
A very popular use-cases for Cribl is routing of data to the best possible store. Given the types, costs and complexity of managing data at scale, there is no single store which is appropriate for all. Some events belong in a real-time system, some others may need to be routed to a batch analytics store, and yet another portion may be sent straight for archiving. At our GA release we shipped with Splunk, NFS, and S3 as destinations backends, and since we’ve added more options, and now can send data to Kinesis Streams, Elastic and Honeycomb.
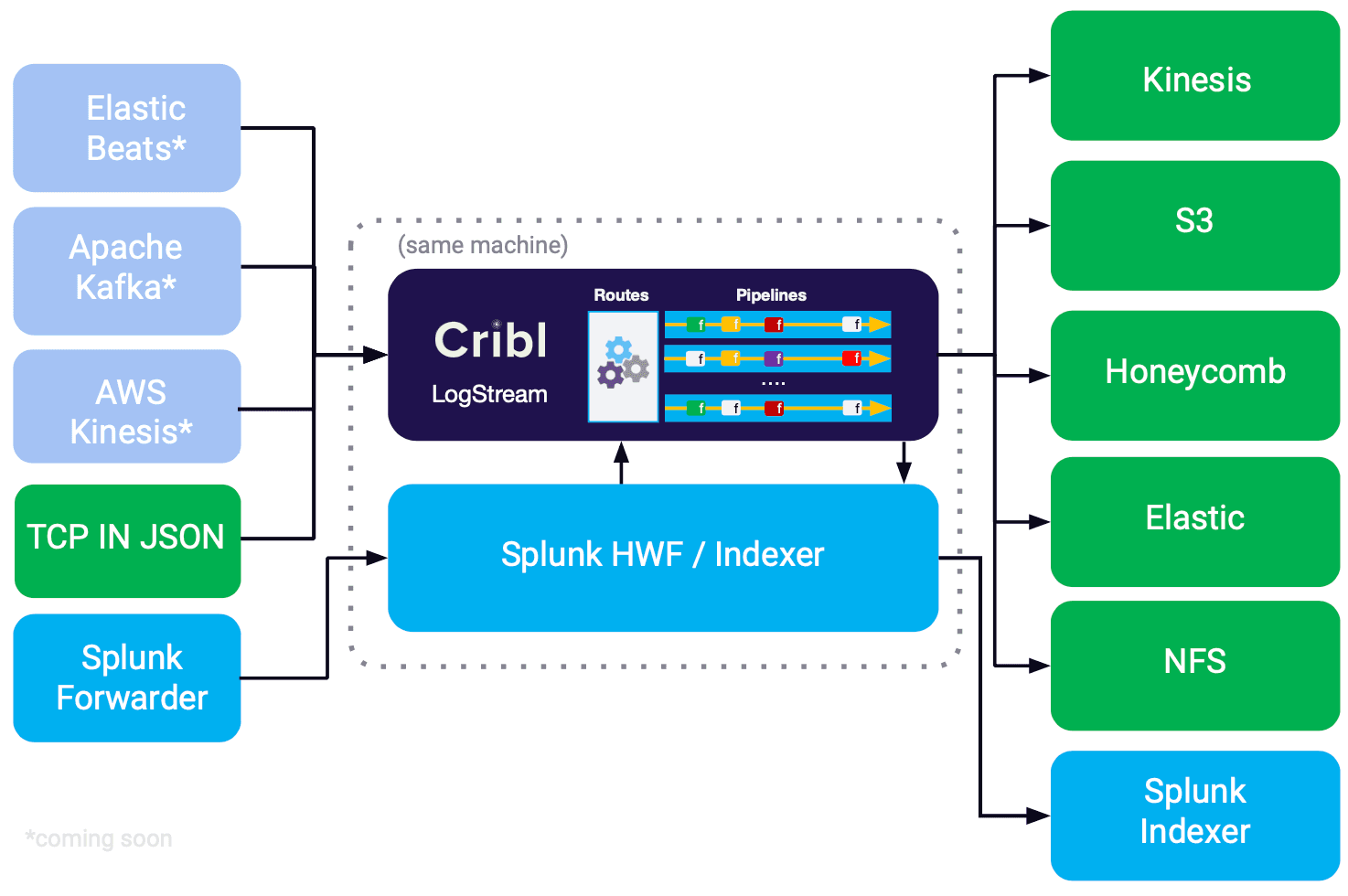
Another very popular use-case for Cribl is noise reduction or smart sampling of high volume, low value data sources like web access logs, firewall & router logs, VPC/Netflow flows, etc. Smart sampling allows admins and SMEs to apply domain expertise to keep interesting events while sampling higher volume but less interesting ones. This results in a leaner, cleaner and much better performing analytics system.
