did additional tests for both (see Test Scenario 3). Writing to an OpenSearch instance run on another EC2 instance, using the same hardware configuration and in the same VPC, yielded very similar results. Concerned with memory usage in Scenario 1, we tweaked the batch size and timeout for the individual destination tests to optimize the performance settings, such as send_batch_size: 8192 and timeout: 200ms.
The non-normalized memory usage below helped compare to Scenario 1. Memory usage was down more than 10x over S3, which makes sense as writing to OpenSearch is significantly faster and would require fewer messages to be held in memory before sending. Faster sending and smaller batch sizes resulted in less memory usage, which also means less CPU usage, down almost 3x compared to the first test, to process those records. And, of course, CPU seconds to process 1 million events was also down, coming in almost 5x faster than before
Normalized to a consistent set of work as measured by EPS, Cribl still came out on top, processing the same amount of data with less memory and CPU usage. The CPU time to process 1 million events, already a normalized measurement, came in lower than our combined tests but still favored Cribl by a factor of 2x.

Test Scenario 3 – S3 Only
Winner: Cribl by 47x
This scenario threw us for a loop. And, yes, the decimal is in the right place. Sending to an S3 bucket was ridiculously inefficient using the OpenTelemetry Collector Contrib vs. Cribl. We ran the test multiple times with similar results. Honestly, we hope we have something misconfigured as numbers like this are just hard to defend, even from the top performing side. The numbers below include the 6x difference in CPU seconds to process 1 million events.
Tuning the configuration per Exporter is tough, requiring some significant trial and error. Searching Github, vendor documentation, and other resources gives wildly different advice on tuning the OpenTelemetry Collector performance. Matching Receivers and Processors with an optimized configuration of Exporters is definitely one of the limiting factors to running the OpenTelemetry Collector at scale, especially in a centralized processing environment, which OpenTelemetry calls gateway mode.

Is There a Moral to This Story?
Testing is hard. Replicating real-world scenarios is a challenging prospect we were fortunate to hand over to our performance engineering team. While several test results exist, including the automated tests for the OpenTelemetry Collector Contrib distribution, we believe that testing on the same host, even within the same Kubernetes cluster, is not the whole story. Where telemetry sources are on different machines, maybe different VPCs, regions, or even cloud providers, moving telemetry adds complexity and performance degradation.
Use lightweight agents with complete lifecycle management (configuration and upgrades) to collect and lightly process telemetry as close to the source as possible. Send that telemetry to a centralized data plane in the same region, or at least the same cloud provider, to minimize the impact of network latency and other queuing mechanisms on your telemetry pipelines.
To have choice, control, and flexibility takes some planning. If you want to have flexibility in the tools used to store, visualize, and analyze telemetry, or if you want the choice to change or consolidate agents, there must be a layer of control and stability. As the tests above demonstrate, Cribl Stream delivers optimal performance, control, and stability. Cribl Edge offers flexibility and control with full lifecycle management even when scaling to hundreds of thousands of nodes for collecting telemetry on a host or in a remote environment.
The moral of the story? Test like your production environments depend on it because it does.






