

You can use the 1Password Events API to retrieve information about activity in your 1Password account – like audit events, item usage, and sign-in attempts – and send it to your security information and event management (SIEM) system. If your compliance/retention needs require you to store data longer than the default 120 days in the 1Password Events API, use Cribl Stream’s flexible routing architecture to send copies of the API sourced event into the data lake of your choosing.
We continue to see enterprises investing in cloud native SaaS solutions which drives the need for enterprises to get organized with how they retrieve data, route, store, and access this valuable data. APIs will be an indispensable tool in helping organizations to identify gaps in their visibility, establish and maintain more effective log management for their cloud-based tools, and maintain compliance with data privacy and retention standards and regulations. Rather than one-offing a bunch of lambdas or scripts across the organization over time to interreact with vendor APIs, you can centralize efforts around Cribl Stream as a single console for managing all your API integrations.
Cribl Stream provides a powerful REST Collector framework and I will walk you through my approach for building a collector. I’ll share a very helpful troubleshooting trick as you step through the various stages of building a collector. I’ve used plenty of curl and python to work my way through the process of building collectors, but I’ve been using a reverse proxy recently when up against a slightly more complicated API. In this case, 1Password leverages different variables in the HTTP body for the first then successive queries to the API and the reverse proxy shows me exactly what my queries and the APIs responses include.
The completed 1Password REST Collector has been published in this Cribl repo. The readme file provides instructions for installing and testing the 1Password REST collector.
The general approach for building a REST Collector involves these steps:
Authentication. The bearer token can be a static token or one that you need to capture dynamically for short-term reuse.
Retrieve Events. Cribl Stream provides a ton of options here spanning both the Discover phase (if needed) and the Collect phase. The vendor API docs will guide you to the correct combination. You will also usually configure time variables within your query to make sure you inherit value for “earliest” and “latest” from the job or scheduler initiating the query.
Pagination. For vendor APIs that return a large amount of data, you will likely need to make multiple queries while keeping track of where each successive query needs to start and when the job is complete.
Event Breakers. For performance reasons, the API should return multiple events for each query and we will need an event breaker to unwind them into individual events and to capture the correct timestamps.
