
Signal vs. noise: the platform engineer’s modern challenge

Platform engineering has reached a critical inflection point. The amount of telemetry that modern systems generate (logs, metrics, and traces from thousands of containers, functions, and APIs) has grown beyond what humans can meaningfully interpret.
The result is a signal-to-noise crisis: Platform engineers spend as much time sifting through irrelevant or redundant data as they do solving real problems. Teams absorb this overhead every day through false alerts, duplicate incidents, and tool friction that waste hours of engineering capacity while burning out the very experts hired to improve reliability.
Today’s observability stacks look powerful on paper, yet in practice they often resemble an orchestra with too many instruments and no conductor. Each tool generates its own alerts, dashboards, and thresholds, creating a fog of data that hides the real issues, the anomalies that actually threaten uptime and customer satisfaction. When critical signals drown in the noise, it’s not just productivity that suffers. The credibility of the organization’s reliability efforts takes a hit, too.
One of the biggest challenges facing organizations today isn’t that they lack data. It’s that their data lacks structure. As systems scale across multi-cloud and microservice architectures, there is a widening gap between the amount of collected telemetry and the clarity of insight. Traditional approaches, like static alerts and manual correlation, can’t keep pace with the velocity or variety of signals that modern systems produce. The outcome is predictable: slower incident response, lower confidence in metrics such as mean time to resolution (MTTR), and even more frequent failures that erode uptime commitments.
But the market is already shifting. Modern reliability engineering begins upstream with data that is structured, normalized, and contextualized before it reaches analysis tools. Leading teams now design architectures that prevent noise instead of reacting to it. They apply unified data intelligence between sources and destinations, filtering, enriching, and routing what matters most for service health. This shift to observability as strategic insight, rather than operational overhead, defines the next evolution of platform engineering.
Cribl Stream sits at the center of this transformation. Acting as a telemetry control plane, Stream enables engineers to collect once, shape anywhere, and enforce signal discipline throughout their environment. By routing only critical data to downstream monitoring tools, while cost effectively archiving full-fidelity datasets, teams can reduce chaos and gain confidence in every alert, every time.
The hidden cost of alert fatigue on SLOs
Every operations team knows the feeling: a flood of alerts that come in faster than anyone can triage, let alone understand.
For platform engineers, this constant stream of pings, dashboards, and threshold breaches isn’t just noise, it’s a direct tax on uptime, efficiency, and morale. What looks like “just another noisy day” in the system actually compounds into measurable business costs: violated SLOs, depleted error budgets, and exhausted engineers.
The scale of the problem is stark. In a high‑velocity organization, SREs may see thousands of alerts daily, many of which call for no action at all. Each false or redundant alert eats time, cognitive energy, and attention that should be spent on preventing outages or improving systems. Over time, this creates a feedback loop of diminishing focus and rising operational risk. Missed burn‑rate alerts lead to breached SLOs. Breached SLOs mean customer dissatisfaction and lost revenue. Lost revenue drives internal pressure, and that internal pressure drives more reactive work for already stretched reliability teams.
There’s also the human cost. Constant paging leads to stress, burnout, and (eventually) attrition. When experienced engineers move on, it destabilizes incident workflows and reduces institutional knowledge. Teams fall back into firefighting mode, a reactive posture that contradicts one of platform engineering’s founding principles: proactive reliability driven by data.
Before: Reactive fatigue at scale
In most organizations, the response to excessive alerting has been incremental tuning. Teams adjust thresholds in Datadog, Prometheus, or Splunk software, hoping to calm the noise. But these small filter tweaks don’t address the underlying issue: By the time the data reaches the alerting tool, the damage is already done. The system is reacting to noise that should have been suppressed far upstream.
The operational cost becomes painfully clear during post‑mortems. Alerts may arrive late, in fragments, or without context. Developers and SREs spend hours chasing symptoms rather than causes. Error budgets balloon, SLO compliance dips, and leadership loses confidence in reported reliability metrics. The resulting frustration spills across teams: Engineering blames monitoring, monitoring blames data quality, and everyone loses precious time in the process.
After: Intelligent filtering and upstream context
With intelligent filtering in place, the workflow changes fundamentally. Cribl Stream allows data to be screened, routed, and enriched before it reaches any alerting or observability tool. Low‑value events, like repetitive container restarts, debug logs, or routine infrastructure noise, can be dropped right at ingest. Actionable events are tagged with helpful metadata like environment, service owner, and incident priority, making downstream alerts far easier to triage.
