
If you’re heading up a centralized logging outfit, you already know the lay of the land.
Logs are growing faster than budgets. Every app team wants their data managed their way. Security teams have a mandate to retain all data for extended periods for compliance and a responsibility to ensure no PII exposure. Observability teams need context and full visibility across the architecture. And Finance must ensure that tool costs remain within budget.
This guide examines the people, process, and tooling decisions that move centralized logging from a bottleneck into a shared platform that unlocks value across the entire organization.

Why centralized logging is no easy ride
Most organizations didn't architect their way into centralized logging. It accumulated.
Developers log however they want because they need to debug quickly. Security and operations teams need logs standardized, retained, and governed. Finance wants all of that to cost less this quarter than last. The team sitting in the middle — usually in IT operations or an observability practice — ends up absorbing the friction from all sides.
These teams own shared services for collecting logs, metrics, and events from internal applications, infrastructure and cloud platforms, and the growing list of SaaS tools and security products the business runs on. Their job is to get that data to SIEMs, observability platforms, data lakes, and compliance archives — without blowing up cost, risk, or performance in the process.
The tensions don't go away. They just need to be managed better.
Developer teams want to ship code, see their logs in production, and troubleshoot without waiting on another team. Log plumbing is not their job and SIEM licensing is not their concern.
Security leaders want complete, governed data. They care about coverage, fidelity, and compliance. They worry about PII landing in the wrong place and about logging gaps during incidents.
IT operations needs logs to support uptime, incident response, and audits — while keeping infrastructure costs manageable. They're usually measured on stability and spend, not features shipped.
When traditional logging stacks grow up in this environment, central teams often become the only ones allowed to touch core pipelines, the team everyone blames when onboarding takes weeks, and the single point of failure when something downstream breaks. That's how you get shadow logging: app teams standing up their own agents and tools on the side because the official path feels too slow.
Where the trail starts
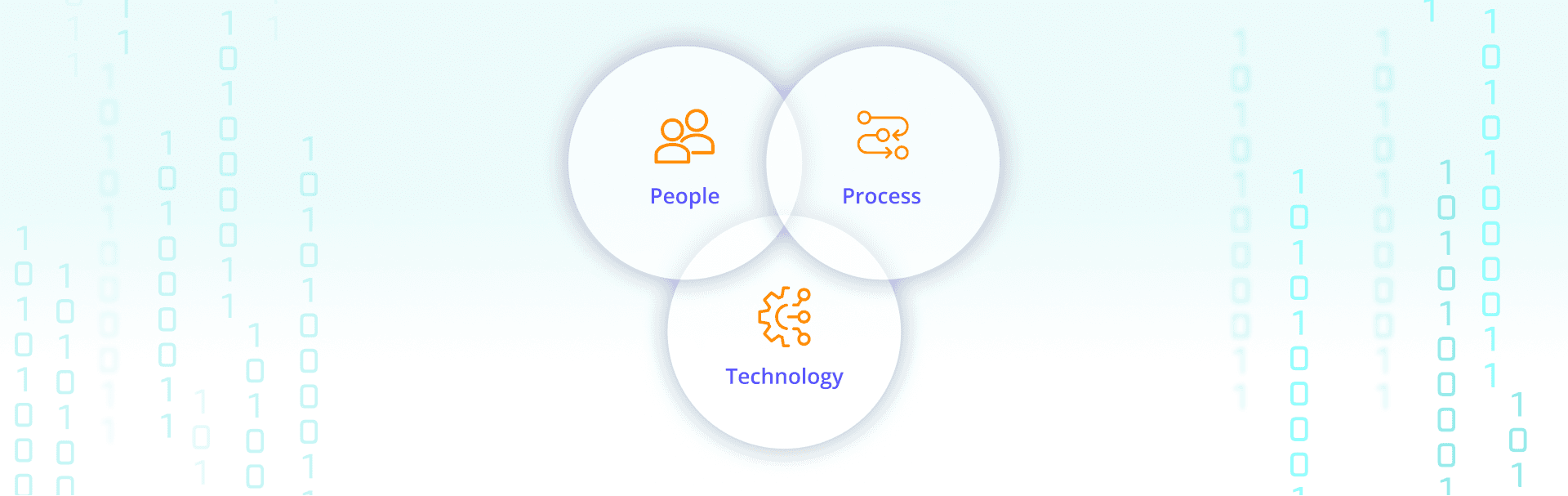
There’s a saying in IT - “a fool with a tool is still a fool.” Layering a new tool on top of a broken process doesn't fix it, in fact it more often only exacerbates the problem, leaving you still doing a lot of manual work. But process docs nobody reads don't help either. What actually works is getting the people, the process, and the technology pointed at the same goal.