Scheduling and State Tracking. Cribl Stream provides scheduling resources so your Collector jobs can be run on a recurring basis AND it also provides the ability to keep track of where the previous query left off to prevent gaps and overlaps in retrieved events.
In the below sections, I will walk you through the process I used to create a Collector for 1Password since it involved some tricky dynamic querying related to pagination. I used a reverse proxy to help get the queries validated for both the initial query and for additional queries as I keep track of where I am in the pagination process. Please note that all data involved in the creation of the below collector and event breaker is synthetic data sourced from a 1Password partner dev instance. It’s not customer data.
Authentication
Every call to the 1Password Events API must be authorized with a bearer token created within the Integrations section of the 1Password console. You must include that bearer in the header of each of your requests. The first thing I needed to do for creating this 1Password REST Collector from scratch is to configure my headers by specifying values for headers named “Content Type” and “Authorization” as detailed below.
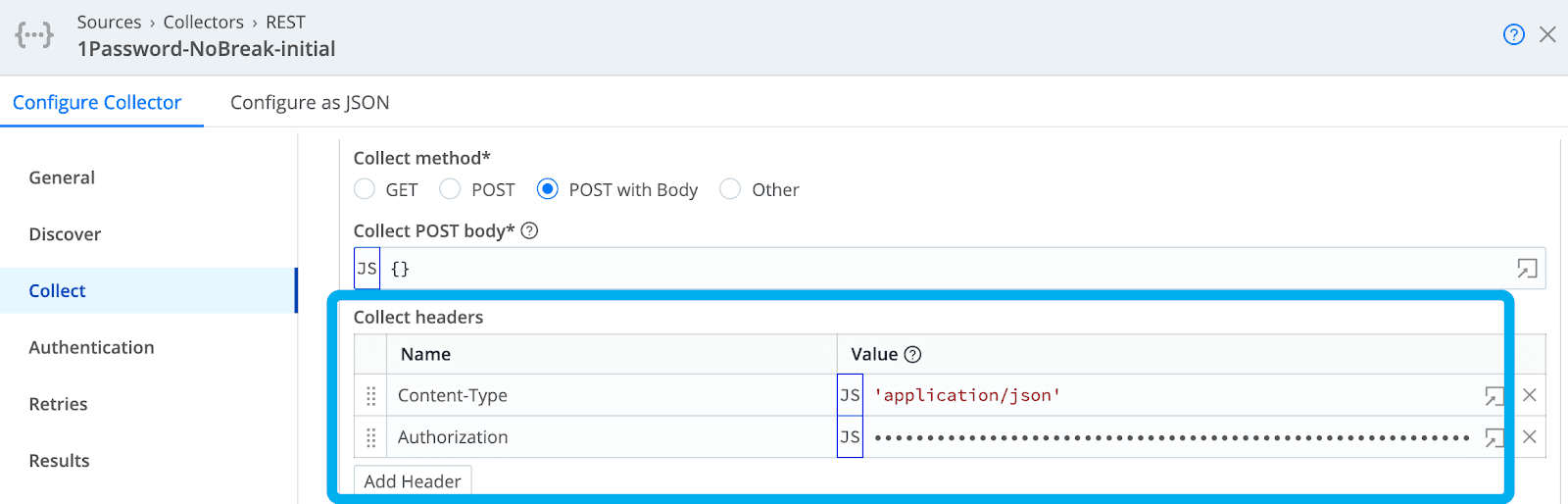
Retrieve Events
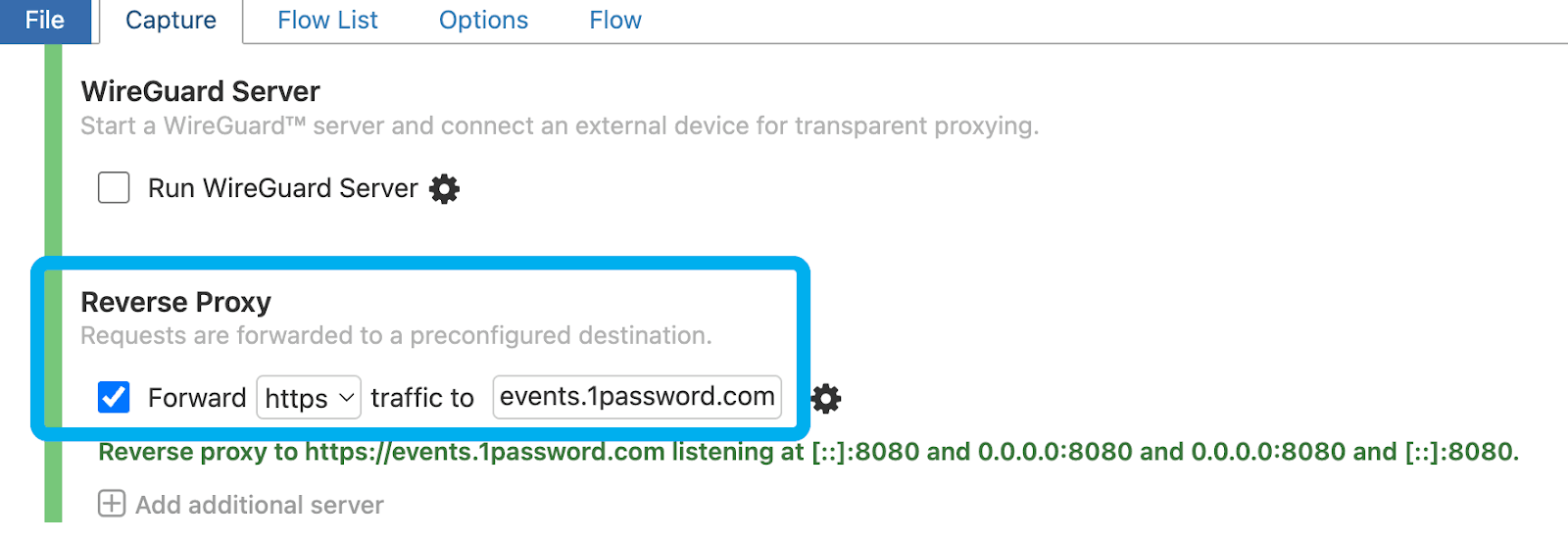
The initial review of the 1Password Events API docs brought my attention to the fact that I needed a different query structure for the initial query than I would need for successive queries related to the requirement to paginate by keeping track of a cursor that the API returns. I chose to use a free tool called mitmproxy which I installed on small virtual instance to act as a reverse proxy so I could see exactly what my queries and the API responses looked like. I could have absolutely used curl to do this but the reverse proxy transparently handle successive queries automatically while recording everything to a console providing a complete understanding of all requsts and responses.
I ran the following command on my instance console to start the proxy: “mitmweb --web-host 0.0.0.0 --web-port 8081 &”. It returns a link for me to configure the reverse proxy as detailed below. I’m forwarding all requests I get to my instance (port 8080) to the 1Password API endpoint. Take note that my Collector testing will point to the IP addresses of my reverse proxy which then proxies them to the 1Password API endpoint.
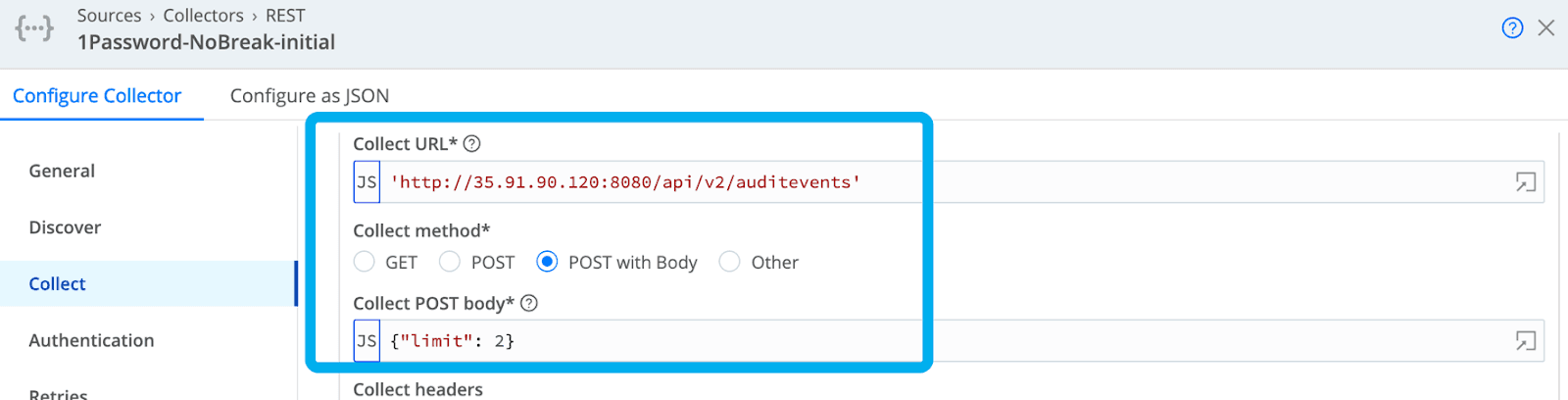
As detailed in the 1Password Events API docs, all queries must be structured as HTML Posts. The initial query must be structured as a JSON object with optional values for the following fields: limit, start_time, and end_time. I will not specify start_time or end_time initially but will go back and populate them later. I want to specify a small value for the limit field to make sure I understand what the response values look like for my next query as it relates to pagination. Get started by passing a JSON object specifying the limit value in the HMTL body to the URL as detailed below. Take note that I am sending these requests to the IP address of my reverse proxy.