Let’s see how using both routing and sampling is the best of both worlds. For the rest of the post let’s assume that we have a source of classic web access log events (sourcetype=='access_combined) and we want to store a full archival copy in S3 and a sampled version in Splunk.
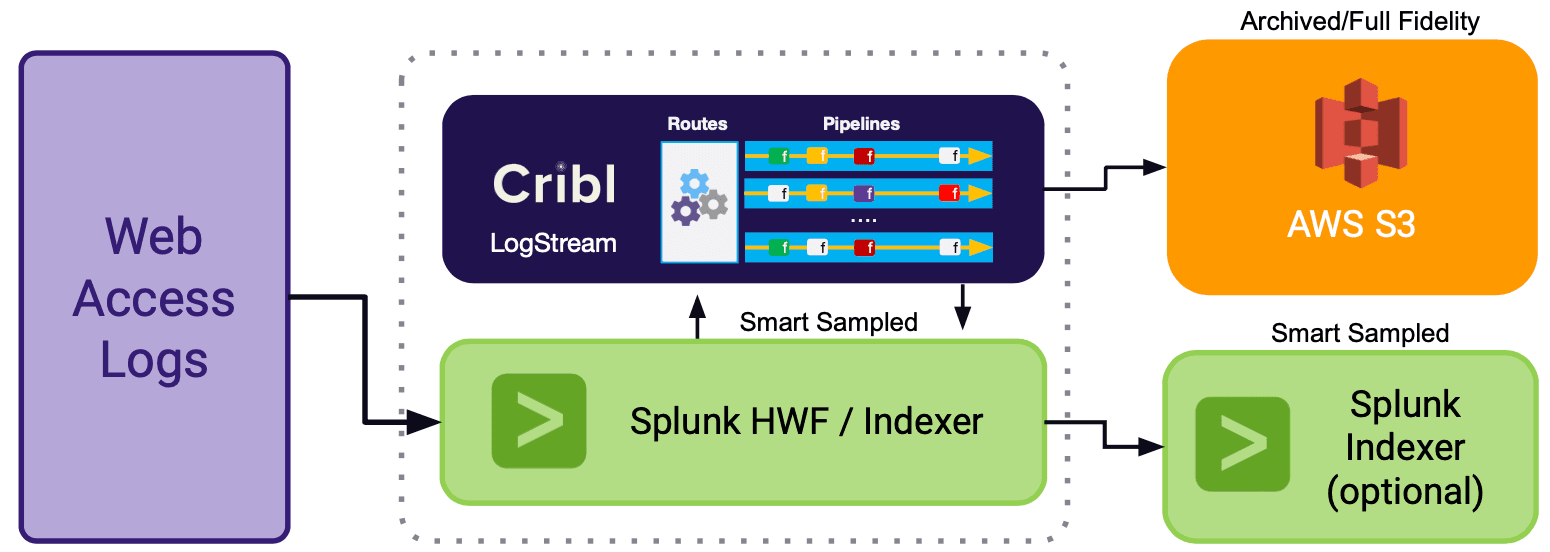
Let’s assume that sampling will be based the following conditions:
__status == 200 && __time_taken < 100 sample at 5:1 (events that indicate successes and request times less than 100ms)
OR
__status == 200 && /static/.test(__uri) sample at 10:1 (events that indicate successes from URIs that serve “static” content like images, etc.)
Note that conditions for sampling can be arbitrary expressions.
