
When confidence outpaces reality
The latest research from Precisely and Drexel University's LeBow College of Business reveals a troubling paradox in enterprise data strategy: while 87–88% of data leaders claim they have the infrastructure, skills, and data readiness needed for AI success, 41–43% simultaneously cite these same elements as their biggest obstacles. This is not a measurement error—it is a confidence–reality gap that threatens billions of dollars in AI investments.
The disconnect runs deeper. Data quality is the most common data‑integrity priority, cited by 51% of leaders, yet many organizations still cannot effectively measure it, creating a cycle where teams know quality is poor but lack frameworks to quantify and fix it. At the same time, 43% identify data readiness as the top barrier to aligning AI initiatives with business objectives, and 32% expect positive ROI from AI in the next 6–11 months despite gaps in governance, skills, and foundational data practices.
For security and IT operations teams, this gap is operational. Poor data quality in observability pipelines means broken alerts, unreliable dashboards, and AI models trained on garbage. The traditional “fix it later” approach no longer works when autonomous agents and real‑time security decisions depend on data integrity.
The 2026 report defines a clear framework: Data integrity = Accuracy + Consistency + Context achieved through five interconnected disciplines:
Data quality
Data governance
Data integration
Data enrichment
Location/contextual intelligence
Most organizations understand this conceptually. The challenge is making it real for the logs, metrics, traces, and security telemetry that drive modern operations.
This post bridges theory and practice by showing how Cribl’s telemetry data engine operationalizes each pillar of the data‑integrity framework for observability data. We map the survey’s findings to concrete pipeline patterns and show why full‑fidelity storage in cost‑effective platforms like Cribl Lake—paired with search and visualization—creates both immediate operational value and a foundation for trustworthy AI.
The data integrity framework meets observability reality
The Precisely/Drexel framework translates cleanly into the language of security and IT operations:
Data quality
The report identifies data quality as the #1 integrity priority and warns that “data‑quality debt” threatens AI value. For observability, that debt shows up as messy, inconsistent logs/metrics/traces that break dashboards and AI‑driven detection, plus near‑duplicate events, bloated payloads, and schema drift that silently accumulates risk.Data governance
Governance drives trust and AI readiness: 71% of organizations with governance programs report high data trust vs. 50% without. Observability teams need centralized control over who sees what, how long it is kept, whether PII is masked, and how data can be used—without that, security and compliance risks multiply.Data integration
Thirty‑two percent of leaders cite data integration as a top challenge, and 33% point to ecosystem complexity as a major barrier. In telemetry pipelines, dozens of agents and tools that do not speak the same language, plus parallel pipelines per tool, make integration brittle and governance hard to enforce.Data enrichment
Ninety‑six percent of organizations invest in enrichment and location intelligence to add context. Raw telemetry lacks business meaning; you need metadata—service owner, criticality tier, cloud region, business unit—to separate signal from noise and enable safe automation.Location & context
Organizations using location intelligence report better decisions but struggle with privacy (46%) and integration complexity (44%). For IT/security, “location” means data center, cloud region, network segment, Kubernetes cluster, tenant ID—factors that determine whether an event is routine or a critical incident.
The report’s recommendations—strengthen governance, address data‑quality debt, add context, and invest in integration—apply as much to observability pipelines as they do to data warehouses. The question becomes: how do you actually build this for telemetry at scale?
Operationalizing data integrity with Cribl: The five pillars
Pillar 1: Data quality – Clean, consistent telemetry before it hits expensive tools
The business challenge
The report elevates “data‑quality debt” as a strategic risk built up over decades of deferred investment. In observability, that debt includes:
Near‑duplicate events consuming storage and search capacity
Bloated JSON payloads with unnecessary nested fields
Schema drift that silently breaks dashboards and alerts
Inconsistent field naming across sources (for example, src_ip vs source_ip)
Twenty‑nine percent of leaders say the inability to measure data quality is their biggest obstacle—you can’t improve what you can’t measure. AI makes this acute: models trained on flawed data simply learn those flaws, and unlike human analysts, they rarely notice when data “looks wrong.”
How Cribl addresses it
Cribl Stream and Cribl Edge act as quality‑control checkpoints, validating and normalizing data before it reaches downstream systems. In our first Stream pipeline for OpenTelemetry logs and traces, we focus on three moves: normalize, protect, and prune.
Normalize – A small Eval step promotes key OpenTelemetry attributes—service identity, message text, HTTP status, a few database fields—from deep inside resource.attributes into a consistent set of top‑level fields. After this step, every log and trace carries the same service name, namespace, version, instance ID, message, and status, regardless of language or service.
