

Modern application architectures have unlocked massive agility for engineering teams. But they’ve also created complexity at scale.
Telemetry sprawl, blind spots, and endless noise can leave even the most seasoned DevOps engineers and SREs chasing elusive bugs and spending hours on root-cause analysis (RCA). MTTR balloons as data hides across silos, and “just one more dashboard” never quite delivers the answers you need.
These operational headaches are exactly why we built Cribl Stream and Cribl Edge. Collect telemetry data, normalize it, and route it at massive scale and with minimal friction. They work together to centralize, enrich, and correlate your data, so troubleshooting becomes more of a routine and less of a fire drill.
Here’s how DevOps, Observability, and SRE teams can use Stream and Edge to reduce troubleshooting time, gain full-chain visibility across services, and ensure every incident is resolved faster with less stress and more confidence.
Why troubleshooting modern application environments is so hard
Cloud-native and service-oriented architectures promise scale, agility, and uptime. But they come with their own set of troubleshooting nightmares:
Data fragmentation: Telemetry lives everywhere. It’s in container logs, node-level metrics, traces, and third-party SaaS tools. Data rarely arrives in a unified format.
Too many monitoring tools:Multiple teams juggle a cluttered landscape of dashboards, each optimized for only one dimension: APM, logs, network. None show the full story, and everyone has their own version of the truth.
Difficult root-cause isolation: Correlating events across services, clouds, or legacy and modern stacks is a puzzle, slowing root-cause analysis and bloating incident timelines.
Noisy alerting: High cardinality data and duplicative signals make it difficult to prioritize or pinpoint what matters.
Telemetry volume and cost: Data grows exponentially, leading to storage bloat, high egress costs, and expensive, hard-to-manage observability tools.
Cribl Stream and Edge cut through these problems, putting all the right telemetry in all the right formats at your fingertips without painful code changes or endless manual mapping.
How Cribl helps: a practical approach
Using Cribl Stream to aggregate and route telemetry