The outcome is a noticeable reduction in alert noise for many platform engineering teams, who report spending less time firefighting and more time addressing systemic reliability issues. One example comes from iHerb, a global e-commerce company that replaced its in-house logging pipeline with Cribl Stream to manage 5TB of daily data. By filtering and routing data intelligently, iHerb successfully reduced the load on its analytics tools, improved uptime, and freed engineers to focus on higher-value work instead of maintaining custom infrastructure.
Technically, the power lies in upstream control. Cribl decouples data ingestion from tool‑specific alert rules, so teams can manage event quality and telemetry as a reliability asset rather than a liability. Operationally, this results in more focused incident response and improved visibility into true service health. For the business, it supports more predictable operating costs and helps teams stay focused on innovation and service delivery — not avoidable toil or reactive firefighting.
“Outages are costly for us as an e-commerce organization. Cribl Stream allows our engineers to use their time and expertise on minimizing downtime and other important tasks.”
—Aaron Wilson, Senior Site Reliability Engineer at iHerb
Here’s how those outcomes help the business:

SLO stability
Less alert noise means it’s easier to manage error budgets and prevent costly violations, supporting more consistent service delivery and customer trust.

Human performance
With less noise, the team is less fatigued and can focus on high-value work, improving morale and supporting stronger retention.

Financial efficiency
Fewer interruptions and less downtime mean budgets go further. Teams can allocate resources to innovation versus fire drills or tool bloat.

Reliability culture
Platform engineers reclaim time for improvement and strategy, not just response, reinforcing their role as a business driver rather than as a reactive cost center.

When teams can treat signal quality as a measurable input to reliability, every alert becomes meaningful. Engineers spend less time muting and more time improving, and that shift builds both stronger systems and stronger teams.
Proactive reliability through data intelligence
Platform engineers know they must shift from chasing alerts to preventing them. But they struggle to do so in practice because their telemetry pipelines are tuned for reactivity: The pipelines respond to what’s already broken rather than spotting the early warning signs of failure. As hybrid and multi‑cloud systems sprawl, proactive reliability depends less on writing new rules and more on controlling the health and structure of the data feeding the alerting stack.
Cribl Stream becomes pivotal here. Acting as an intelligent control plane for telemetry, Stream allows teams to collect once, route anywhere, and apply fine‑grained logic before data ever touches downstream tools. This transforms telemetry from a flood of uncorrelated metrics and logs into a living asset that’s clean, consistent, and ready for predictive analysis. Plus, with Cribl’s AI-powered natural language to regex editor, creating robust functions becomes faster, easier, and more accessible to members of your team.