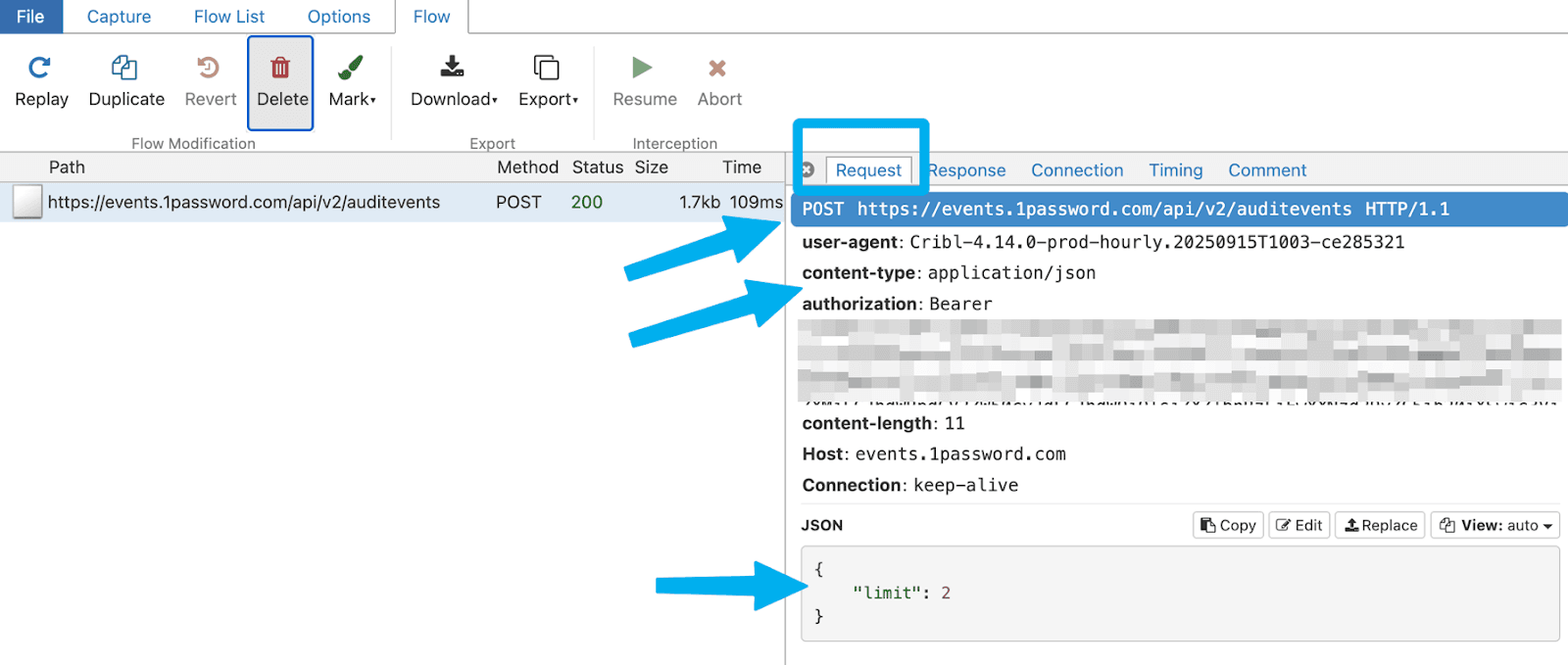
After I run this collector, I can review the details of my request and the response from the 1Password API through the lens of my reverse proxy. From the Request tab, I can validate that I am POSTing to the proper URL, my header fields (content-type and authorization) look good, and my JSON object is being passed correctly in the HTML body.
Pagination
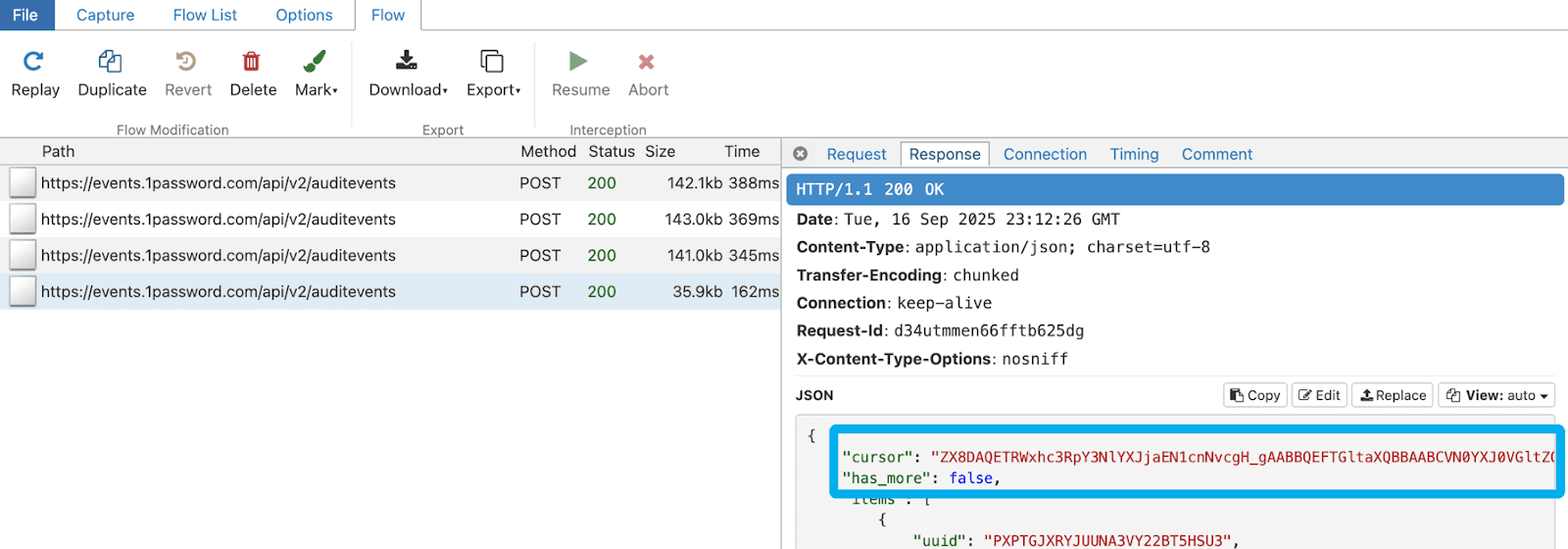
As I move into the Response tab or my reverse proxy, I see several important values that I need to account for. As detailed in the 1Password Events API docs, I know that I am going to need to track the values for both the “cursor” and “has_more” fields for managing the pagination process. If the value for “has_more” is “true”, I need to keep making requests that use the value of the “cursor” field as the starting point for the next query. I also notice that multiple records are returned in this response, and they are objects under the “items” array. This will be important later when creating an event breaker to separate them out into individual events. I also see a timestamp fields in there that I will also include in the event breaker to carry the embedded event/record time into the Cribl _time value.