Cribl in Action
Create a Route and a Pipeline for full fidelity data destined for S3
Set “Final” flag to “No” so that events continue down to the next Route
Optionally extract fields from events to create partitions in S3 (this is useful for querying later)
Create a Route and a Pipeline for sampled data destined for Splunk
Extract fields for
__uri, __status, __time_takenfrom eventsSample at desired sampling rates
Archival/Full Fidelity Data to S3
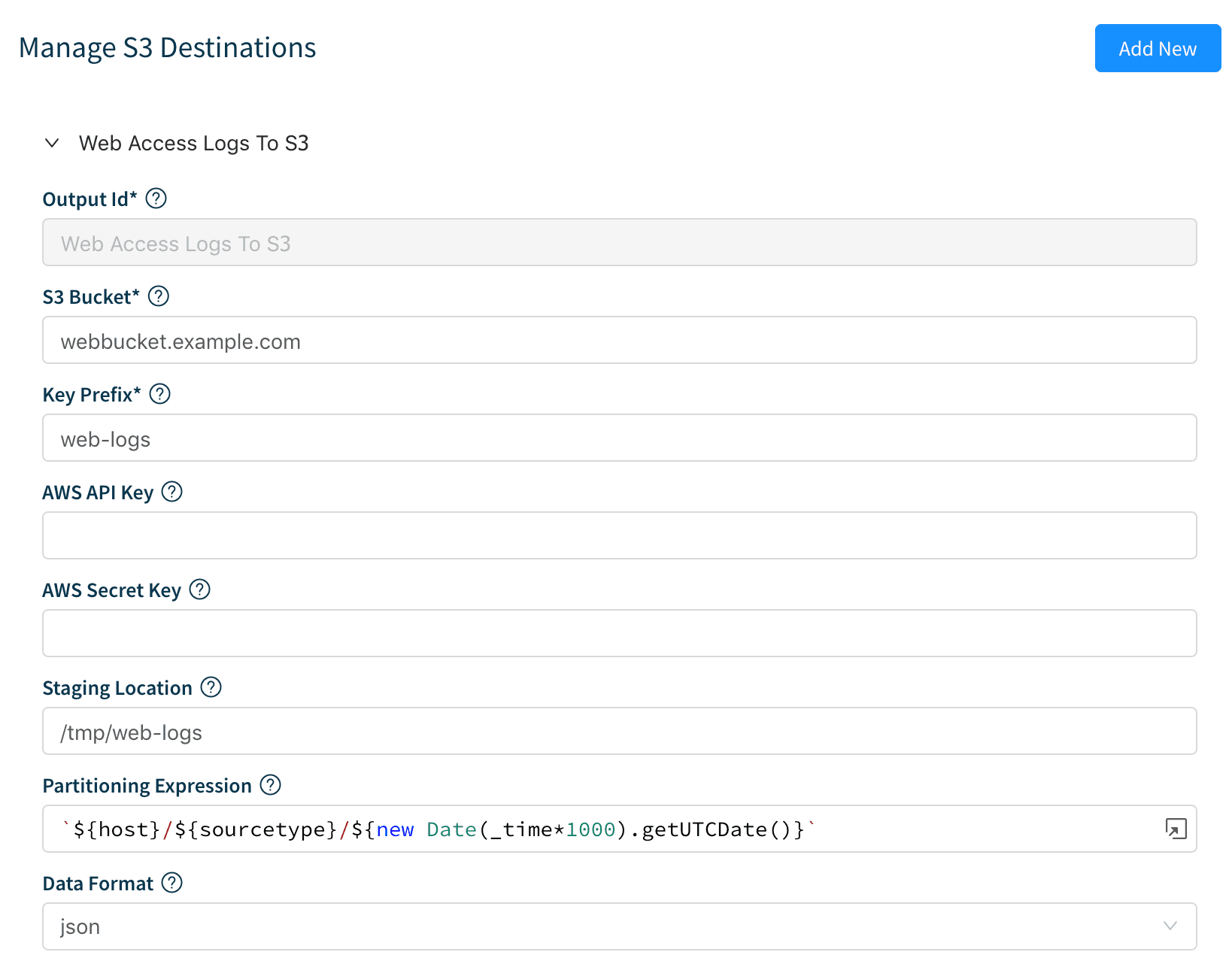
1. First, we create an S3 destination if we don’t have one: Destinations | S3 | Add New. Enter the information as required in the form. Note that if we’re running on AWS and using IAM roles with the right S3 access policies we won’t need to enter API and Secret Keys. We can change Staging Location, Data Format and File Name Prefix as necessary. The Partitioning Expression allows us to define a variable-based expression for our files’ path. We’re using host sourcetype and evaluating today’s date.