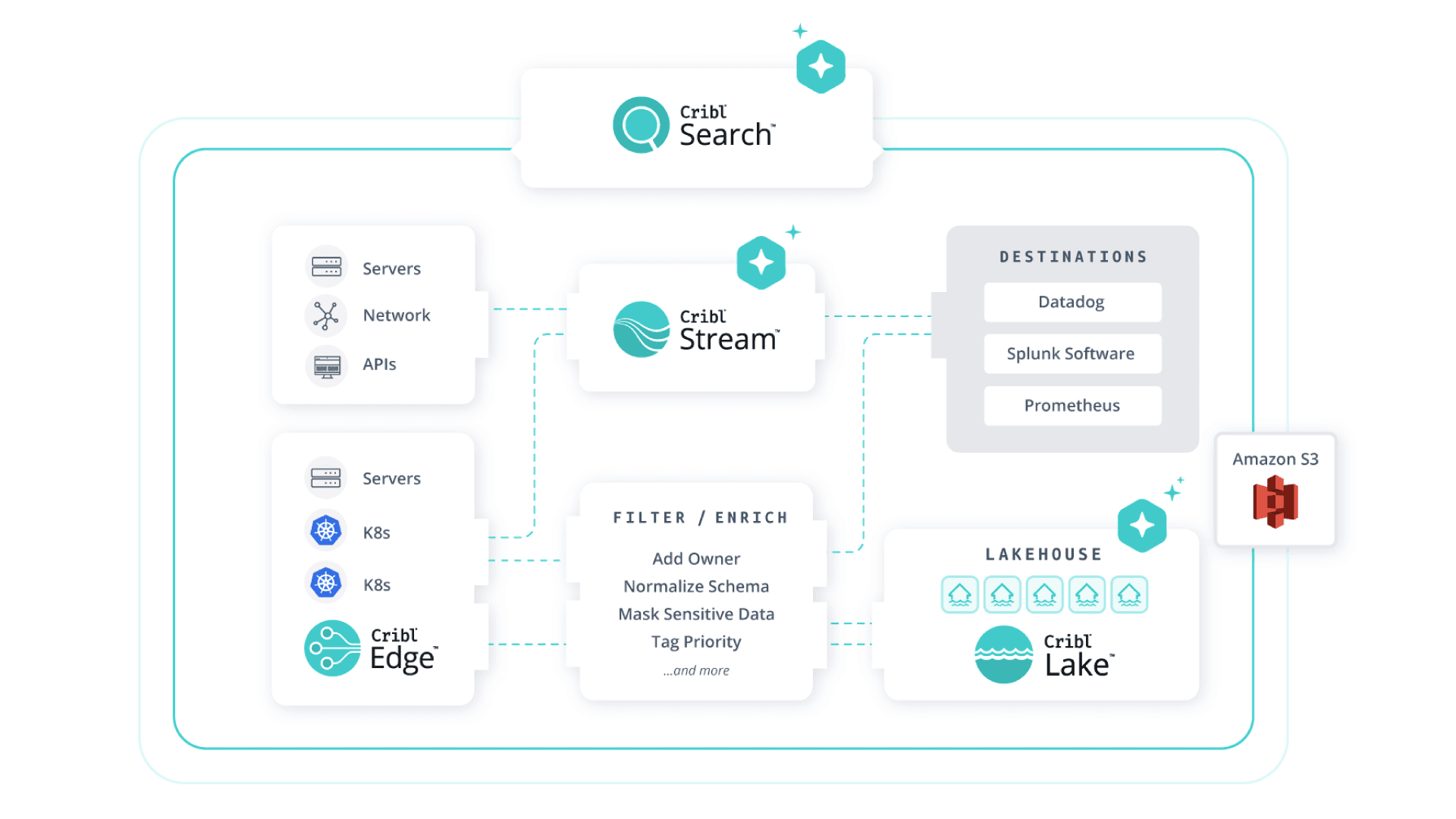
Traditional architectures forward everything (logs, metrics, and traces) from Kubernetes, APIs, and edge networks to Datadog, Prometheus, or Splunk software. These platforms then attempt to make sense of it all moment by moment. But by the time that data arrives, problems already exist: Fields are inconsistent, timestamps drift, and noisy duplicates skew correlation. Analysts spend cycles normalizing and retrying queries when they should be identifying trends that precede impact.
Cribl Stream inverts this model. Every event enters a vendor‑agnostic pipeline for inspection, filtering, and enhancement. Engineers can:
Align schemas and normalize timestamps across tools.
Mask or delete sensitive values in real time before they enter any analytics system, preserving compliance while maintaining fidelity. Cribl Guard uses AI to further streamline the process.
Add context such as service, owning team, or environment at ingest so downstream alerts immediately include ownership clarity.
Suppress redundant noise (like repetitive K8s health checks or API retries) that adds cost without value.
The result is telemetry that’s inherently trustworthy and analytics‑ready. Instead of using dashboards to piece together fragmented data, SREs can move upstream and predict reliability risk by spotting trends in golden‑signal metrics before breach thresholds are hit.
Operational and business impact
Adopting proactive data intelligence changes reliability behavior. With standardized, enriched data:
Platform engineering teams detect issues earlier. Patterns like rising latency or error‑rate anomalies are visible in near real time because Cribl speeds normalization and routing to all monitoring tools at once.
Tool flexibility improves. Because Stream decouples ingestion from analysis, teams can run legacy and modern platforms in parallel, and avoid replumbing collectors when migrating or testing new vendors.
Costs drop alongside toil. By filtering out low‑value telemetry and routing “just‑in‑case” data to low‑cost storage (for example, S3 or Cribl Lake), organizations reduce tool payloads and achieve predictable capacity planning.
From a business view, this upstream control stabilizes SLOs and creates credible data for leadership review. Operations leaders gain confidence that alert numbers, burn rates, and reliability dashboards actually reflect how customers experience the service.
Here’s where the investment in proactive reliability pays off:
Predictable SLO performance
Data hygiene and enrichment lower alert churn, allowing error budgets to be managed with confidence.
Operational efficiency
Fewer redundant events mean faster queries, cleaner dashboards, and less wasted compute.
Team focus
Engineers shift from triage to trend analysis, strengthening the organization’s proactive capabilities.