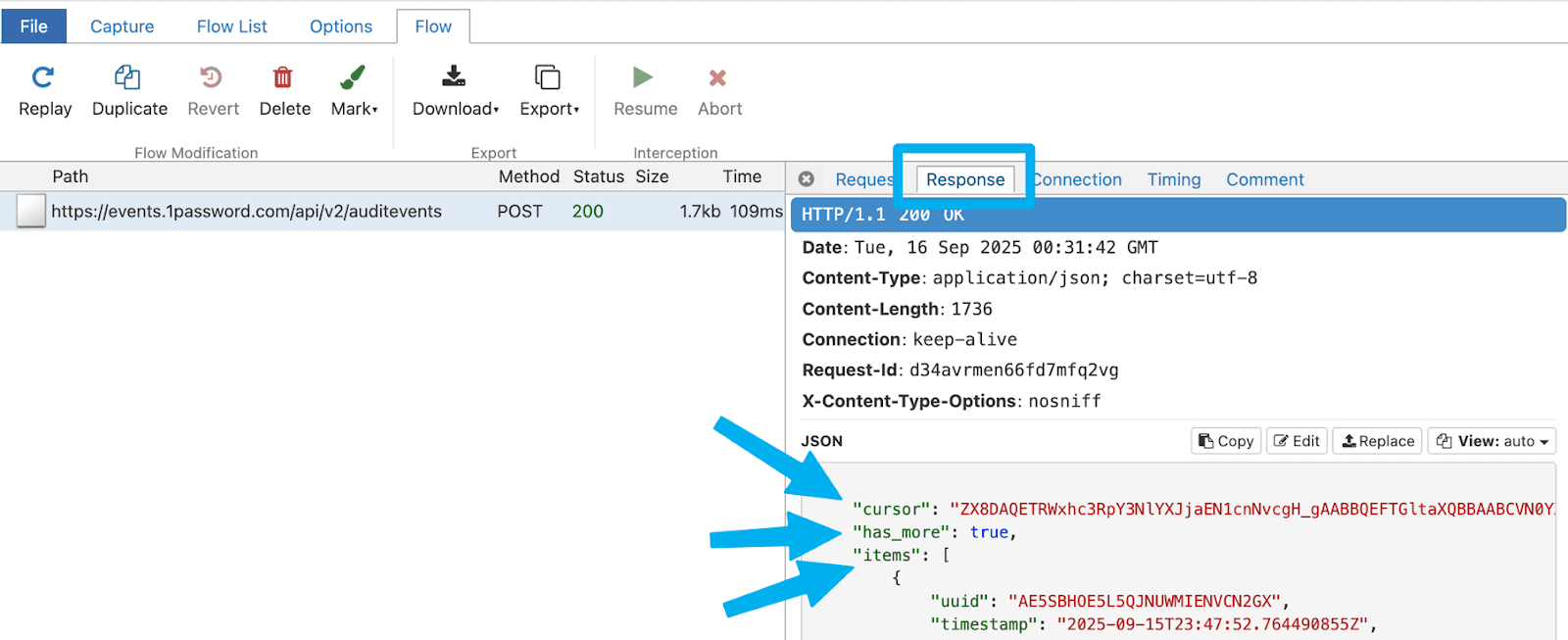
Let’s go back to our Collector config and tell it to track the response attributes from within the Response Body Framework for both “cursor” and “has_more”. We will use the value of “cursor” in each successive to tell the query where we left off and will continue to do so until the value of “has_more” equals “false” as detailed below. The tricky part is figuring how to build these values into the successive queries to get the HTML JSON object perfect.