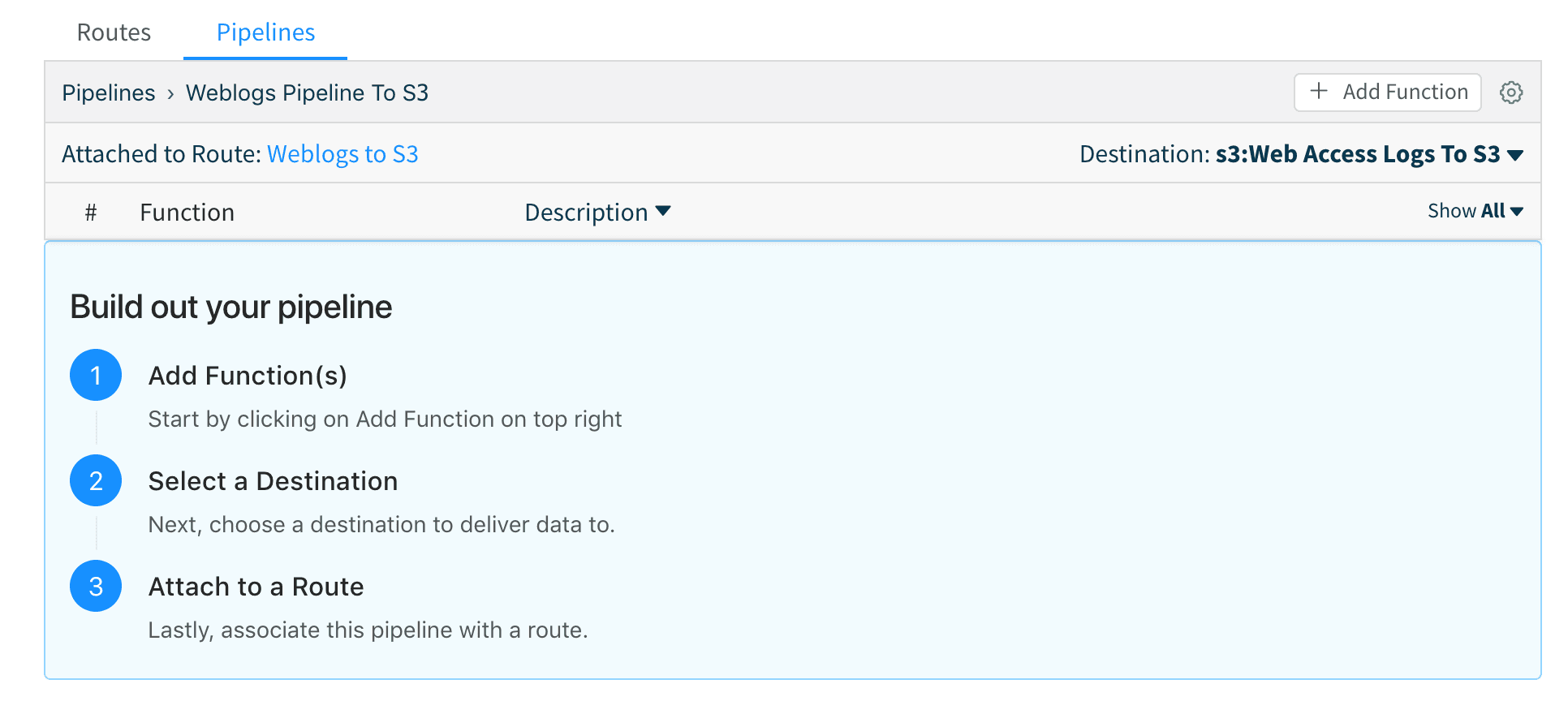
2. Next, we create a pipeline called Weblogs Pipeline to S3 with no functions (remember, we don’t to transform this data) and attach it to the S3 destination we just created above. Save the pipeline.
3. Next, we create a Route called Weblogs to S3 and move it at the top of the stack. We add a filter of sourcetype=='access_combined' , attach it to the Weblogs Pipeline to S3 pipeline, switch the Final toggle to “No” and add a field, say, cloned = yes.