People: Shared objectives
Start by getting the right people in agreement on a few things that often go unstated:
App teams should spend their time shipping and running services, not reverse-engineering logging rules. They do need clear guardrails, but those guardrails should be easy to follow. IT operations and observability teams need enough structure to keep logging reliable and affordable across the whole estate. Security and compliance need confidence that sensitive data is handled correctly.
A useful frame: everyone gets what they need, but nobody gets it for free. App teams can have special cases, but special cases take work on their side too.
What this looks like in practice
Vodafone
Analytics and Autonomics Center of Excellence
The engineering lead for Vodafone's internal COE runs operational data across applications, infrastructure, and services. They use Cribl Stream to route, deduplicate, parse, and restructure data before it reaches analytics platforms, and offer pre-built design patterns and rulesets so internal customers onboard faster with consistent structure.
"I can provide a full data platform to customers, give them free rein, but I still have control; I can provide best practices as plug and play."
The result: reduced onboarding friction for new data sources and license headroom to bring in more data without blowing the budget.
Process: Make the right thing the easy thing
Once you have basic agreement on goals, “just enough” process does more than elaborate policy. That means standard ways to request new sources or destinations, a small set of well-documented "paved road" patterns, and a simple intake process that sets clear expectations on timelines and responsibilities.
The goal isn't bureaucracy. It's predictability. Every team should know how to onboard a new app, what formats and fields are expected, where their logs will show up, and how to ask for something that doesn't fit the standard path. Done well, that replaces one-off meetings and long email threads with reusable patterns.
Technology: Serve the people, automate the process
The technology layer needs to collect from whatever developers and vendors throw at it, apply shared rules for parsing, enrichment, redaction, and routing, support multiple tools and destinations without rebuilding pipelines for each one, and give central teams visibility without locking everyone into a single vendor.
The key shift is treating logging as a shared service with standard interfaces, not a monolithic stack where every change requires a ticket.
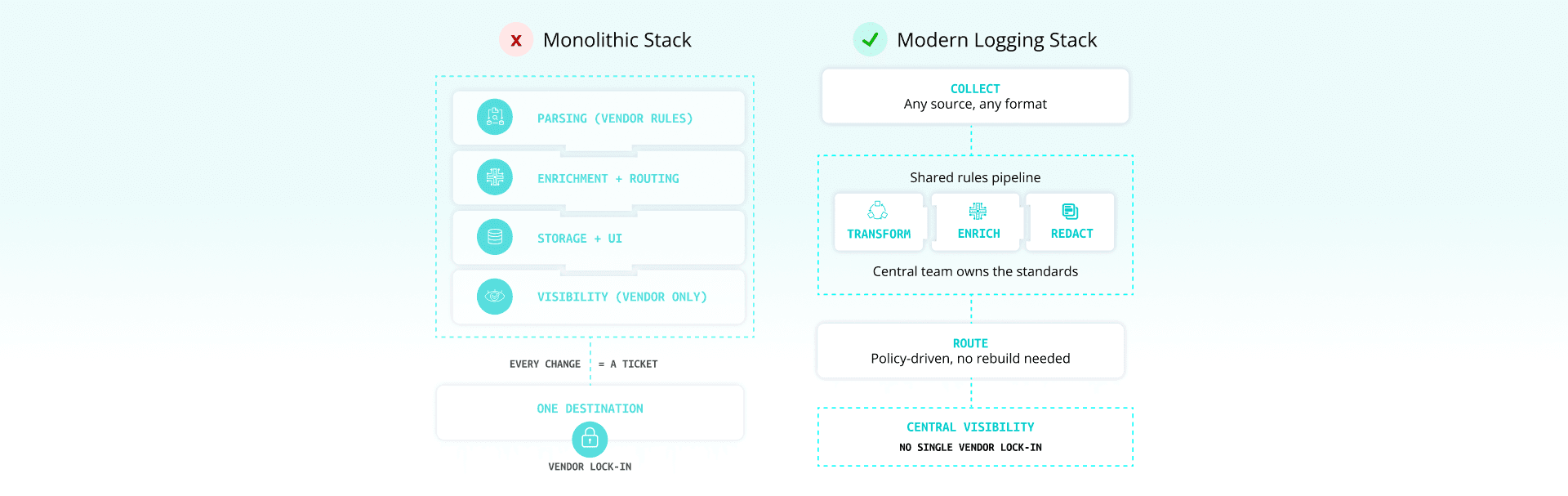
Get a quick-fire win
Centralized logging programs stall when they start with a giant re-platforming effort or a year-long standardization project. A better starting point is a very specific first win that produces real results for more than one team.
