
What is tiered storage and why do you need it?
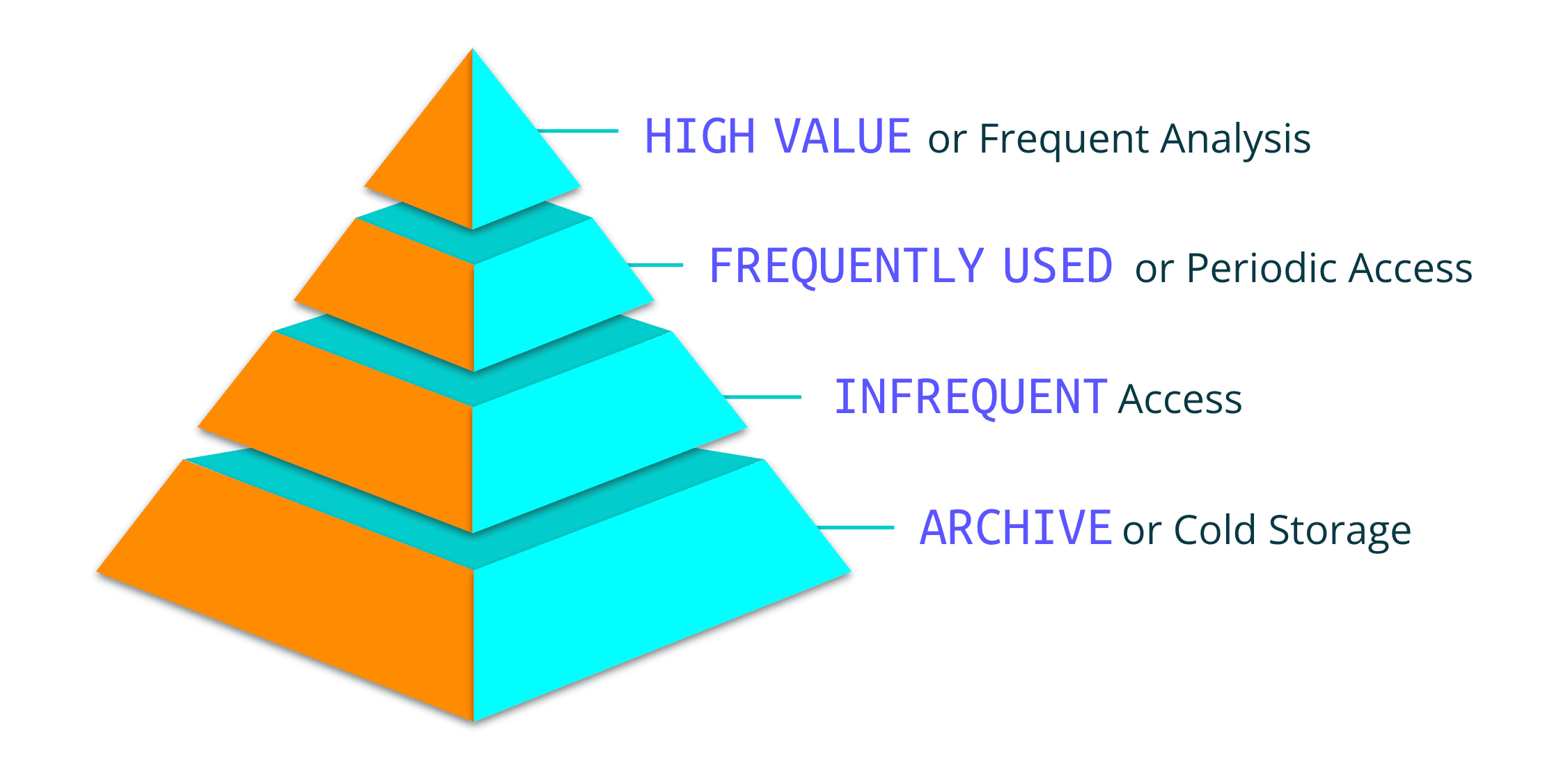
Tiered storage assigns data to different storage classes based on its value, usage, and access requirements. To understand why that matters, consider volume, variety, and value. Data varies widely in type, format, and structure and should be treated accordingly. That is not just a security or governance concern; it is a practical part of a data strategy. Data also varies in value. For real-time alerting, its worth may evaporate in minutes. For compliance and incident investigation, it may only become valuable months or years from now. The key is identifying your data types and their potential value, then matching each to the right storage class for your IT and security teams.
Why do data needs vary across teams?
The value of data depends on who needs it and when. SecOps teams need real-time data to alert them to issues; data that is days or even hours old is useless for responding to an active event. ITOps teams may need hours, days, months, or years of data for trend analysis or compliance. Data value is a function of age, accessibility, and volume, and of who is interacting with it. Some low-volume, real-time data can become critical evidence a month later.
The scale of the challenge is growing. Telemetry data is expanding at roughly 29% per year, effectively doubling every 18 months, according to Cribl's analysis of industry data (Cribl, 2025). That growth is outpacing the budgets meant to manage it.