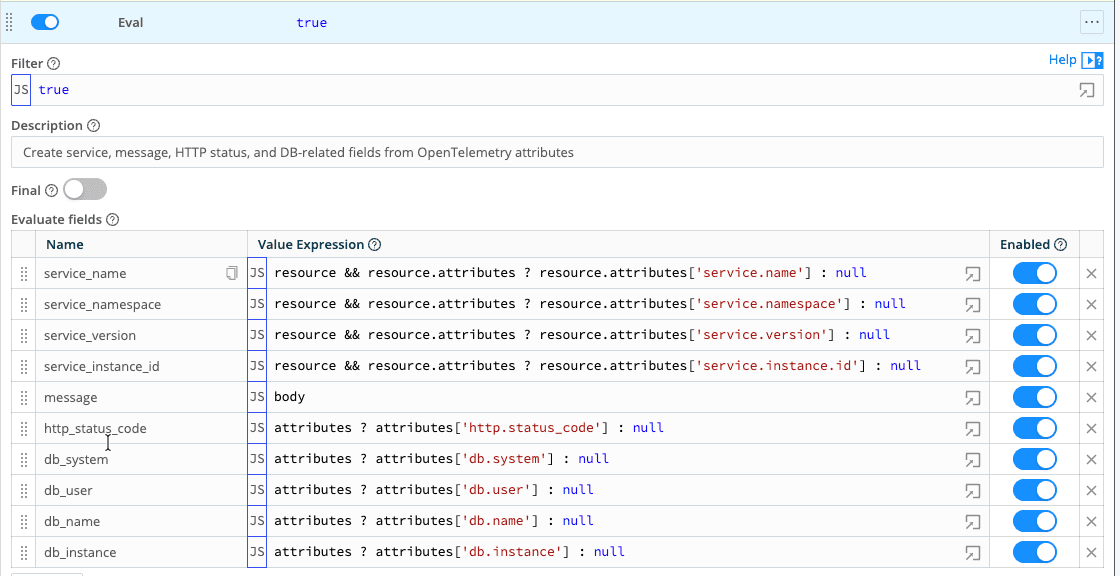
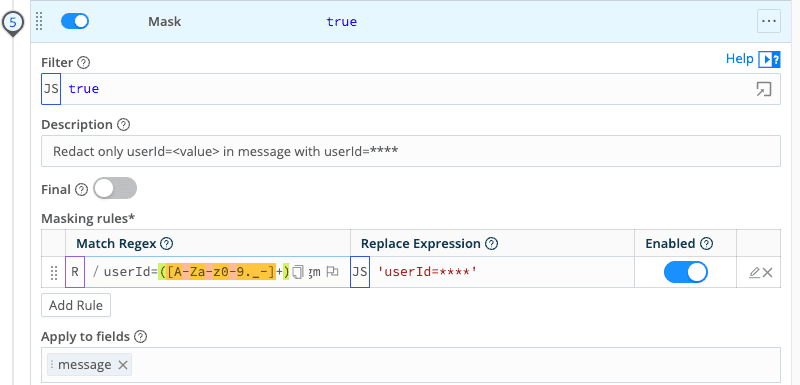
Protect – A Mask function extracts
user_idfrom the log message (where it appears asuserId=<guid>) into its own field, then redacts both theuser_idand the original username. Identifiers become safe, consistent fields that still support pattern analysis without exposing individuals.
Prune – A follow‑up Eval keeps the normalized and correlation fields (service identity, message, status, user, trace/span IDs, timing, scope metadata) and drops the nested attributes they came from. Events go from verbose and deeply nested to compact, consistent, and PII‑safe, while preserving trace context for investigations and AI analytics.
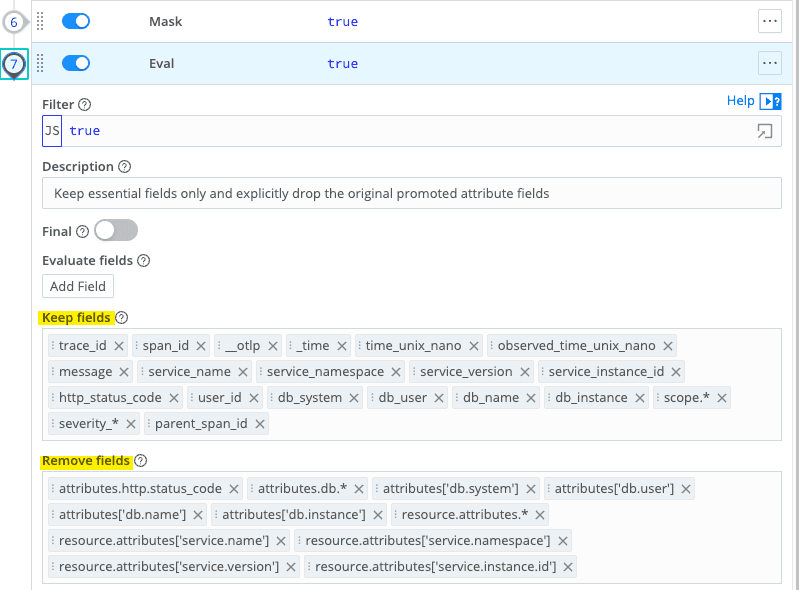
This is the data‑quality layer the report calls for: events that reach downstream tools and AI pipelines have passed basic quality checks, reducing the data‑quality debt that threatens AI ROI.