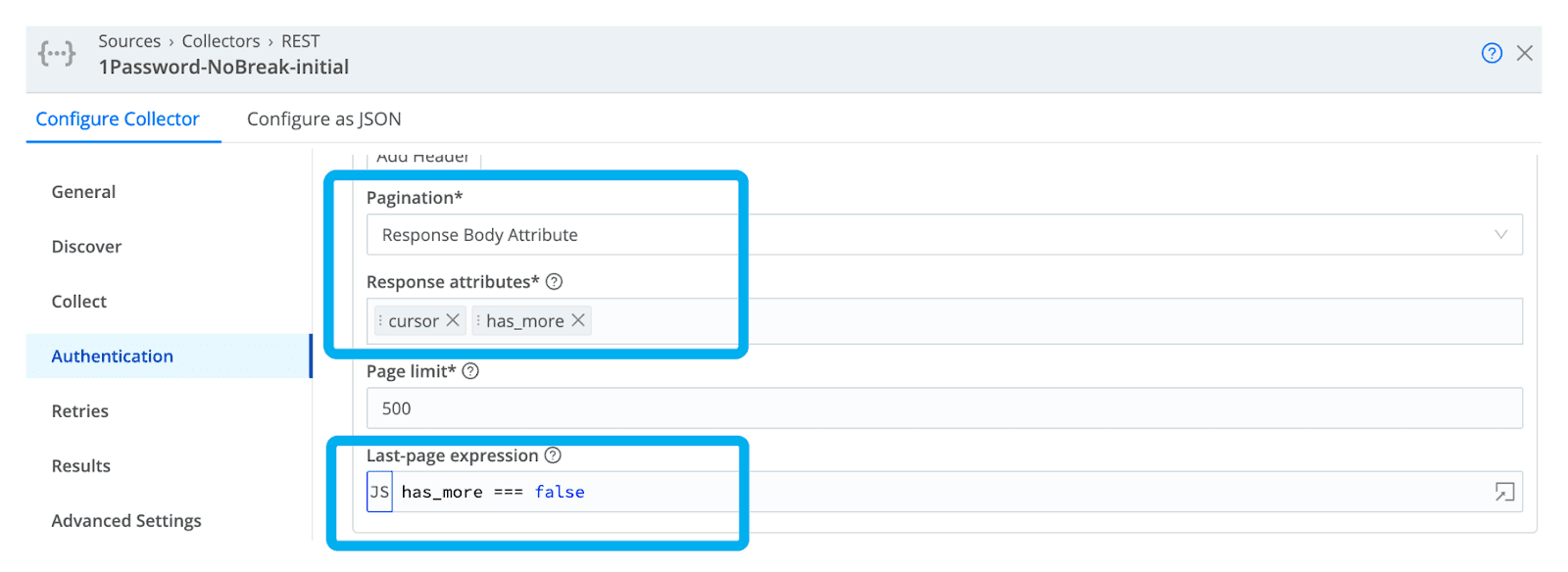
We have quite a few moving parts introduced in my updated Collect POST body below. You will notice how I am using if-then-else statements based on the presence/absence of a value for “cursor” to determine whether this is my first or successive requests. I upped the value for “limit” to make my reverse-proxy results more readable for this purpose of this blog. I’m passing the values of earliest and latest if you provide them when running or scheduling jobs. Lastly, I am passing the value of the previous “cursor” assignment for a given collector run,

When I run the collector this time (using earliest and latest to capture the previous 2 day’s worth of events, the below output from my reverse proxy confirms a properly formatted initial request, a properly formatted 2nd request