In complex distributed environments, DevOps teams face data fragmentation, inconsistent formats, and escalating costs from duplicative log ingestion. Cribl Stream is a powerful telemetry engine that centralizes, standardizes, and enriches data flows before they touch your downstream analytics or security tools.
By operating as a universal receiver, Stream gives you control and flexibility over your telemetry so you can clean, shape, enrich, and route logs, metrics, and traces, regardless of their source or destination.
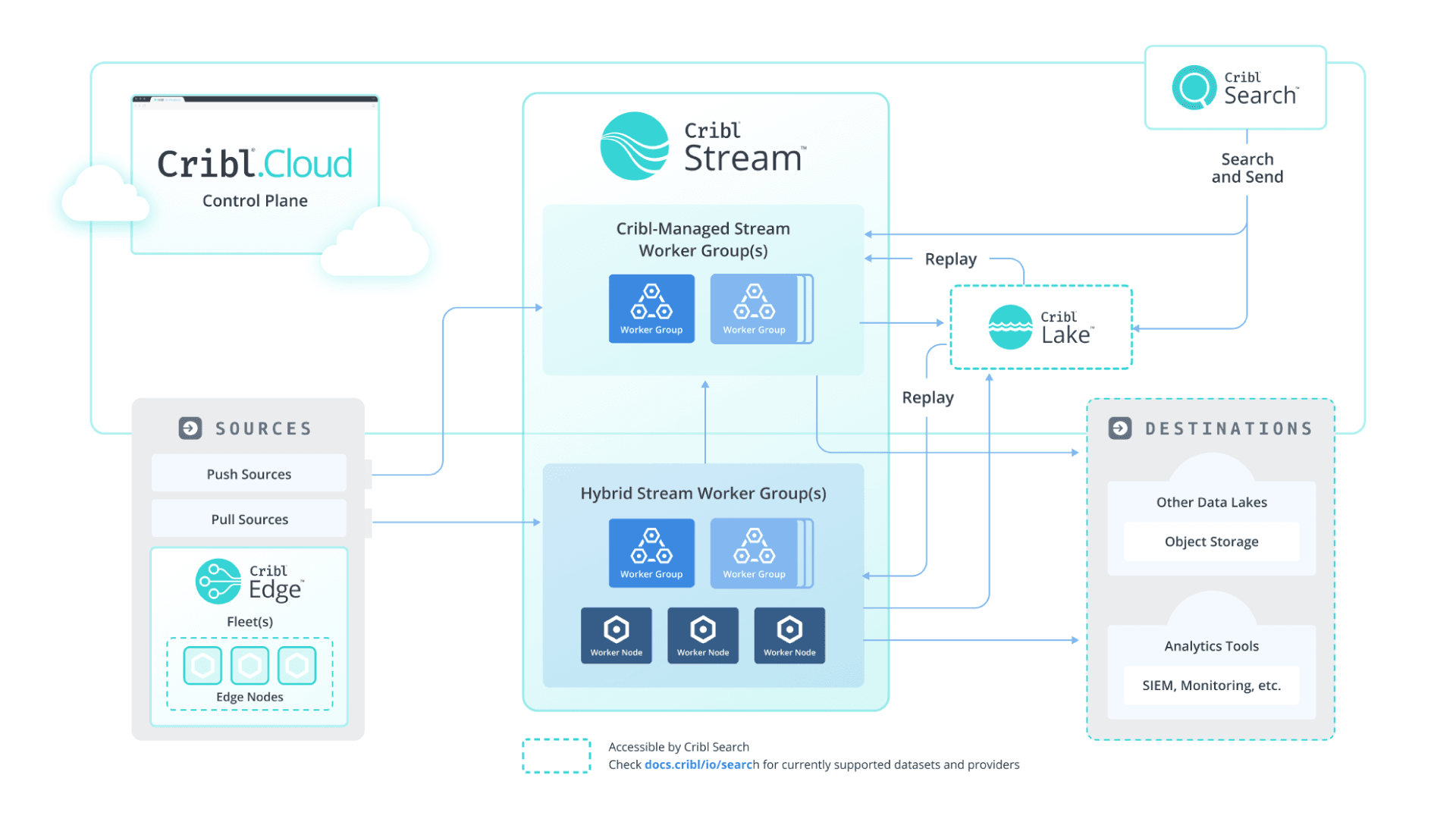
Full-suite reference architecture.
Once Stream and Edge have handled collection, normalization, and routing, investigations often kick off in Cribl Search, Cribl Notebooks, and Cribl Lake. Use Search to zero in on outliers or anomalies, then pivot to Notebooks for collaborative analysis. You can track queries, add comments, and build a transparent investigation trail. For long-term retention or replay, route artifacts to Lake so your team can revisit, audit, or refine postmortem workflows without rebuilding pipelines.
Start by ingesting data from any environment. That could be Kubernetes clusters, cloud platforms, legacy systems, or modern microservices.
Normalize and enrich telemetry using schema mapping and field-level augmentation, bringing consistency and context to every log and metric. Cribl’s AI-powered natural language editor automates mappings and enrichments and leaves you with full control to tune results before deployment.
Drop noisy, low-value events at the pipeline level, such as health checks or redundant debug lines, drastically reducing storage and analytics spend.
Selectively aggregate, sample, or mask high-volume log streams. This reduces the noise for your analyzers and ensures only relevant, actionable data is processed further.
Use dynamic routing to send only critical or regulatory-required telemetry to high-cost analytics tools and push less critical data (for example, debug logs) to affordable long-term storage or data lakes.
Enable Cribl Stream’s Replay workflows by storing raw data in neutral formats, allowing you to send it to new destinations at any point, supporting migrations or tool evaluations without any telemetry lock-in.
When an investigation is needed, time is of the essence. Cribl Notebooks is a single place for all team members to gather, share data, provide context, and collaborate. Once an investigation is complete, Cribl AI can be easily used to create a summary simplifying incident reports and saving precious time.