And now a message from your sponsor
Cribl, built on the Data Engine for IT and Security, helps organizations change their data strategy. Cribl's products are a vendor-agnostic data management solution capable of collecting data from many sources, processing billions of events per second, routing data for optimized storage, and analyzing data in place. With Cribl, IT and security teams get the choice, control, and flexibility to adapt to changing data needs. Cribl's offerings beyond Lake, including Stream, Edge, and Search, are available as discrete products or as a combined solution.
How does tiered data management work?
Tiered data management balances cost and complexity. As organizations grapple with mounting IT and security data, many have adopted strategies that move data into storage based on timeliness requirements for operational versus exploratory use cases, while accounting for regulatory and compliance retention needs. This approach uses legacy tools, cloud data warehouses, lakehouses, and data lakes to store and analyze data according to its value, usage patterns, and retention requirements. There is no single answer that fits every case.
Cribl's data engine provides automated, flexible data tiering, letting you align where data is stored with how it is valued and used. Performance-optimized data flows to analytics, monitoring, and cybersecurity tools in the form each platform requires.
Maintaining full-fidelity datasets matters as much as cost-optimized storage. Full-fidelity data is often required for exploratory work and compliance, and tiering places it in the right location for its intended use. Coupled with distributed access and governance built into the data engine, every tier remains accessible no matter where the data lives.
Why consider a tiered data structure?
If you are still dumping everything into your SIEM, your budget may be unsustainable. If you are filtering or sampling data to fit a license limit, you might be missing important signals. And if you are moving SIEM overflow into cold storage to save money, rehydrating that data can be difficult.
Start with one question: where does your full-fidelity data go? Process it through a pipeline for better management and cost control, so only critical, actionable data reaches your SIEM or analysis system. Then structure the rest by usage and value. Infrequently accessed data needs an archive with real-time visibility and access, without long rehydration delays. Needle-in-the-haystack searches require high-speed, columnar storage for analytics, dashboards, and real-time queries. Audit and reporting data needs affordable, retrievable storage. That is what Lakehouse provides: a storage architecture for telemetry data management over the next decade, whether you use Cribl's products or another vendor.
Cribl's Lakehouse pairs a high-speed query engine with the cost savings of object storage, so teams get instant queries without vendor lock-in or unnecessary storage costs. It can reduce costs by 50% compared to traditional solutions while routing and storing data in the optimal format (Cribl, 2025).
What are the five reasons to implement a tiered data strategy?
Store data based on value, usage, and access needs. Reduce costs and keep data available by routing high-value, frequently accessed data to performance-optimized tiers for real-time analytics, and keep less critical or exploratory data in cost-effective storage.
Use open formats to unify data. Create a single source of truth across tiers by consolidating fragmented data, so analysis can run without unnecessary duplication or movement between systems.
Prioritize flexible and scalable data analysis. Combine on-demand compute with cost-effective storage to analyze large data volumes without continuous infrastructure expansion.
Use cost-effective storage to meet compliance and audit requirements. Store full-fidelity data in low-cost object storage for long-term retention, and retrieve and replay data as audits and investigations arise.