passing just the “cursor” object, and the 4th response letting me know that I have reached the end of the request dataset by setting “has_more” to “false”.
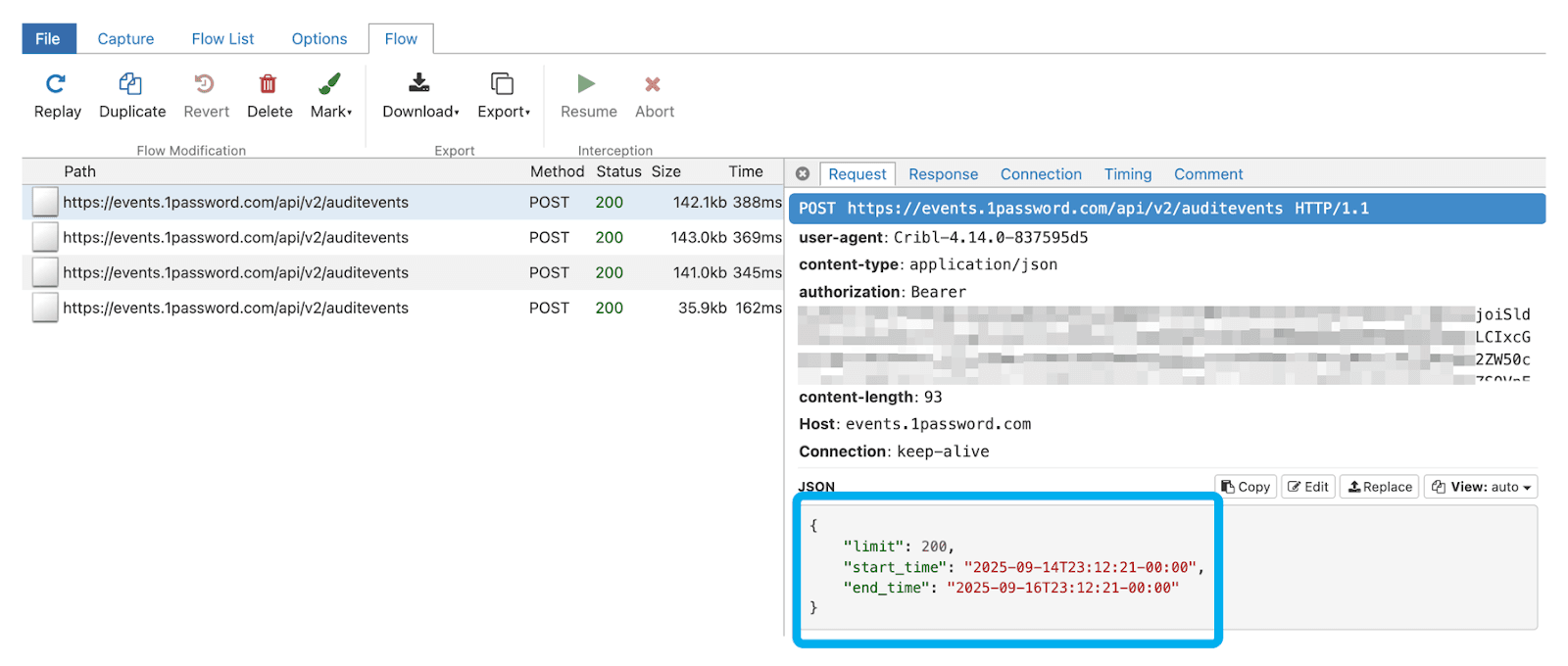
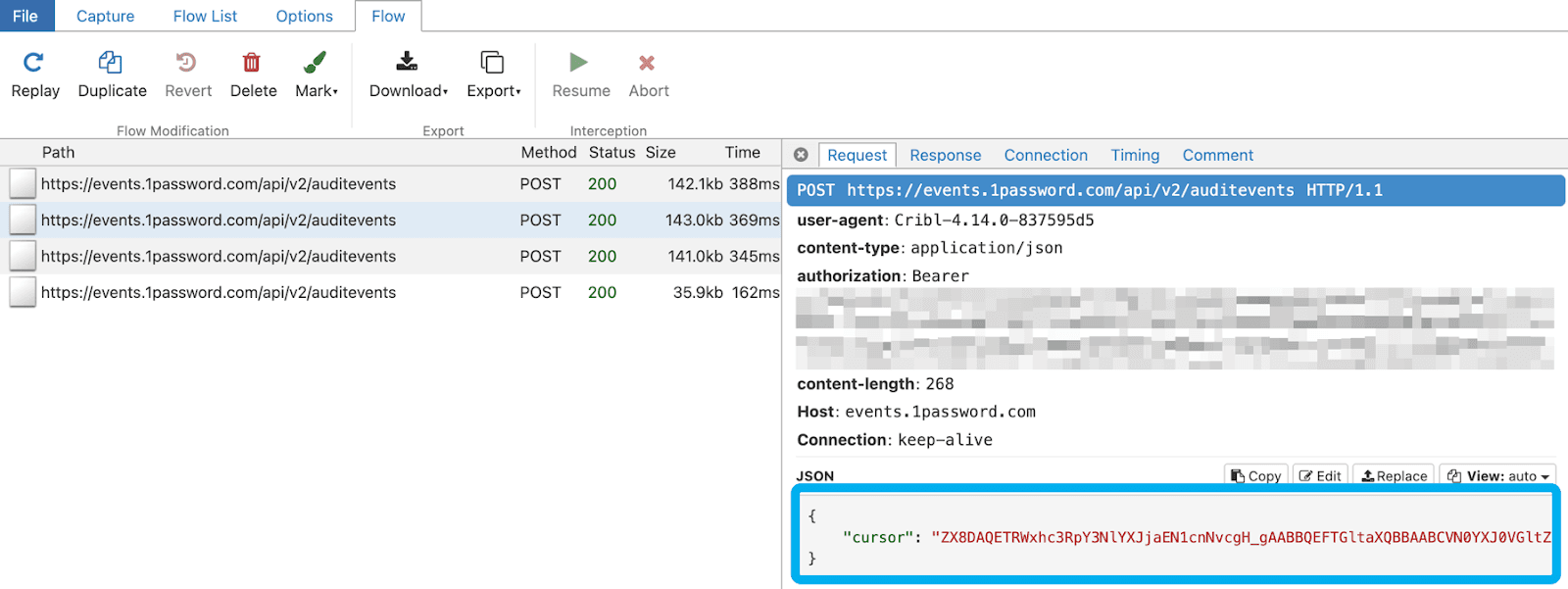
Event Breakers
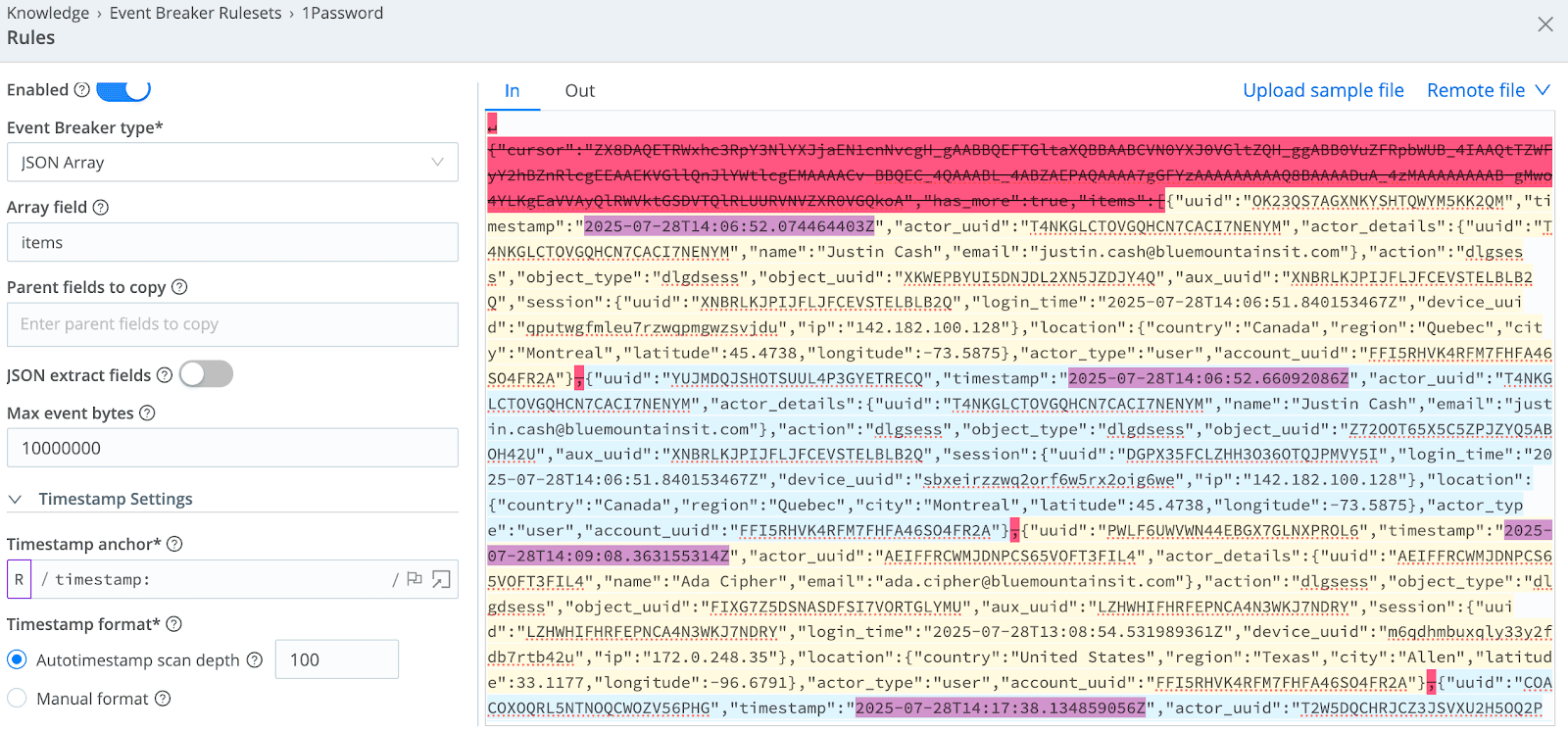
The Event Breaker strips headers from events, leaving only the records of interest and capturing timestamps properly. We want to have a single event for each unique record when using a properly configured breaker. The event breaker also needs to be configured to set the timestamp equal to the 'timestamp' field within each event for the 1Password API. There may be some vendor specific API cases where you need to select from multiple timestamps in an event depending on your use case and the event breaker will let you zero in on the timestamp you are after.