MTTR optimization beyond alert reduction

While reducing noise is effective, it solves only half the telemetry problem. Platform engineers must also resolve real incidents faster once they do occur.
Mean time to resolution (MTTR) remains a defining metric for success, yet traditional data models slow it down. High‑volume telemetry that’s difficult to correlate or search prolongs diagnosis and keeps critical systems offline longer than necessary.
Faster root cause analysis through data quality
Cribl Stream empowers platform engineers to maintain data fidelity without flooding tools or analysts with redundant events. By delivering just‑enough contextualized data to downstream systems, teams gain a clear view of symptom progression across the stack.
During a service degradation, engineers can now trace event causality faster because each telemetry record carries consistent labels, such as environment, cluster, application, request path, and owner. Correlations that once required manual joins or cross‑tool exports become immediate.
When issues do require deep forensics, Cribl’s Replay feature enables teams to re‑ingest historical telemetry from object storage into their tool of choice without risk. This preserves storage efficiency while allowing full‑fidelity investigation when needed.Empowering platform engineering teams like analysts: automation and decision support
Engineer productivity rises when mundane tasks are automated and signal clarity is high. Through Cribl Stream, teams build resilient pipelines that tag events with priority levels or trigger predefined runbooks without requiring human intervention.
For example, an error‑rate spike in API traffic can automatically route a particularly formatted alert to Slack with contextual labels (owner, region, cluster) and kick off an automated diagnostic workflow. The combination of enrichment and automation minimizes manual handoffs that extend MTTR.The role of observability partners and cross‑team visibility
Cribl’s architecture supports multiple destinations in real time, which means DevOps, Infrastructure, and Security teams can share identical, normalized datasets in their tools of choice. There’s no waiting for one system to export to another; MTTR improves simply because everyone is working from the same trusted event context. Cribl Notebooks is a single place for all team members to gather, share data, provide context, and collaborate. Once an investigation is complete, Cribl AI can be easily used to create a summary— simplifying incident reports and saving precious time.
Joint troubleshooting sessions move faster when teams don’t argue over whose data is right. Instead, each uses the same enriched pipeline output tailored to its environment. That way, security sees masking and hash context, platform engineers see reliability and owner metadata, and developers can view application traces. This shared truth builds confidence in incident resolution and postmortem findings.
As data quality improves and response accelerates, organizations see a cultural shift from reactive incident management to proactive reliability engineering. Engineering leaders report fewer after‑hours fire drills and better collaboration with adjacent teams. Each successfully averted incident builds organizational confidence that reliability is a planned outcome, not a defensive reaction.

Cribl Stream helps teams tie these threads together:
Turning raw telemetry into predictive insight before alerts fire.
Enabling automation and runbook triggers to accelerate resolution.
Creating a shared data plane that improves decision making and cross‑team alignment.
Over time, this combination reduces costs, protects uptime, and stabilizes engineer retention — exactly the outcomes that turn reliability from a technical achievement into a sustained business advantage.
Scaling reliability practices
As organizations mature in reliability practice, the challenge evolves from fixing incidents quickly to maintaining consistency at scale. A single team’s automation or uptime gains only matter if they can be replicated across the organization. True, sustainable reliability isn’t a set of isolated wins; it’s a system that learns.
Platform engineering leaders know that stability doesn’t scale simply by adding headcount. It scales through discipline: consistent data governance, automation, and a feedback loop where every improvement strengthens the next release. When one team resolves a recurring issue or tightens its MTTR, that knowledge needs to ripple through pipelines, playbooks, and culture. This is where data unification becomes the backbone of scaling reliability.
From local insight to shared intelligence
Cribl Stream enables this scaling by creating a common data fabric that unites telemetry across teams, stacks, and environments. When all groups (development, operations, platform engineering, and security) draw from the same normalized event data, reliability becomes a shared language rather than an isolated goal.
SRE teams use Cribl Stream to collect telemetry once and shape it for different stakeholders, eliminating redundant collectors, configuration sprawl, and tool conflicts. Development may consume metrics in Prometheus, while infrastructure uses the same data through Datadog, and governance maintains full‑fidelity logs in an S3 data lake. The consistency across these views builds trust: When an incident occurs, root cause discussions start at alignment, not disagreement over whose data is correct.
By operating as a vendor‑agnostic layer between sources and destinations, Stream lets organizations escape the inefficiency of tool silos. Data enriched upstream with context like service owner, deployment region, and environment type turns otherwise raw telemetry into critical organizational intelligence. Every resolved incident adds structure back to the system. Now, patterns and remediation steps are discoverable across teams, not lost to chat threads or static reports.