When troubleshooting across multiple Kubernetes environments for example, Cribl Stream ingests all cluster logs, intelligently enriches events with cluster metadata, filters out non-actionable logs at the source, and routes only actionable or policy-relevant data to SIEM and analysis platforms. This slashes MTTR and data costs while maintaining high fidelity and compliance-ready records.
Using Cribl Edge to collect data closer to the source
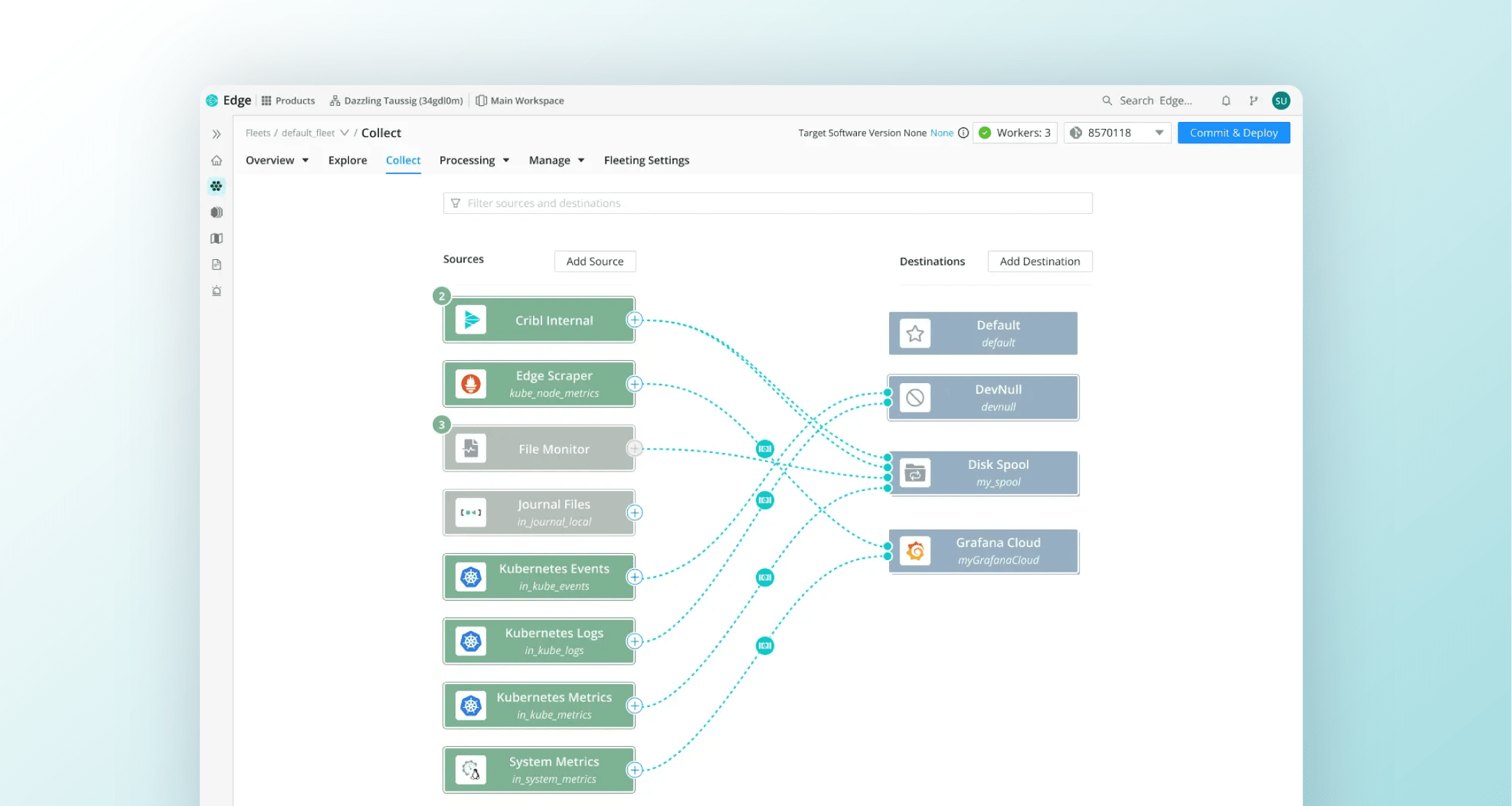
Distributed environments generate telemetry everywhere: at the node, in the pod, or deep inside your edge compute layer. Relying solely on centralized collection can mean crucial data is lost, delayed, or simply never surfaced in time to prevent outages. Cribl Edge puts lightweight, intelligent data processing as close to the source as possible, dramatically improving both visibility and responsiveness.