Reduce tool proliferation and complexity. Consolidate security and observability platforms to reduce reliance on specialized tools, minimize skill set fragmentation, and simplify the data lifecycle.
How Cribl can help with tiered data storage
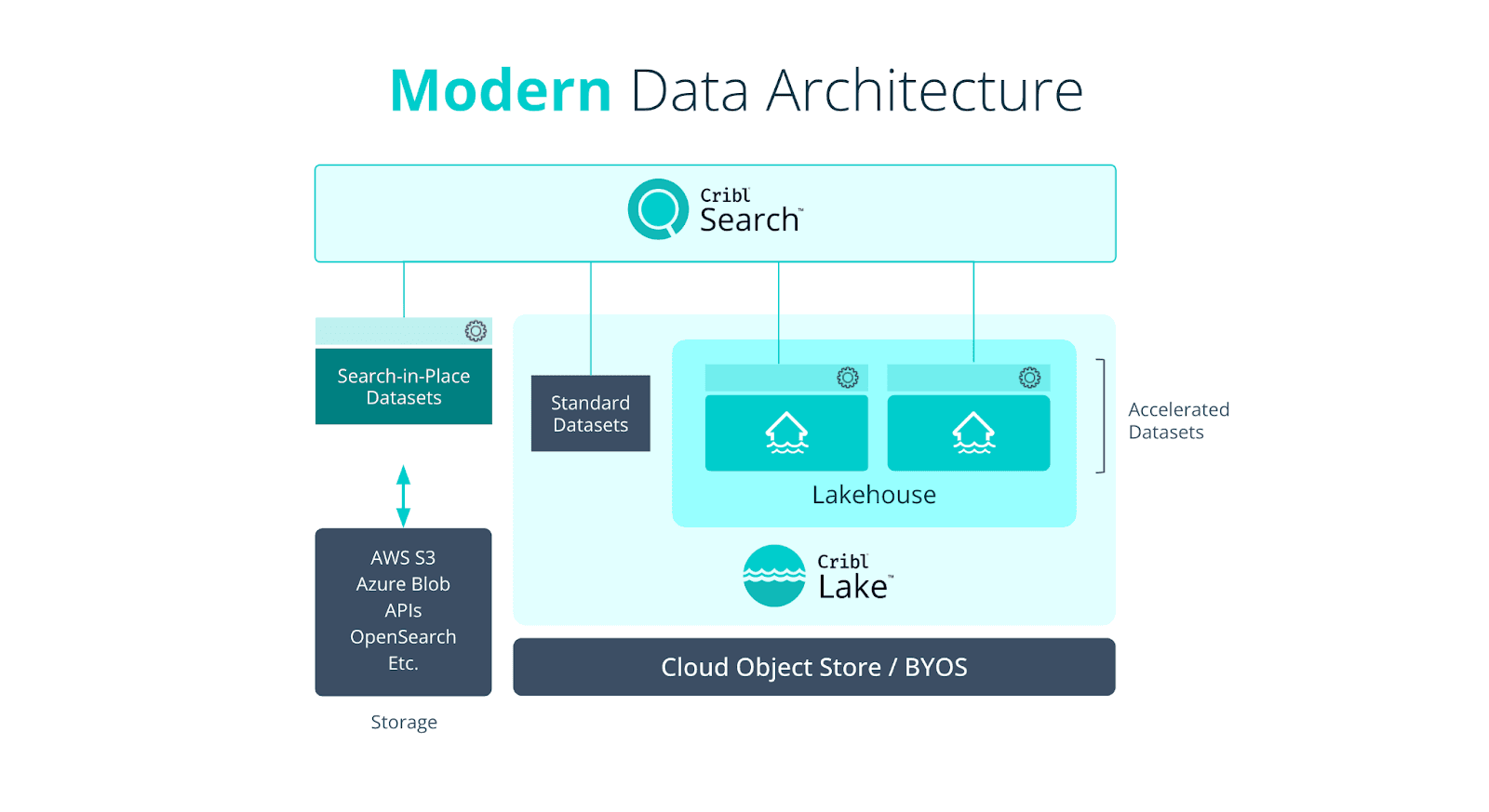
Cribl provides tools to manage and analyze telemetry with no lock-in, no data loss, and no added agents. Cribl is used by many large organizations, including half of the Fortune 100. Cribl's architecture acts as a central hub that reduces data volume and complexity, cuts costs, accelerates SIEM migrations, and supports compliance without disrupting existing systems. Stream handles real-time processing and routing, Edge collects at the source, Search performs federated queries across tiers, and Lake, with Lakehouse, provides tiered data lake storage that aligns cost with value automatically.
Because Cribl separates compute from storage and stores data in open formats, you can onboard new tools, migrate platforms, or promote historical data into fast tiers without lock-in or data loss. Every byte remains accessible, whether it is powering a real-time dashboard today or an audit two years from now.
To see tiered storage in action, create a free Cribl.Cloud account, explore a sandbox, or schedule a demo, and turn your raw telemetry into actionable information.
How do you get started with Lakehouse?
Existing Cribl.Cloud user: https://docs.cribl.io/lake/lakehouse/
New to Cribl.Cloud: https://cribl.cloud/signup/?utm_medium=website&utm_source=direct&utm_campaign=cribl-io
Try a sandbox: https://sandbox.cribl.io/course/overview-lake or https://sandbox.cribl.io/course/overview-search
Product details and webinar: https://cribl.io/products/lake/ and https://cribl.io/webinars/lakehouse/
Free training: https://cribl.io/university/
Tiered Storage: A Data Strategy FAQs
What is tiered data storage?
Tiered data storage is a strategy that places data in different storage classes based on its value, usage patterns, and access needs. High-value, frequently accessed data is stored in performance tiers for real-time analytics, while less critical or infrequently accessed data is kept in cost-effective object storage.
Why do I need a tiered data strategy for telemetry?
Telemetry data is growing approximately 29% per year, which doubles data volume about every 18 months. Sending everything to your SIEM is unsustainable, and moving aged data to cold storage makes retrieval difficult. Tiering aligns storage cost with data value, so you keep visibility without exceeding your budget.
What is Cribl Lakehouse?
Cribl Lakehouse is a feature of Cribl Lake designed for telemetry data. It has a high-speed query engine and uses object storage to reduce costs. It supports fast searches on recent data, automates tiered storage, and manages data without a fixed schema or vendor lock-in.
How is Cribl Lake different from traditional cold storage?
Traditional cold storage is cheap but slow, and rehydrating data for an investigation takes time. Cribl Lake keeps full-fidelity data accessible and searchable across tiers, so you can investigate archived data without rehydration delays. With Lakehouse acceleration, queries target the fastest available source.
How do I decide which data goes in which tier?
Start with Volume, Variety, and Value. Route critical, frequently accessed data to performance tiers for real-time alerting and dashboards. Keep exploratory, compliance, and audit data in low-cost storage where it remains retrievable and can be replayed for audits or investigations.
How can I get started with Cribl Lakehouse?
Existing Cribl.Cloud users can enable Lakehouse acceleration on a Cribl Lake dataset with a few clicks. New users can sign up for a free Cribl.Cloud account, explore the Cribl Lake Sandbox, or take free training through Cribl University.