Why this matters for AI readiness
The report finds that 43% of leaders cite data readiness as the biggest barrier to AI, and much of that stems from messy, inconsistent telemetry that tools cannot rely on. Pillar 1 fixes this at the source: every event leaving Stream has a stable schema, sensible field names, and obvious PII removed, so downstream analytics and models build on trustworthy inputs instead of learning around bad data.
Pillar 2: Data governance – Cribl as the telemetry control plane
The business challenge
Data governance is a pivotal factor in AI success. Seventy‑one percent of organizations with governance programs report high trust in their data, versus 50% without. The best‑performing “Innovator” organizations extend existing governance programs to cover AI rather than creating separate, disconnected AI governance efforts.
Yet governance remains hard. Thirty‑nine percent of leaders cite governance and compliance as obstacles when aligning AI with business objectives. For observability data, challenges include:
Ensuring PII/PHI is masked before data reaches third‑party tools or AI platforms
Enforcing data‑residency requirements (for example, EU data staying in EU regions)
Controlling who can access sensitive security telemetry
Maintaining audit trails of lineage for compliance
Without a central control point, governance becomes whack‑a‑mole across tools and pipelines.
How Cribl addresses it
Cribl Stream functions as a telemetry control plane, providing five governance capabilities aligned with the report:
Availability – Central routing decisions ensure data reaches the right destinations at the right time
Usability – Normalization and enrichment make data consistent and actionable across tools
Integrity – Schema validation and conformance checks enforce data quality
Security – PII/PHI masking, field encryption, and RBAC protect sensitive data
Compliance – Audit logs, lineage, and retention policies support regulatory needs
In our OpenTelemetry deployment, we use normalized service_name and service_namespace from Pillar 1 to drive simple policies. Application telemetry arrives in Stream, which routes each signal type to the appropriate pipeline. The ai_ready_logs_traces route identifies logs and traces, sends them through the quality pipeline, then on to destinations.
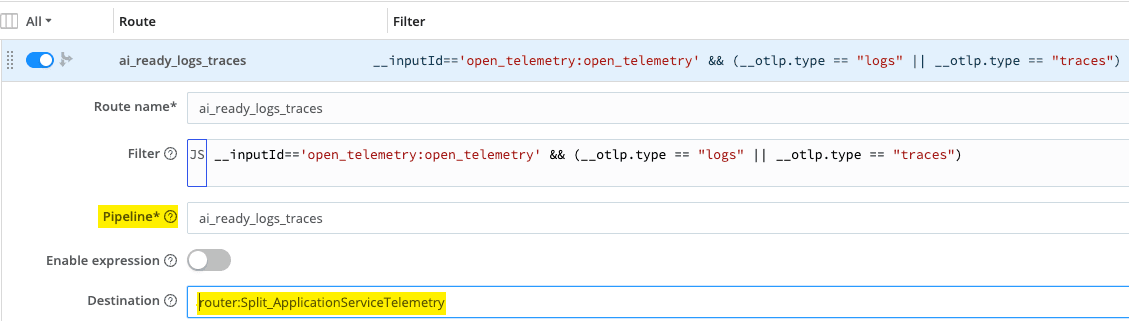
Customer‑facing services (frontend, cart, checkout, payment, product‑catalog) are treated as higher‑value and higher‑risk. Their logs and traces go to both SIEM/log analytics and Cribl Lake, with longer Lake retention for investigations and AI training.
Supporting services (adservice, load‑generator, and similar) go primarily to Cribl Lake with shorter retention; only errors or selected events reach SIEM.
Stream’s Output Router evaluates each event against ordered rules to determine destinations. In production, this pattern naturally extends to Kubernetes namespaces or clusters—prod vs dev/test—so production telemetry automatically gets stricter governance and longer retention, while non‑prod is governed but kept briefly.