Look for something concrete: an app team drowning in their own logs with poor production visibility, a SIEM blowing through ingestion budget, or a compliance requirement that's forcing better control over PII. Frame the work as, "We're going to give this app team real visibility into their logs in production, and we're going to get security and IT the structure they need at the same time."
Reduce developer toil first. Developer goodwill is the fuel that keeps centralized logging initiatives moving. Give the app team a simple, documented way to send logs. Make sure they can see those logs in a tool they can actually use, with reasonable latency. Take on the hard work of parsing, enrichment, and routing centrally — don't ask every app team to relearn the same regex tricks. When developers feel like the central logging team is removing work rather than adding it, they become advocates instead of critics.
Address IT operations and security in the same move. While you're making life easier for the app team, normalize fields and timestamps, drop or compress noisy events that drive cost without adding signal, and apply masking or tokenization rules for sensitive data before it hits SIEMs or long-term storage. That's the shift from ticket taker to platform: you're not just moving data, you're improving it on the way.

Best practices for centralized logging teams
How to get started with centralized logging
Step 1
Create golden pipelines
Golden pipelines are your paved roads. A small set of well-documented patterns that cover most needs and make it straightforward for teams to do the right thing. A golden pipeline typically includes a small set of accepted log formats and schemas (usually JSON with specific core fields), standard parsing and enrichment rules (host metadata, app name, environment, tenant, region), built-in redaction or tokenization for sensitive fields, and clear routing rules to main tools and storage locations. The deal is simple: follow the pattern and onboarding is fast, behavior is predictable, and your logs show up where you need them. If you need something custom, that's allowed — but it takes more effort on both sides. Golden pipelines also make it much easier to scale. Packaged as templates, they can be reused across dozens of teams instead of rebuilt from scratch each time.

Step 2
Make collection and routing boring
Everyone should be able to answer — without digging through tribal knowledge — how logs get collected from each major environment (Kubernetes, VMs, SaaS, on-prem appliances), because implementing centralized logging for collection and routing requires a clear model for sources, destinations, and retention. Keep a simple catalog of sources, pipelines, and destinations. Use infrastructure-as-code or Git-backed config so changes are reviewable and reversible. Treat routing rules as shared assets, not scripts owned by a single engineer. Boring, predictable core routing frees you up to work on higher-value improvements.
Step 3
Give app teams scoped flexibility
There will always be teams that need something outside the standard paths — extra verbose logs during a migration, temporary routing to a new tool, a slightly different schema for a specific analytical need. Instead of saying no, or hand-editing everything yourself, give these teams scoped workspaces where they can safely propose and test changes. Let them extend standard pipelines with additional steps, as long as shared controls stay intact. Make exceptions visible to the central team so they can be cleaned up later if they stop being useful. This keeps the central team out of the critical path while keeping the overall system coherent.
Step 4
Offer search and analysis beyond core SIEM and observability tools
Most SIEMs and observability platforms were designed primarily for security and SRE workflows. Developers often want something different: high-volume debugging logs, quick checks on how a new feature behaves in production, a way to investigate performance without burning through someone else's ingestion budget. The teams handling this well store more raw data cheaply in object storage or a lake, provide search tools that can query that storage directly without pulling everything into the most expensive platform, and give developers governed access to their own data with role-based controls — instead of "file a ticket" every time they need a query run.
Step 5
Build continuous improvement into the operating model
Centralized logging is never finished. New tools, regulations, cloud regions, and business lines show up regularly. Retrospectives should be a standing part of the practice — after major onboarding projects, after incidents where logs helped or fell short, after migrations and tool changes. The questions worth asking: Where did we spend the most time? What did we do manually that we could automate next time? What should become a new golden pipeline? What exceptions can we retire? Over time, you should see more work happening through standard paths and less through one-off pipelines.