In the below event breaker, I pasted a sample 1Password response event that has not yet been broken into individual events. I assign an Event Breaker Type of “JSON Array” and assign the name of the JSON object containing the individual events/records to “items” which results in the alternating yellow/blue row colors. I use a timestamp anchor of “timestamp:” and define an auto scan depth of 100 to have Cribl Stream assign _time to the event “timestamp” object.
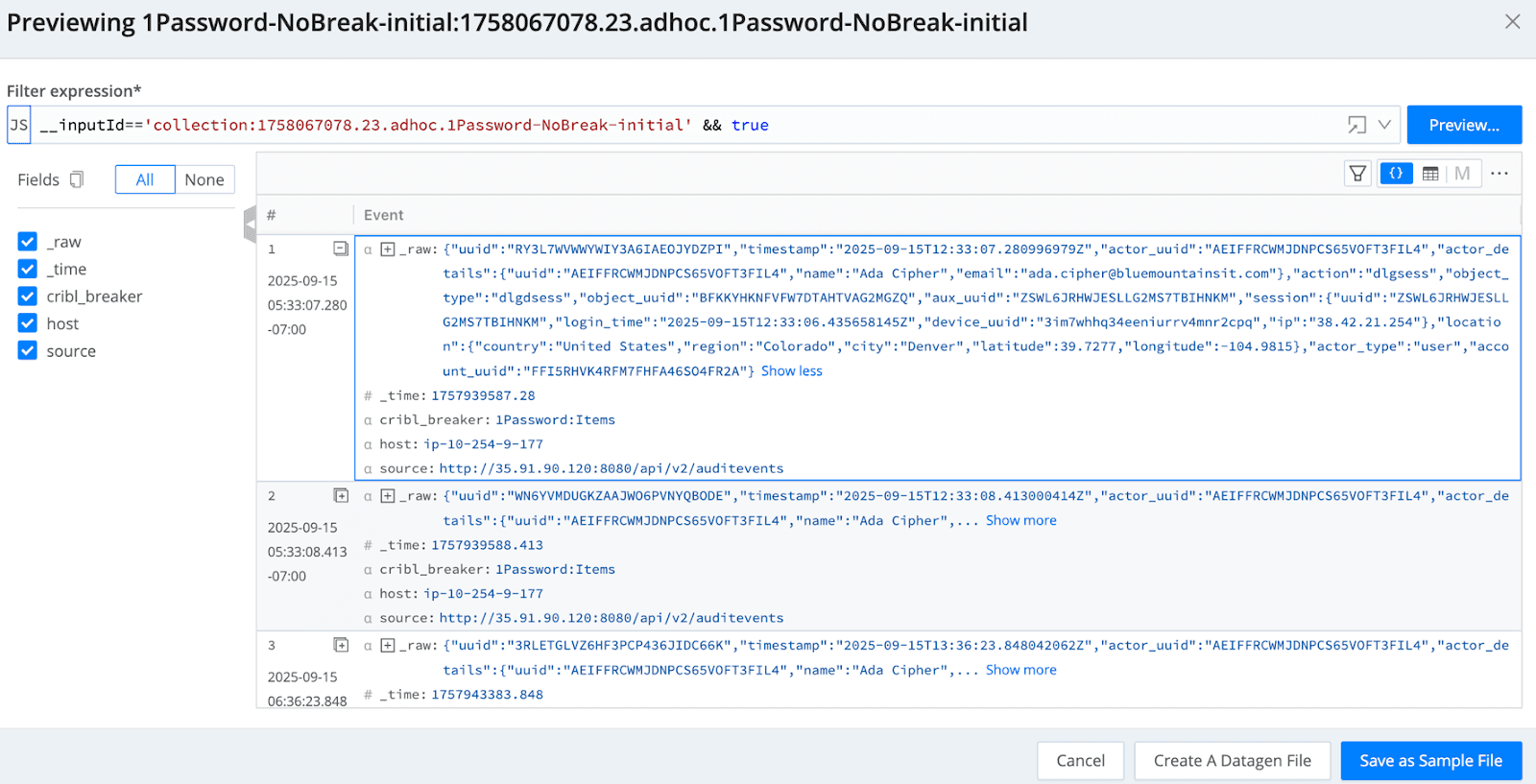
I’m getting really close to the finish line now and by assigning my new 1Password event breaker my 1Password Collector and running a job, I now see that I have the objects that were contained in the “items” array broken into individual events as detailed by a quick capture from the Collector.