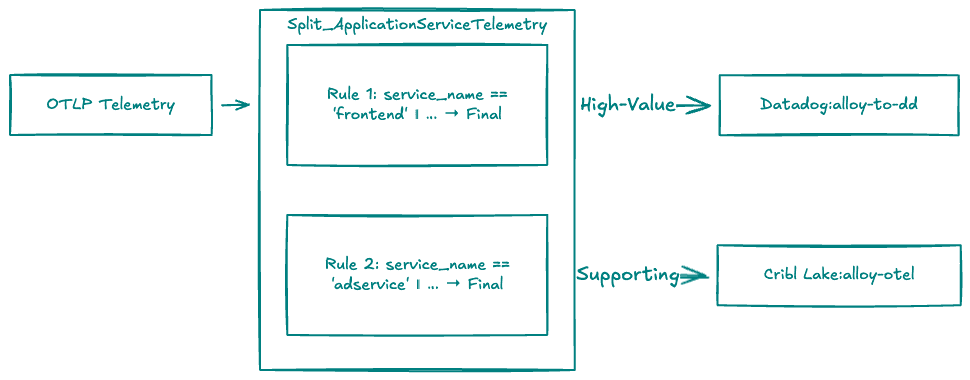
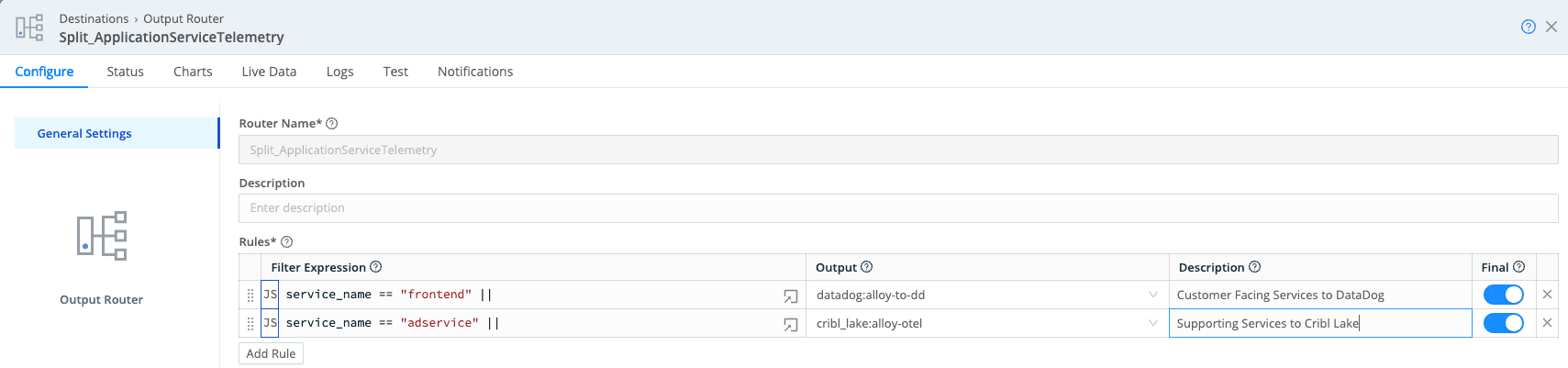
The key is that these decisions are made once, centrally, on normalized fields, and enforced consistently across all downstream tools.
Cribl Guard: Policy-driven sensitive data protection
Manual masking rules do not scale as observability data increasingly includes API tokens, customer IDs, email addresses, and credentials in headers, URLs, and trace spans. Cribl Guard provides policy‑driven sensitive‑data detection and protection, using pattern libraries and ML‑informed detection rather than hand‑crafted regex for every PII variant.
Guard enables:
Automatic PII/PHI detection across logs, metrics, and traces
Organization‑wide policy enforcement for data protection
Real‑time blocking or masking before data reaches storage or tools
Audit trails showing what sensitive data was detected and how it was handled
For organizations concerned about privacy and security when using external enrichment—46% in the report—Guard offers a control point to detect and protect sensitive data, even in enriched telemetry.
We apply Guard first where it matters most: the Datadog destination receiving high‑value logs and traces from customer‑facing services. By adding Guard as a post‑processing step, we automatically scan each event for sensitive financial data and redact it before it leaves the platform, with the option to extend the same protection to other destinations.

Attaching the Default and Financial_Global rulesets means that any event from services like payment that matches those patterns is redacted automatically.
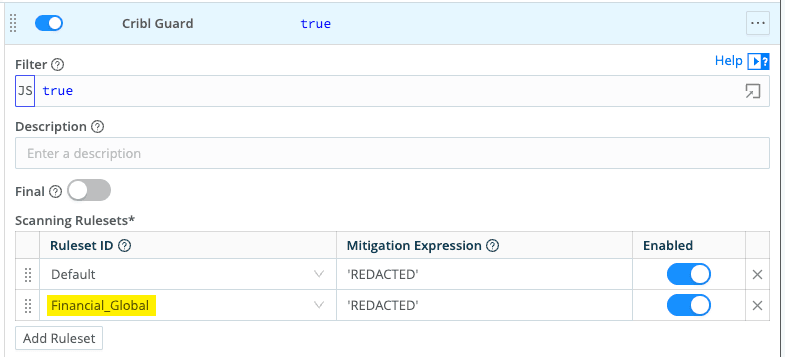
The governance payoff is significant. Organizations that invest in robust governance see double‑digit improvements in operational efficiency, revenue impact, modernization, regulatory compliance, AI value, and cost reduction—exactly the outcomes observability leaders are targeting.
Pillar 3: Data integration – Any-to-any telemetry routing with traceability
The business challenge
Data integration is both a top challenge and a key lever in the survey. Thirty‑two percent of leaders cite integration as a major issue, and 33% point to ecosystem complexity as a barrier to success. Investments in integration consistently yield the largest improvements in data quality.