One of Edge’s biggest operational wins is slashing agent management headaches. With Edge, you can reduce the number of vendor-specific agents you need, simplify deployments across diverse environments, and take advantage of Cribl’s latest advances for faster, more reliable agent upgrades and monitoring. Teams spend less time struggling with patching, version mismatches, or troubleshooting agent failures and more time actually solving problems.
Deploy Edge agents on individual hosts, containers, or endpoints to instantly capture live telemetry regardless of sprawl.
Pre-process and enrich data at the point of generation, enabling granular tagging (for example, add location, service context, or security zone identifiers) before it ever leaves the node.
Apply filtering and transformation to suppress superfluous data and send only the events that matter (such as anomalies, security incidents, or SLA violations) to your central pipeline.
Compress and securely forward relevant data, reducing egress costs and network strain, especially when troubleshooting remote, bandwidth-constrained environments.
Trigger ad-hoc or persistent data captures on specific nodes in response to emerging incidents, giving SREs immediate insight without waiting for redeployment or reconfiguration.
For example, during an intermittent latency spike impacting a particular microservice, Cribl Edge collects and streams real-time logs and metrics from affected edge nodes. Data is immediately tagged and shaped for context, then routed for central analysis, allowing the response team to isolate and remediate the root cause with minimal delay and no extra agent wrangling. That means fewer vendor-specific agents to deploy or maintain, one place to monitor agent health and updates, and a drastically lower risk of production issues tied to agent bloat or version drift.
Correlate data across layers

The reality of distributed troubleshooting is that telemetry is most valuable when it provides a holistic, end-to-end picture that spans application, infrastructure, and even network layers.
What sets Cribl apart is the ability to correlate data from application logs to infrastructure telemetry and traces all in one place, allowing teams to move from fragmented visibility to unified, actionable context.
At the analysis stage, leverage Search to stitch together events and run targeted queries across systems. Move complex cases into Notebooks, where you can iterate on hypotheses, annotate findings, and share a single view with teammates. Notebooks make it easy to document every step, build context, and remove knowledge gaps when cross-team collaboration is critical.
Teams gain:
Unified view: Build composite events that span the request path, from the ingress load balancer to the database.
Rapid root cause analysis: Easily stitch together failures across services and infrastructure layers. Cribl Stream’s enrichment and normalization capabilities make cross-source correlation routine, not a nightmare.
MTTR slashed: By putting everything you need on a single pane of glass, you move from “what happened?” to “why did it happen?” faster than ever.
Service enrichment: By shaping telemetry data to include service context, teams can make fast decisions on how to prioritize handling incidents. Business critical incidents are prioritized, while incidents that impact less critical services can be handled later.

Real world scenario: investigating high latency in a microservice
Let’s imagine you’re on the hook for a business-critical retail platform. Customers suddenly report slow checkout times, one of the classic nightmares for DevOps and SREs managing distributed systems. The root cause could be anywhere: frontend pods, the API tier, databases, network links, or even third-party payment services. Your goal is to resolve the issue fast, before it impacts revenue and customer trust.
Here’s how the troubleshooting journey could look using Cribl Stream and Edge:
Capture data at the source with Cribl Edge
As soon as latency emerges, you deploy Edge agents (or use existing ones) on the critical front-end pods, back-end services, and database nodes involved in key transaction flows like payment processing, user logins, or onboarding sequences. Edge immediately starts collecting real-time logs, metrics, and traces right at the point of activity, ensuring you don’t miss the earliest signs of trouble, even in ephemeral containers. Use Cribl’s AI-powered natural language editor to create pipelines and test them before final deployment. This AI functionality enables junior team members to do work that was once reserved only for the most experienced technicians on your team. This frees up resources and gives your most seasoned leaders the time they need to think about solutions to more complex challenges.