Step 6
Use showback to make the value visible
Central logging teams rarely get credit proportional to their impact. Showback changes that. With the right visibility, you can report how much data you're processing for each line of business, how much volume you're removing or shifting to cheaper storage, how many tools and regions you're feeding from common pipelines, and how onboarding time has changed. When you can say "these changes avoided X terabytes per day of SIEM ingest" or "we cut SIEM spend by 40 percent while adding new data sources," the conversation with leadership is different. Showback also gives you a clean way to hold teams accountable for their logging choices without making every budget conversation a fight.

What this looks like in practice
YaleNewHavenHealth
Central logging for security at scale
Yale New Haven Health's cybersecurity team brought in Cribl Stream to manage data from over 30,000 endpoints, reduce SIEM license spend, and support a migration from Splunk to Microsoft Sentinel. After a vendor update added 63 unnecessary fields to every firewall log, Stream stripped them out and brought volume back under control.
"We were constantly using about 600-700 GB/day of our 400 GB license, but were able to bring it down to less than 400 GB just by using Stream to make a couple of changes to Palo Alto Networks logs."
The result: 40 percent reduction in SIEM spend, with security coverage maintained or improved, and a central location for all syslog and UDP traffic from a highly distributed workforce.
How Cribl helps
Cribl is built for exactly this model: IT and security teams that need to collect, shape, and route telemetry across many tools and business units without letting the central team become a permanent bottleneck.
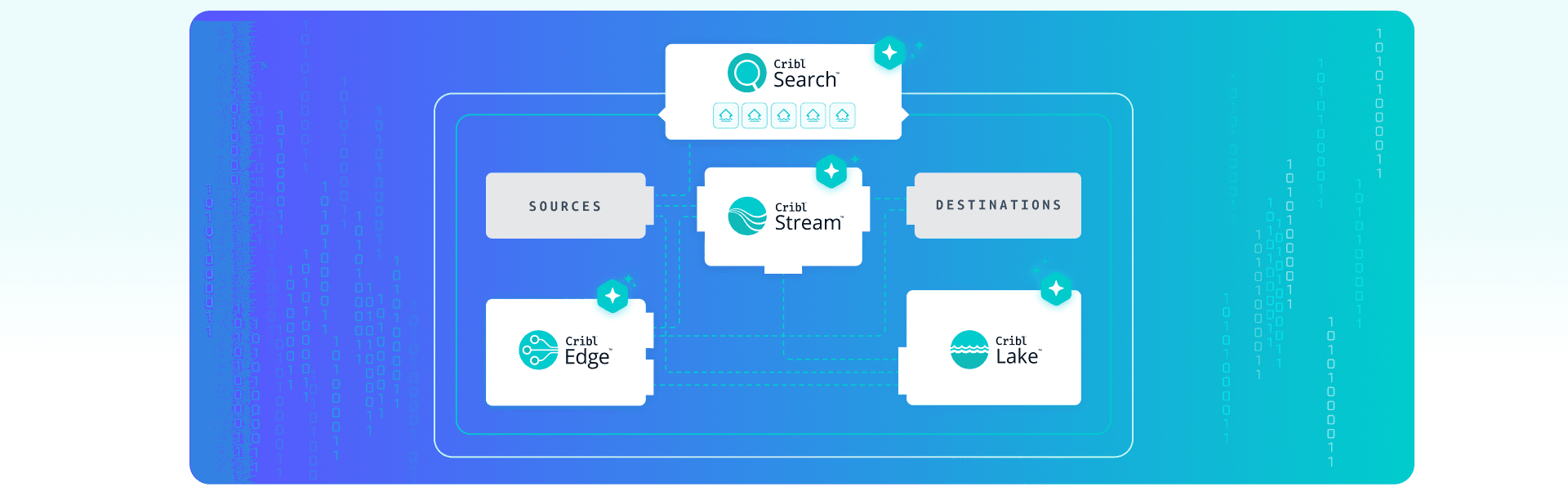
Cribl Cloud gives you a central control plane where you can run multiple workspaces — typically mapped to business units, regions, or environments — under one roof. RBAC scopes access so teams can manage their own sources, pipelines, and datasets without touching anyone else's. The central team keeps a global view of data flows and health across all workspaces. In practice, this replaces a many-to-many mesh of agents talking directly to every downstream tool. Sources send data into Cribl's data plane, which fans out to SIEMs, observability tools, data lakes, archives, and more — without each team wiring up their own integrations.