For observability teams, this complexity is acute:
Tool sprawl: SIEM, APM, log analytics, data lakes, AI platforms, each with proprietary agents and formats
Parallel pipelines: separate collection and transformation flows for each tool
Format incompatibility: one tool wants syslog, another JSON, a third OTLP
Brittle architectures: changing a source or destination means touching multiple systems
In this environment, you cannot enforce consistent masking or enrichment if every tool owns its own pipeline.
How Cribl addresses it
Cribl Stream acts as a universal integration layer for observability data, providing “any source to any destination” routing with consistent transformation and governance:
Unified ingestion – Accept syslog, OTLP, Splunk HEC, HTTP/S, Kafka, cloud provider APIs, and more
Format conversion – Transform between formats at line speed (syslog → JSON, JSON → Parquet, proprietary → OTLP)
Smart routing – Send high‑value events to expensive SIEM, medium‑value to data lake, low‑value to cold storage or drop
Lineage and traceability – Track origin and transformation path of every event for compliance and debugging
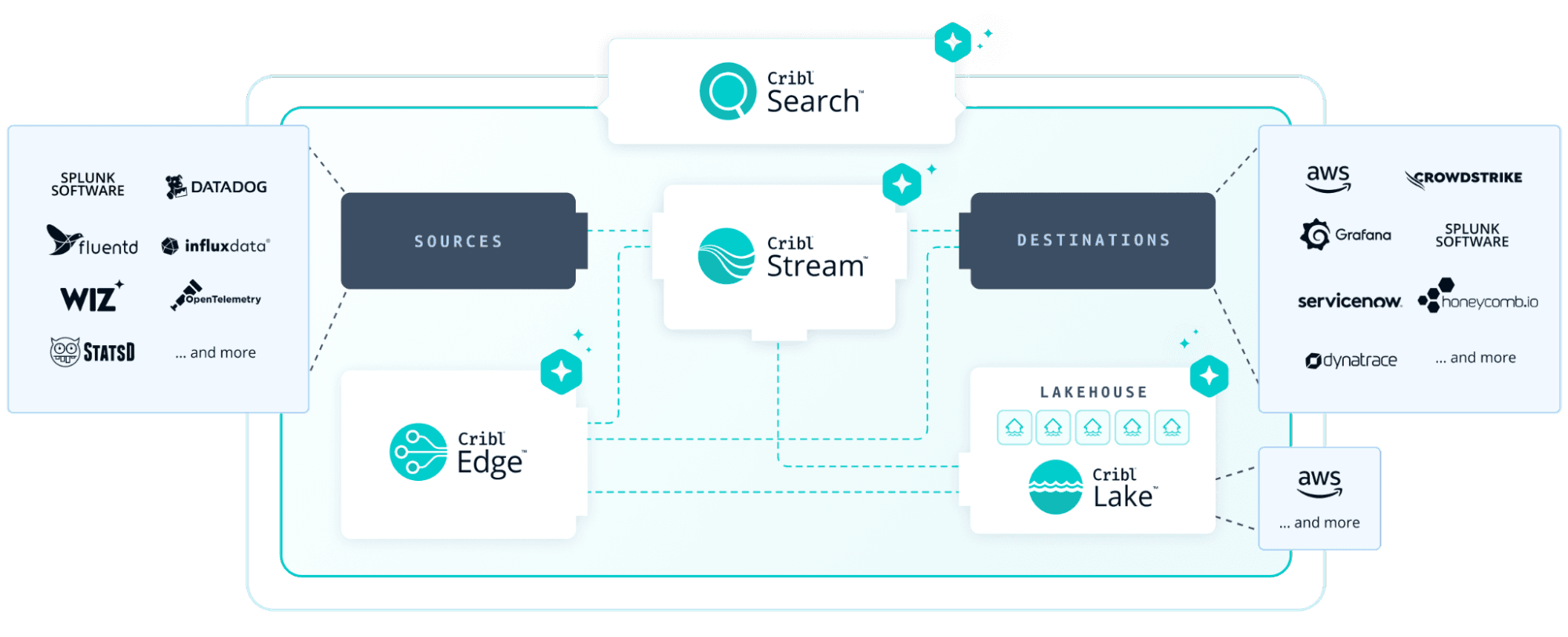
In practice, Stream sits in the middle as a shared integration layer, taking data from any source (syslog, OTLP, cloud logs, agents) and routing it to any destination (SIEM, Cribl Lake, APM, AI platforms) through a single, governed pipeline set.
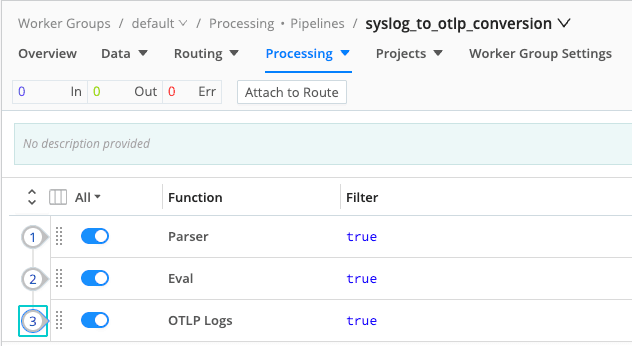
One simple example: a pipeline that takes legacy syslog and converts it into the same OpenTelemetry log format as app telemetry. A Parser turns raw syslog lines into structured fields, and a small Eval plus OTLP Logs function wraps those fields in the standard OTLP schema. “Old” log sources can now flow through the same governed pipelines and AI‑ready data model as modern telemetry.
