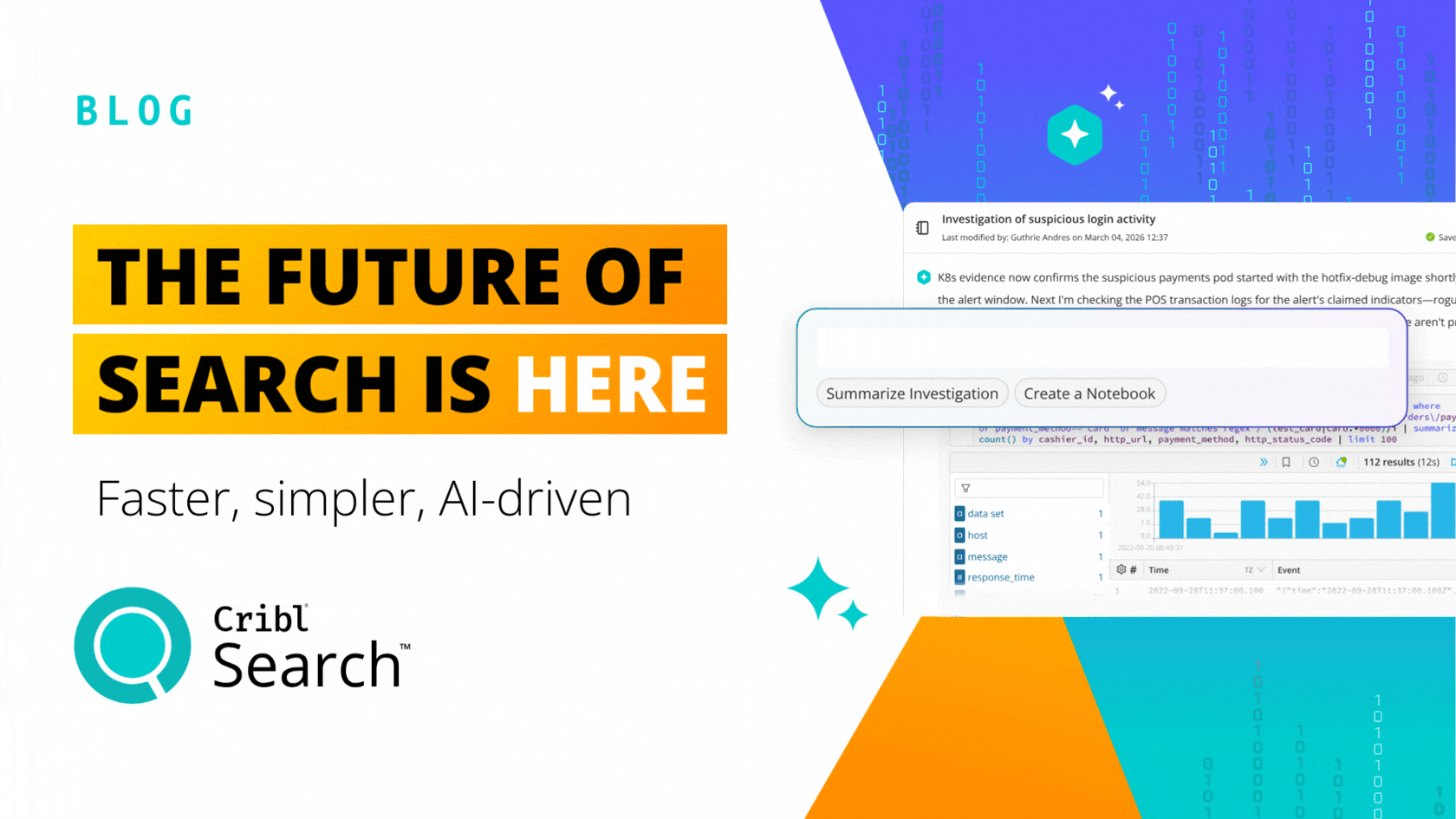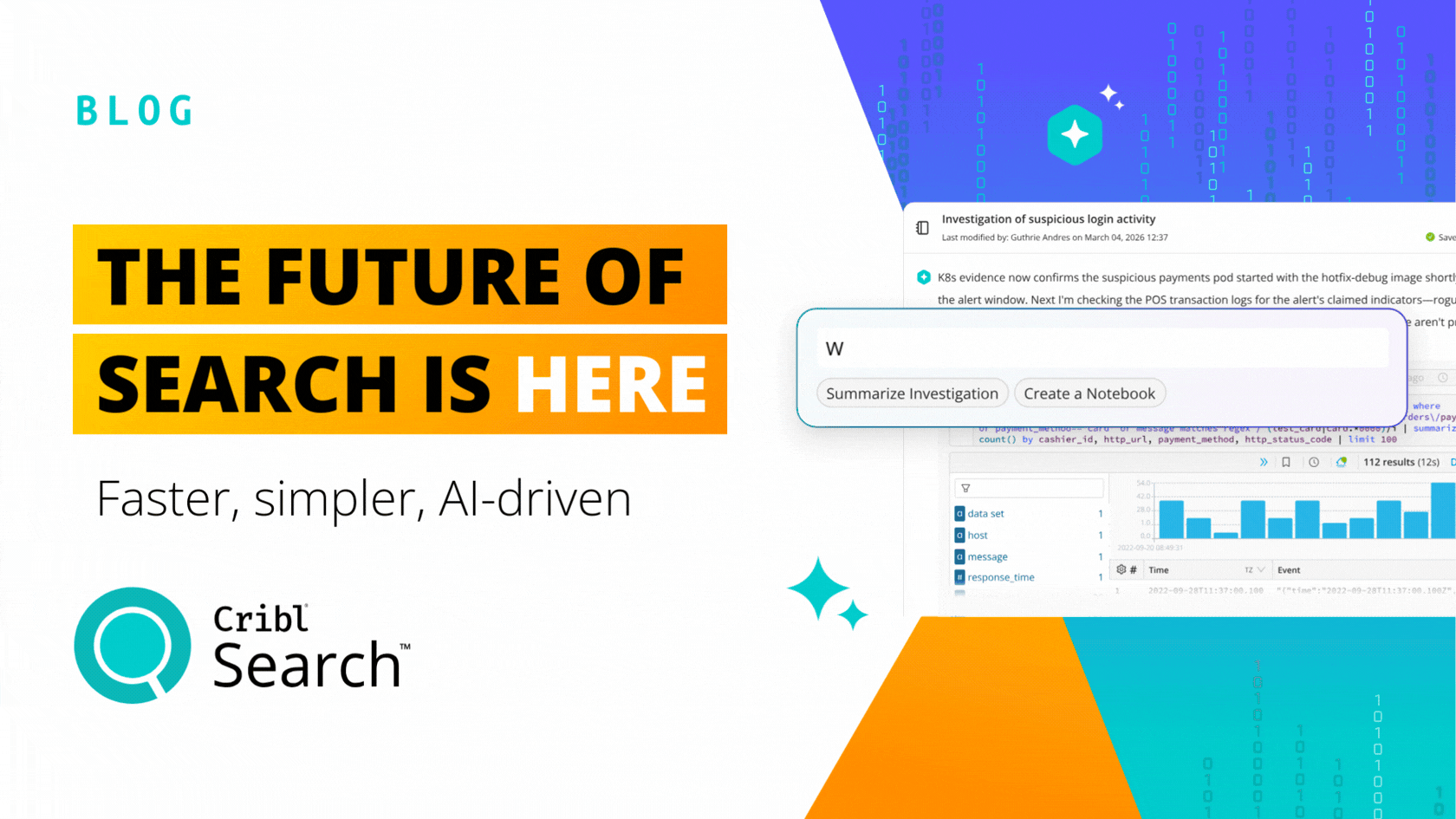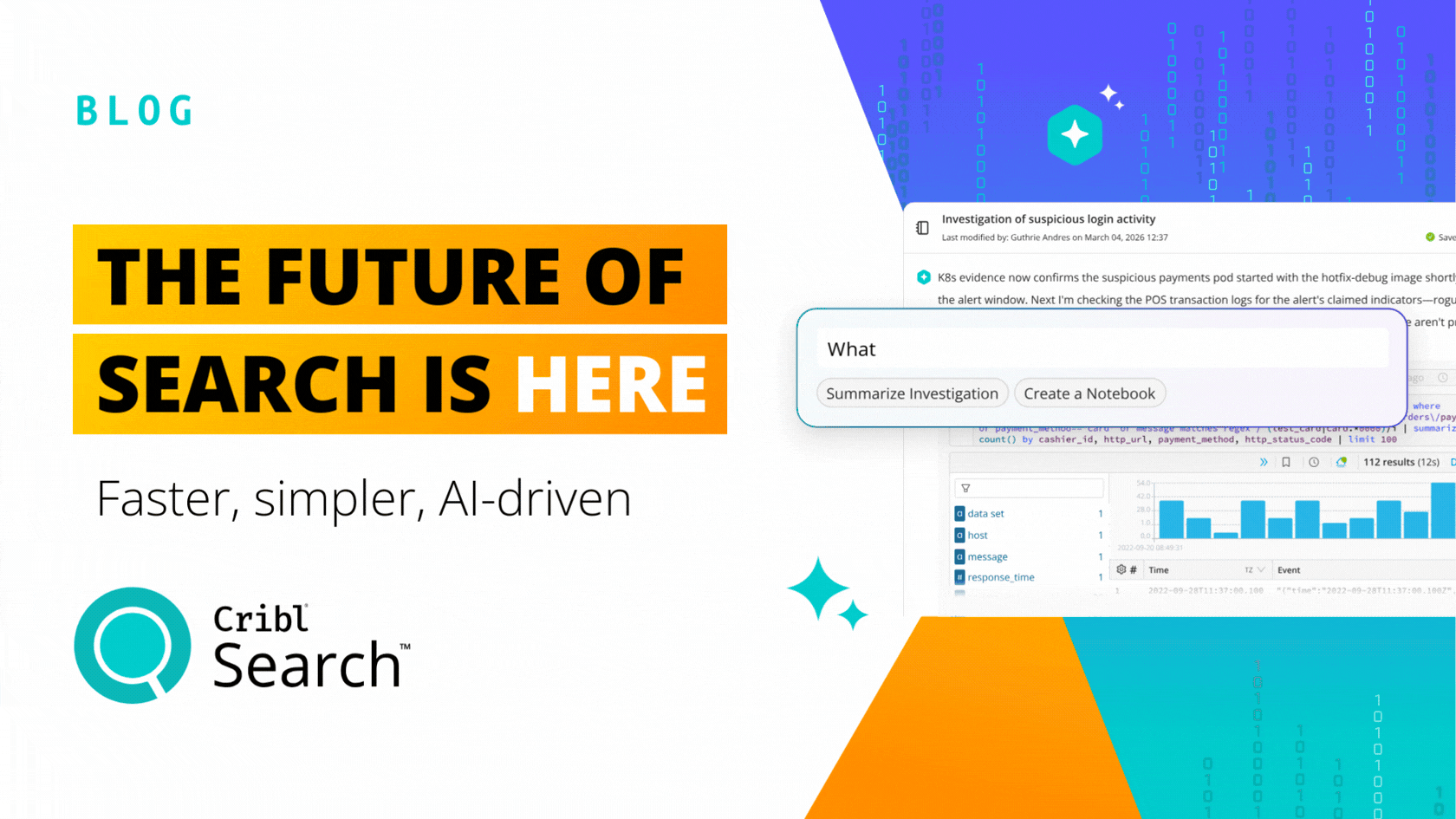