Establishing continuous reliability tuning
At scale, maintaining reliability means embracing continuous tuning, a mindset where improvements to alerting, telemetry, and process don’t stop after stabilization. Much like performance optimization after a platform migration, reliability tuning requires systematic evaluation of metrics such as:
Mean time to resolution (MTTR): Is the time it takes to resolve incidents trending downward quarter over quarter? Effective organizations measure MTTR at both team and system levels to ensure improvement isn’t isolated.
Mean time between failures (MTBF): Are changes increasing stability and time between major incidents? Tracking MTBF trends helps platform engineers identify the cumulative effect of post‑incident fixes and automation investments.
Uptime percentage or SLO adherence: Is your 99.9% SLO consistently achieved across services, or are certain regions lagging? Aligning these metrics to business goals ties technical performance directly to customer experience.
Cribl Stream supports this iterative approach by making it easy to analyze and refine what’s actually driving alerts and outages. Teams can replay historical telemetry to model potential improvements before deploying new filters or routing logic, which helps minimize the risk of over‑optimization or blind spots. It’s “telemetry as a sandbox”: Each tuning cycle makes incident forecasting sharper, alert volume leaner, and detection times shorter.
Scaling teams without scaling toil
One of the most powerful outcomes of unified data and proactive tuning is team scalability. As organizations grow, the natural tendency is to add engineers to handle expanding workloads. Yet effective team scaling often looks very different: doing more with data, not more people.
Key gains appear in three areas:
Automation and reuse of reliability assets: Playbooks and routing configurations built in Cribl Stream can be exported as code for version control and then reused across teams, reducing repetitive configuration effort.
Shared, reusable configurations: By aligning on normalized data structures, new projects inherit proven dashboard definitions and alert policies from prior teams, speeding uptime readiness without discovery overhead.
Cross‑functional alignment: Stream’s multi‑destination architecture means Platform Engineering and Security teams all access the same contextual data yet retain their tool preferences. This shared source of truth shortens onboarding and reduces dependency bottlenecks.
Organizations that take this approach report improved engineering focus and better knowledge transfer between teams. Over time, they reduce unplanned work and maintain burn‑rate predictability, a key business indicator of operational maturity.
The reliability flywheel
When continuous tuning, shared data, and cultural alignment converge, they form a flywheel of improvement. Each iteration feeds the next. Telemetry hygiene reduces noise and MTTR, and those gains free up time for further automation. From there, the automation helps enhance system resilience and pushes MTBF higher.
This flywheel effect is what turns platform engineering from a reactive discipline into an engine for business continuity. The outcomes reinforce themselves. Every team benefits from the work of others because the underlying data is shared and trustworthy.
Reliability at scale is not just about keeping services up or hitting a numerical target. It’s about creating an organization where everyone, from developers to executives, has confidence in the signals coming from their own systems. With Cribl as the foundation for shared data control, platform engineering teams grow without losing clarity. And reliability matures into a company-wide capability that sustains performance for the long term.
Conclusion: Delivering reliability without compromise
Modern reliability is as much about culture as it is technology. The organizations that excel are those that turn data into trust.
When teams across the organization share the same high-quality telemetry, reliability becomes a collective goal supported by consistent metrics and workflows. That synergy drives faster detection, shorter MTTR cycles, and longer mean time between failure (MTBF), which are measurable indicators of operational maturity.
The benefits extend across performance and cost. Optimizing what enters high-cost monitoring tools, while routing lower-value data to less expensive storage, reduces spend and complexity. At the same time, it gives teams the freedom to evolve their stacks. Flexibility replaces lock-in, and teams can run old and new tools in parallel without reengineering the data foundation. Reliability is no longer bound to a single platform; it becomes a capability woven into the organization.
Continuous tuning — not one-time optimization — is the hallmark of today’s high-performing platform engineering teams. Each iteration, powered by both human insight and AI acting as a virtual team member, improves data quality, alert precision, and cross-team alignment, creating a flywheel of improvement that builds resilience over time.
Cribl is built for this adaptive model. By giving teams full control of their telemetry and the flexibility to route it anywhere, organizations strengthen uptime, reduce toil, and ensure reliability scales along with their business. When PlatEng teams use AI in their workflows (always keeping humans in the decision-making loop), they benefit from rapid incident summaries, data-driven recommendations, and automation that amplify every cycle of continuous improvement.