This strategy delivers:
Reduced total cost of ownership – one pipeline instead of N
Faster time‑to‑value – adding a destination is a configuration change, not a new deployment
Enforceable governance – masking, enrichment, and routing rules apply consistently
Operational resilience – buffering and failover prevent data loss when destinations are unavailable
The survey’s finding that integration investments yield the strongest quality improvements matches field experience: consolidating integration logic is what makes systematic quality checks, governance rules, and enrichment actually sustainable.
Pillar 4: Data enrichment and context – Turning raw telemetry into AI-ready signals
The business challenge
The 2026 report emphasizes that context is a competitive edge. Ninety‑six percent of organizations invest in enrichment and location intelligence, but many struggle to operationalize it safely and consistently. For business analytics, enrichment means adding demographics, geospatial attributes, and third‑party data. For observability and security, context takes different but equally critical forms:
Asset context – production database or dev sandbox; critical or low‑priority
Business context – which business unit, service, or customer the system supports
Environmental context – data center, cloud region, cluster, or network segment
Threat context – known‑malicious IPs, recently compromised accounts
Without this context, telemetry is noise. A failed login could be a user typo or a brute‑force attack; the raw event looks the same.
How Cribl addresses it
Cribl provides enrichment capabilities across the data lifecycle:
Source‑level tagging – add environment, business unit, and criticality at collection time
Pipeline enrichment – look up context from CMDBs, asset inventories, and threat‑intel feeds
Metadata injection – add routing and access‑control tags that downstream tools can leverage
Conformance checking – use Cribl Search to detect schema changes, oversize events, or missing fields
At collection time we stamp each event with environment, business unit, and criticality tier so downstream tools and AI can immediately distinguish a tier‑1 production payments service from a low‑risk background job. By the time events reach Datadog, that context travels with them: a payment transaction log now includes env: production, biz_unit: payments, and criticality: tier 1, allowing dashboards, alerts, and models to prioritize issues affecting high‑value services.
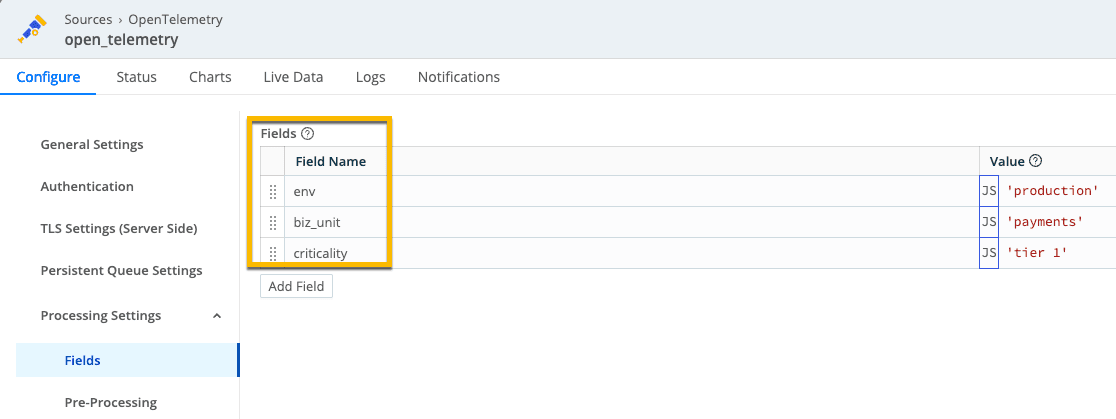
By the time events reach Datadog, that context travels with them: a payment transaction log now includes env: production, biz_unit: payments, and criticality: tier 1, allowing dashboards, alerts, and models to prioritize issues affecting high‑value services.

The Lookup runs alongside quality and masking functions, turning clean, governed telemetry from Pillars 1 and 2 into enriched, AI‑ready signals that tools can route and prioritize based on business impact, not just log severity. The resulting events expose asset_owner, risk_tier, and compliance_scope as first‑class fields.