Enrich and filter telemetry at the edge
Edge pre-processes data by tagging events with key context like node role, cluster name, or customer region before forwarding. It filters out routine, non-actionable noise, so only relevant latency or error signals move onward. This minimizes chatter and cuts egress costs while preserving what matters for troubleshooting.
Aggregate, normalize, and route with Cribl
All edge-collected telemetry converges at Stream. Here, Cribl Stream applies intelligent schema mapping and enrichment to unify disparate log formats. For example, Cribl harmonizes “user_id,” “customerId,” or “uid” fields. Then, it further correlates transactions using request IDs, aligns timestamp discrepancies, and ties together events across services and data sources. Cribl Guard’s AI-enabled engine looks for PII and sensitive data in real time in the data stream. It can then mask or delete the offending data ensuring that sensitive data doesn’t reach final storage locations. Teams can save energy by utilizing Cribl’s AI natural language editor to create rules in record time. With Cribl, you not only have the ability to route data to your observability and security tools, you can route “just in case” data to a data lake for future investigations.
Correlate and analyze across layers
Stream feeds enriched, structured events into your analytics or SIEM platform. Now, instead of stitching together disconnected logs in different tools, your observability platform receives cleaner, more consistent telemetry complete with enriched context, so you get a clearer, end-to-end view of the customer journey within your preferred analytics, APM, or SIEM tool.
Cribl products don’t replace these tools, they cut noise and enrich data so your observability stack works better and delivers deeper insights. Cribl gives you the ability to search across your tools and data lakes, creating visualizations that illuminate the moment where latency spikes, revealing, for example, that a specific database query in the payment workflow is lagging.Validate the fix and close the loop
You update or tune the culprit microservice or query. The moment the change is live, ongoing telemetry from Edge and Stream confirms clearly and in near real-time that checkout speeds are back to baseline and no new errors have surfaced. You can even replay raw data or search your data with Cribl Search if you want to run additional analysis, build a notebook for future similar investigations, or export artifacts for post-incident review.
Investigation shouldn’t end with a fix. Use Notebooks to capture your troubleshooting narrative, highlight lessons learned, and preserve key data points in Lake for compliance, audits, or future learning. By making each step traceable and reusable, you streamline team onboarding and set the groundwork for continuous improvement.
Instead of scrambling between dashboards, custom scripts, or standalone analytics, Cribl surfaces unified context and streamlines investigations whether that means replacing legacy tools or integrating across existing ones.

By aligning edge data collection with central enrichment and correlation, you root out the source of latency in minutes, not hours or days. Storage and licensing costs drop by filtering and routing only necessary data. Customer experience rebounds, and your team closes the loop with high confidence and minimal disruption.
Best practices + pro tips

Data sampling
Use Cribl Stream to sample high-volume events (for example, load balancer logs) so you keep statistically relevant data without drowning in noise.

Log enrichment
Augment every event with helpful context (like customer ID, session token, and cloud region) right in the pipeline for faster root cause analysis.

Conditional routing
Set logic rules to prioritize critical signals (like security or payment errors) to hot paths, while routing low-priority logs to long-term storage.

Human-in-the-loop AI
Lean on Cribl’s Copilot Editor to suggest mappings and filter noisy events, but always review and tune for your unique stack and needs.