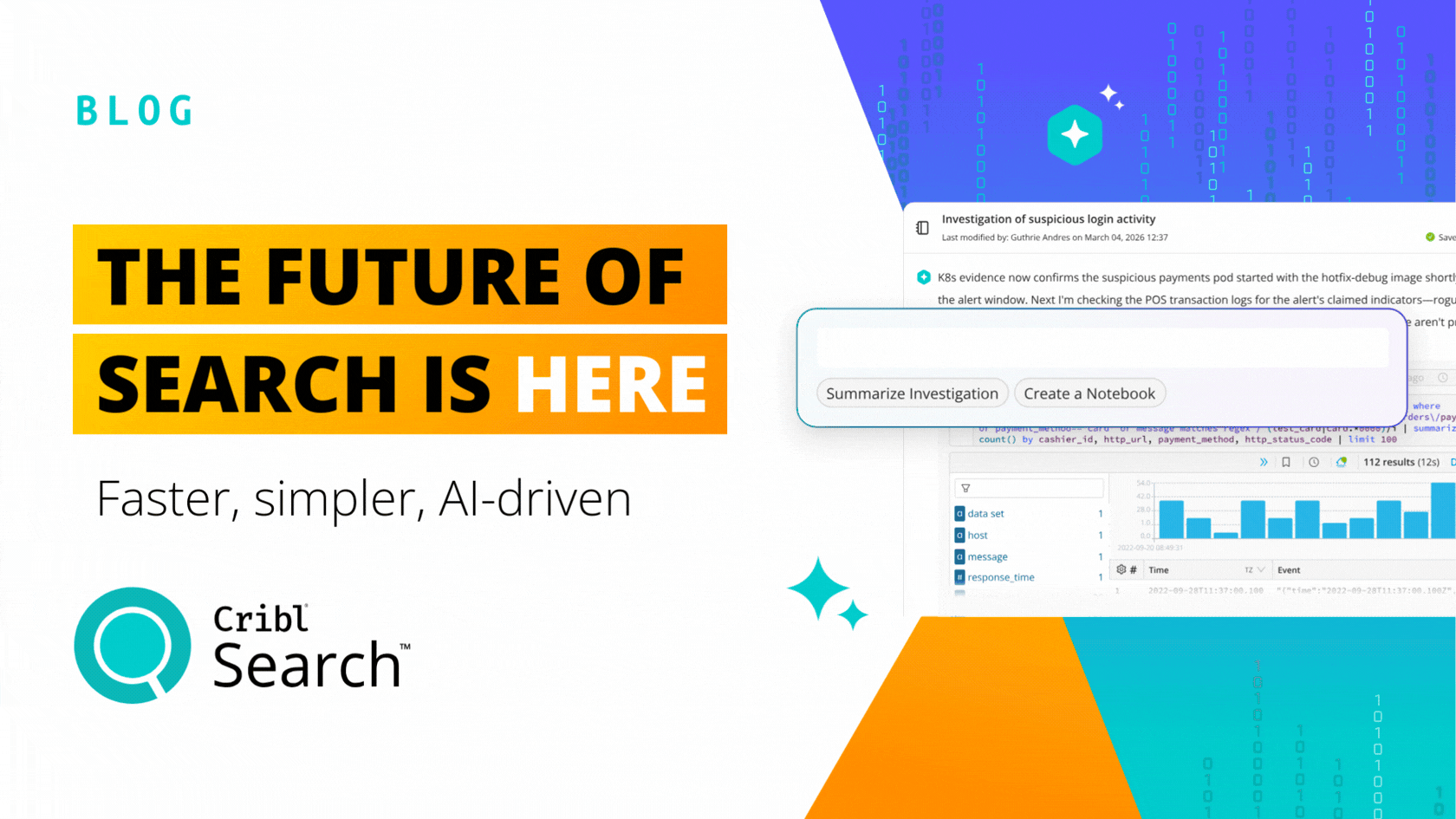
Living the Stream
Your source for observability pipelines, big data analytics, data streaming, Cribl product news, industry insights, and beyond.

get started
See demos by use case, by yourself or with one of our team.
Get hands-on with a Sandbox or guided Cloud Trial.
Process up to 1TB/day, no license required.