Scheduling and State Tracking
Cribl Stream provides scheduling resources so your Collector jobs can be run on a recurring basis AND it also provides the ability to keep track of where the previous query left off to prevent gaps and overlaps in retrieved events.
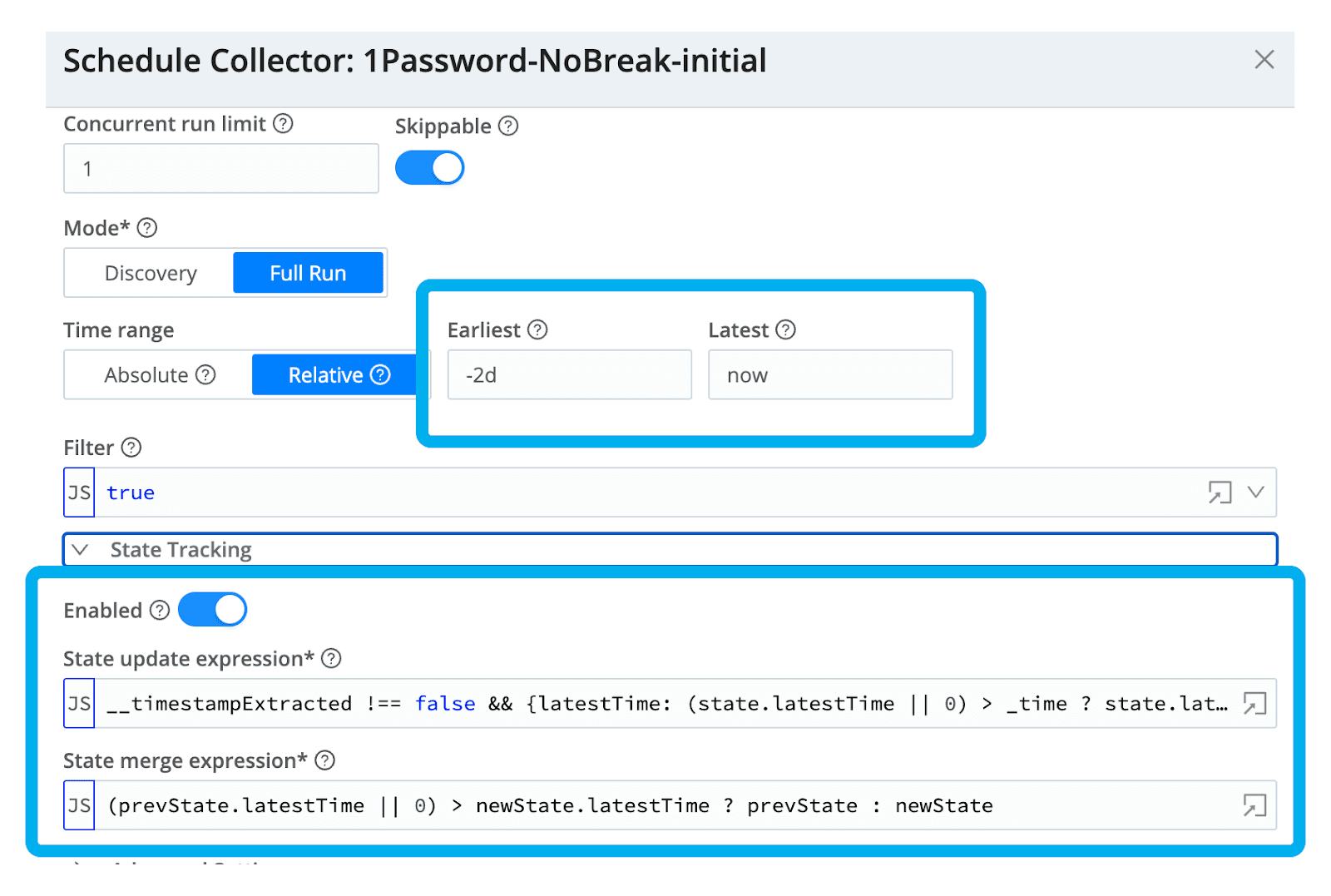
When I setup my scheduler to execute a recurring job, I want to make sure that I use the use the time of the last event from the previous job as my starting point for my next job. If this is the first time I run the job (there is no saved latest time for state tracking), we will pass the values of Earliest and Latest as highlighted below into the request. Because I carried the value from the event time stamp into my Cribl Stream _time variable, I can use the defaults for the State update expression and State merge expression as highlighted below.
Wrap Up
The completed 1Password REST Collector has been published in this Cribl repo with copy/paste instructions to get you up and running very quickly with the 1Password events API. My hope is that you feel much more comfortable centralizing the API collection of data from 3rd party best-of-breed SaaS providers or providers of context relevant to your use cases. Centralizing your efforts around Cribl Stream as a single console for managing all your API integrations is just one of the many enterprise optimizations that will help best situate you relative to your data. Check out the 1Password Marketplace listing for Cribl Stream to learn more.