Packs are how golden pipelines become reusable. Packs bundle sources, pipelines, routes, and destinations into portable units. You can version them in Git, promote them from dev to staging to production, and share them across workspaces. Central teams publish standard Packs — firewall logs, Windows event logs, cloud audit logs — and other teams consume them as building blocks rather than starting from scratch.
Cribl Edge runs close to sources — on endpoints, servers, or Kubernetes — so app teams can send logs in familiar ways while central teams maintain control over configuration.
Cribl Stream parses, enriches, filters, and routes logs in flight, applying shared patterns like PII masking, volume reduction, and schema normalization.
Cribl Lake stores data in low-cost object storage so you're not forced to drop data or push everything into your most expensive tools.
Cribl Search lets teams query data across Cribl Lake and other stores directly, so developers, SREs, and security teams can investigate using the same telemetry without duplicating it.
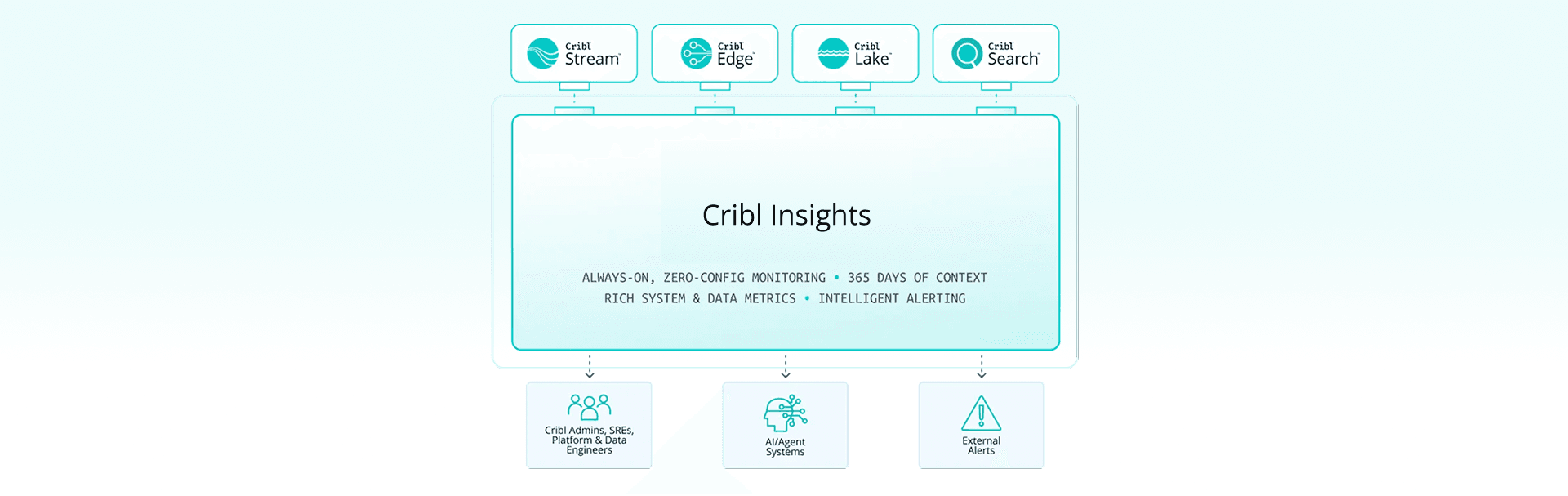
On governance: Cribl Guard scans for sensitive data and applies masking or tokenization before data reaches downstream tools. Workspaces, product-level permissions, and event-level controls keep configuration and access scoped to the right teams, even when many lines of business share the same platform. Distributed worker groups and persistent queues keep data flowing even when a destination is down, so a noisy neighbor in one workspace doesn't affect everyone else.
Cribl Insights gives you the visibility to build the showback story: which sources and routes are driving volume and cost, where drops or latency are happening, and how workloads are distributed across tenants and regions.
Summary
Centralized logging only works when it stops being a ticket queue and starts acting like a shared service. When you bring developers, security, and IT operations together around golden pipelines, simple processes, and real self-service access to data, you cut noise, control cost, and give every team what they need without burning out the central team. Cribl gives you the control plane and data engine to run that model at scale, so you can say “yes” more often, move faster, and prove the value of logging with hard results instead of hopeful promises.