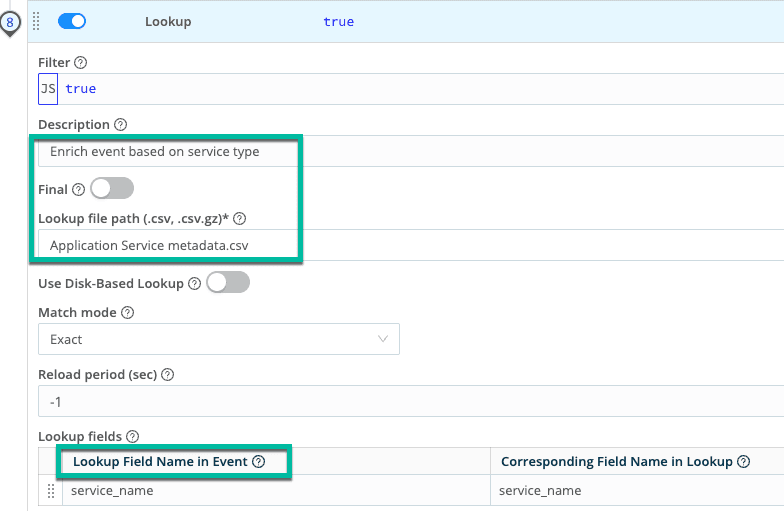
The enriched event now shows asset_owner, risk_tier, and compliance_scope as first‑class fields, giving analysts and AI models an immediate view of who owns the service, how critical it is, and which regulatory obligations apply—directly operationalizing Pillar 4’s promise of context‑rich telemetry.
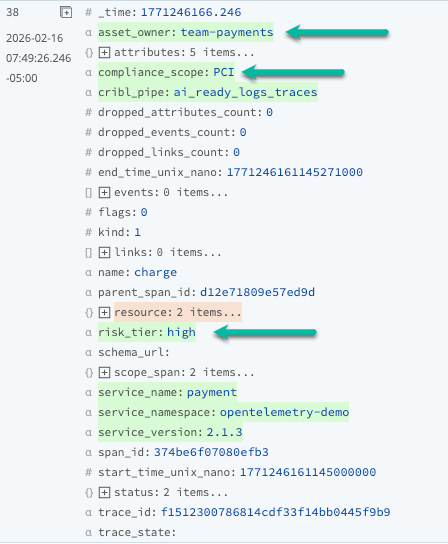
Enrichment is not just about adding fields; it is about enabling better decisions downstream:
Smarter routing – high‑criticality events go to SIEM; low‑criticality to cheaper storage
Faster investigations – analysts see business context in every event without manual joins
Better AI outcomes – models trained on enriched data learn business‑relevant patterns, not just technical correlations
Governance automation – tags enable policies like “PCI logs visible only to the compliance team”
The report notes that organizations using location intelligence and third‑party enrichment struggle with privacy and integration challenges. Cribl addresses both by enriching data in‑stream with governance controls (masking before enrichment, audited lookups) and centralizing enrichment logic so it happens once, consistently.
Why this matters for AI readiness
Clean data alone is not enough; the survey highlights that context and location intelligence are where organizations expect the biggest lift from AI investments. Pillar 4 is where we add that business and risk context—owners, tiers, compliance scope—so AI does not just flag anomalies, it understands which ones touch high‑value services, regulated workloads, or low‑risk background jobs. This is where we move from raw “logs” to governed signals that can safely drive automation and AI.
Pillar 5: Full‑fidelity storage and Search – Seeing risk in your raw telemetry
The Precisely/Drexel survey calls out a painful tradeoff: enterprises need complete, high‑quality data for AI, but cannot afford to keep everything in premium tools. Pillar 5 breaks that tradeoff. By streaming enriched telemetry into Cribl Lake, we keep the full‑fidelity record—including the business fields added in Pillar 4—at object‑storage economics, then use Cribl Search to explore it on demand and assemble AI training datasets without another round of data wrangling.
In practice, we stand up a “Data Integrity Pipeline Observations” dashboard directly in Cribl Search, using Lake as the engine instead of pushing everything into another backend. The focus is not node CPU; it is the risk profile of our telemetry estate: how much of today’s data comes from high‑risk services, which asset owners are generating the signals that will train models, and whether critical workloads like the payment service are consistently represented. Because the dashboard runs on enriched, Lake‑resident telemetry, we gain this clarity without paying hot‑tier prices for every metric and log we might someday need.
The Risk Tier Volume Over Time view shows how much telemetry we have from high‑, medium‑, and low‑risk services, using the
risk_tiertags attached earlier. It answers a basic question the report says many teams struggle with: what level of risk does our current telemetry actually represent?—now directly from raw events rather than a separate inventory spreadsheet.The Events by Asset Owner panel turns Lake into a live view of who owns the data feeding AI initiatives. Because each event carries
asset_owner, we can see that team‑commerce generates the bulk of current telemetry, with smaller streams from engineering, marketing, and payments—making it easy to pull in the right stakeholders when tuning pipelines or preparing training datasets.The High Risk Tier: Payment Service trend focuses on the most critical service. By filtering to events where
risk_tier == "high"andservice_name == "payment", we show that even after downstream tools roll data off, Lake retains a complete time‑series view of enriched payment events—the history needed for investigations, model training, and answering “what really happened?” weeks later.