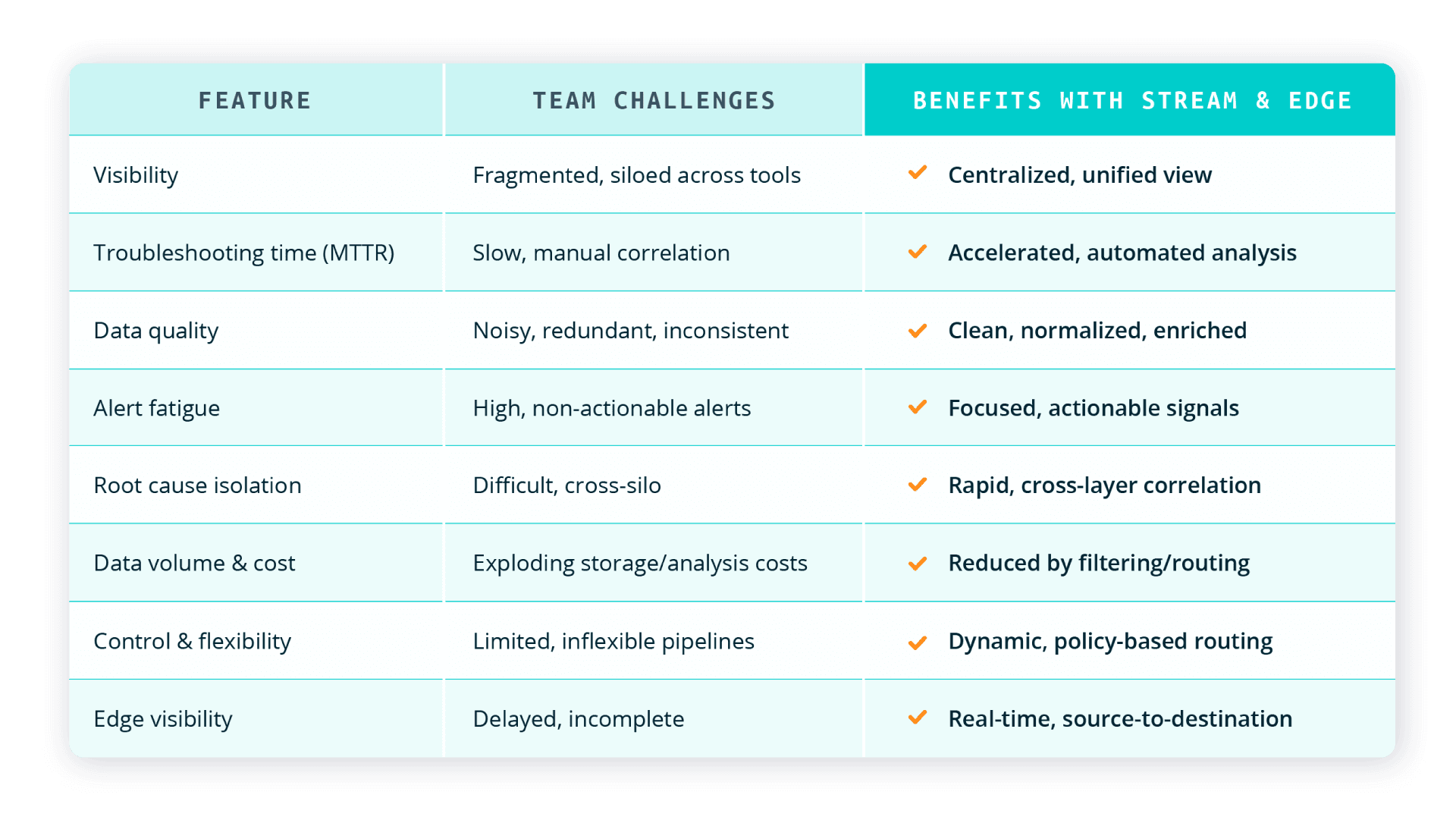
Conclusion
Distributed systems don’t have to be a mysterious black box. With Cribl Stream, Edge, Search, and Lake, your teams benefit from the end-to-end pattern: Edge collects, Stream shapes and routes, Search investigates, Notebooks document and collaborate, Lake retains. Each step ensures you’re reducing friction, boosting collaboration, and future-proofing incident response.
Ready to see how Cribl can simplify troubleshooting for your team? Try our sandboxes and take control of your telemetry today.