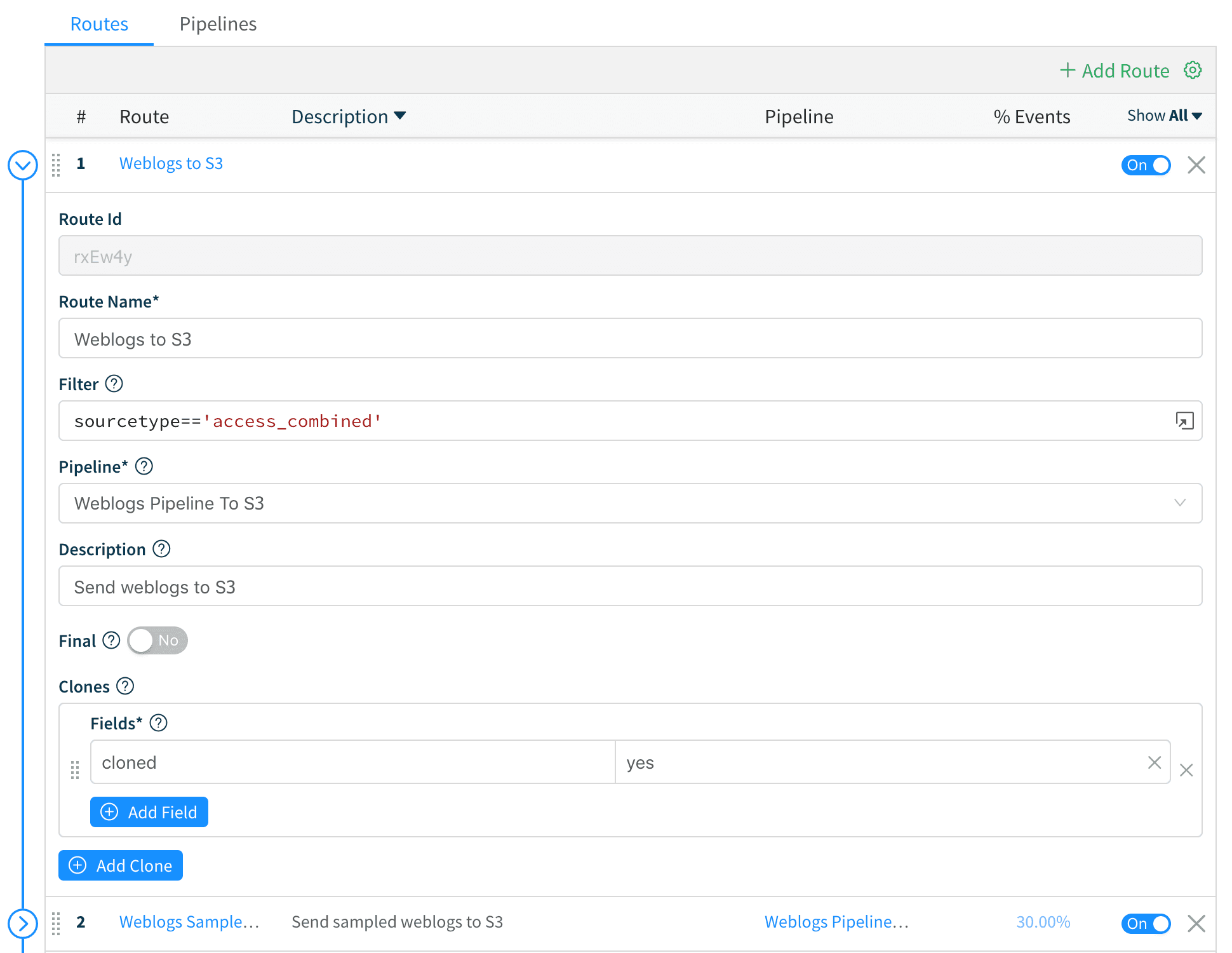
We Save the route and move on to the sampled data stream.
Smart Sampled Data to Splunk
1. First, we create a pipeline called Weblogs Pipeline to Splunk and attach it to our local Splunk destination. Alternatively, we can define a remote one.