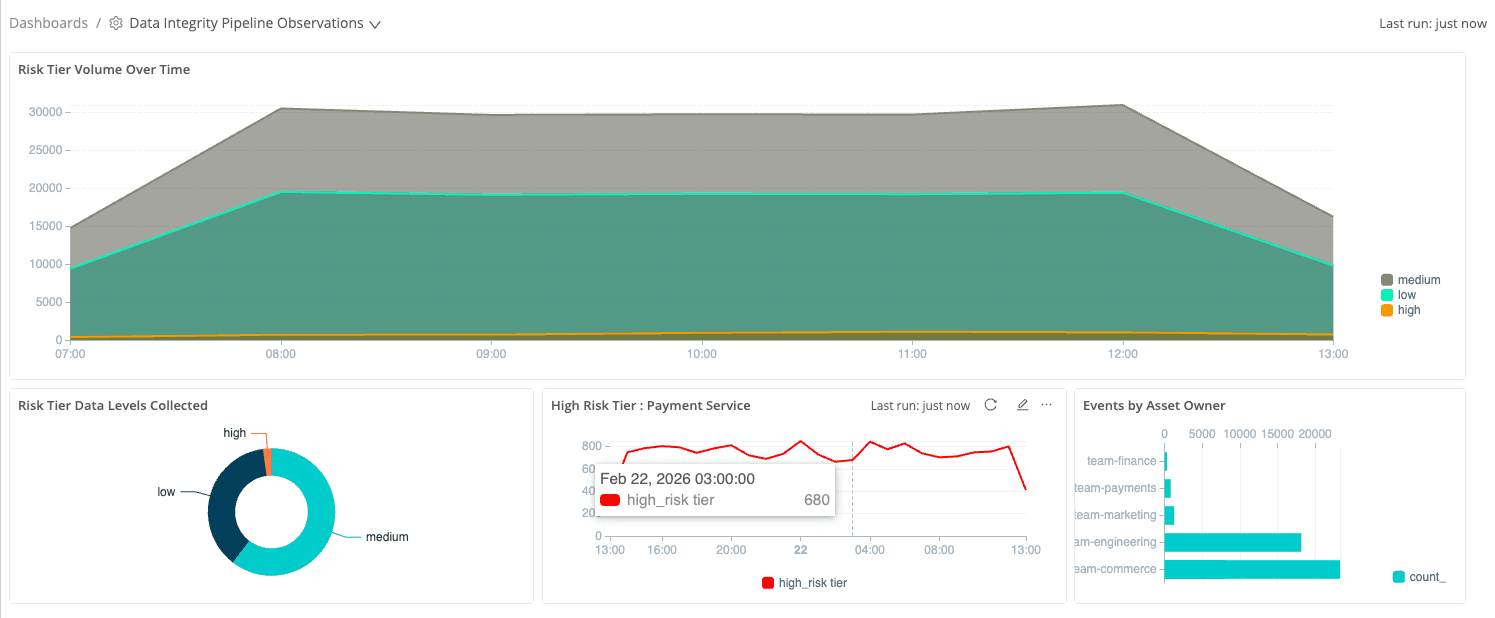
Together, these views show what Pillar 5 is really about: you are not just storing more data, you are keeping context‑rich telemetry that can be sliced by risk, owner, and service long after it leaves the hot path. Cribl Lake and Cribl Search turn stored exhaust into a durable asset for today’s operations and tomorrow’s AI projects, narrowing the gap the survey highlights between confidence in AI readiness and underlying data reality.
Measuring impact: Cribl Insights for data integrity visibility
The 2026 report highlights a critical problem: 29% of leaders cite the inability to measure data quality as their biggest obstacle to achieving high-quality data. You can't improve what you can't measure, and most organizations lack frameworks to quantify the effectiveness of their governance and integration investments.
For platform teams implementing the data integrity pillars with Cribl, this measurement gap creates a business challenge: how do you demonstrate ROI to the people funding governance and integration work, and prove that the pipelines you’ve built are actually reducing data quality debt, enforcing governance policies, and preparing data for AI.
Ultimately, the goal of applying the data integrity framework to observability is not just to move data more efficiently, but to make its value visible and provable: cleaner events, governed flows, and context‑rich telemetry that teams can trust when they train models or automate decisions. When platform teams can point to concrete evidence that pipelines are reducing quality debt, enforcing policy, and keeping AI‑ready data both usable and affordable, the gap between confidence and reality that the 2026 report highlights starts to narrow.
For additional information—including a deeper walkthrough of “observing your observability” with Cribl Insights and System Insights—please see the companion paper linked here.
References
Anandarajan, M., & Precisely. (2026). 2026 State of Data Integrity and AI Readiness: Findings from a survey of global data and analytics leaders. Drexel University LeBow College of Business Center for Applied AI and Business Analytics. https://www.lebow.drexel.edu/sites/default/files/2026-01/lebow-precisely-state-data-integrity-ai-readiness-2026.pdf
Cribl. (2025). What is data governance and why it matters for telemetry. Cribl Blog. https://cribl.io/blog/what-is-data-governance-and-why-it-matters-for-telemetry/