2. Next, we use Regex Extract function to extract the necessary fields. We can use the popup expression editor to ensure the extraction for __uri, __status, __time_taken are correct.

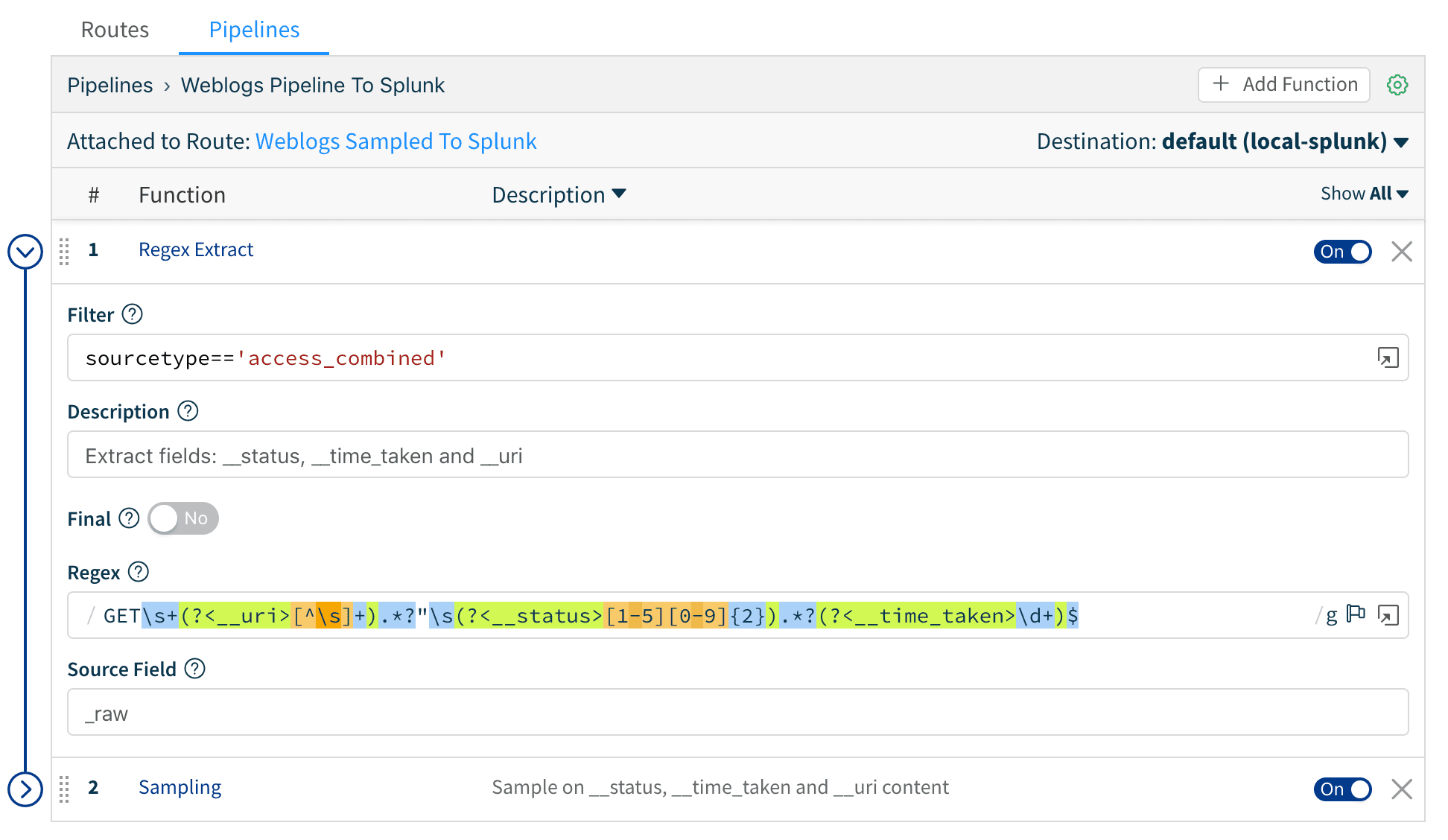
3. Then, we use the Sampling function to apply the sampling rules to web log events. Save the pipeline.
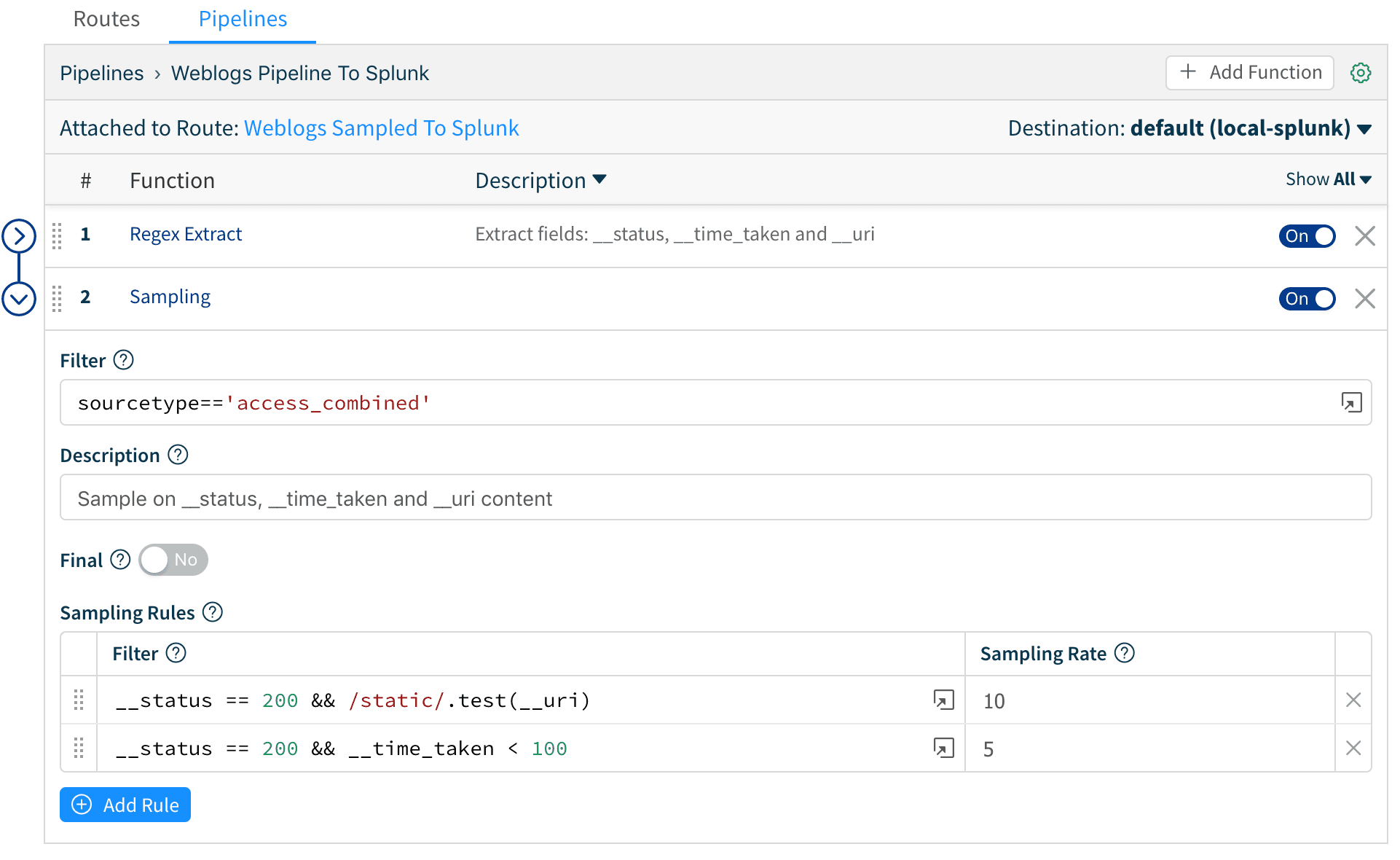
5. Next, we create a Route called Weblogs Sampled to Splunk and move it at position number 2 on the routes stack. We add a filter of sourcetype=='access_combined' , and attach it to the Weblogs Pipeline to Splunk pipeline. We leave the Final switch on its default position so that events are consumed and not passed down to other routes.
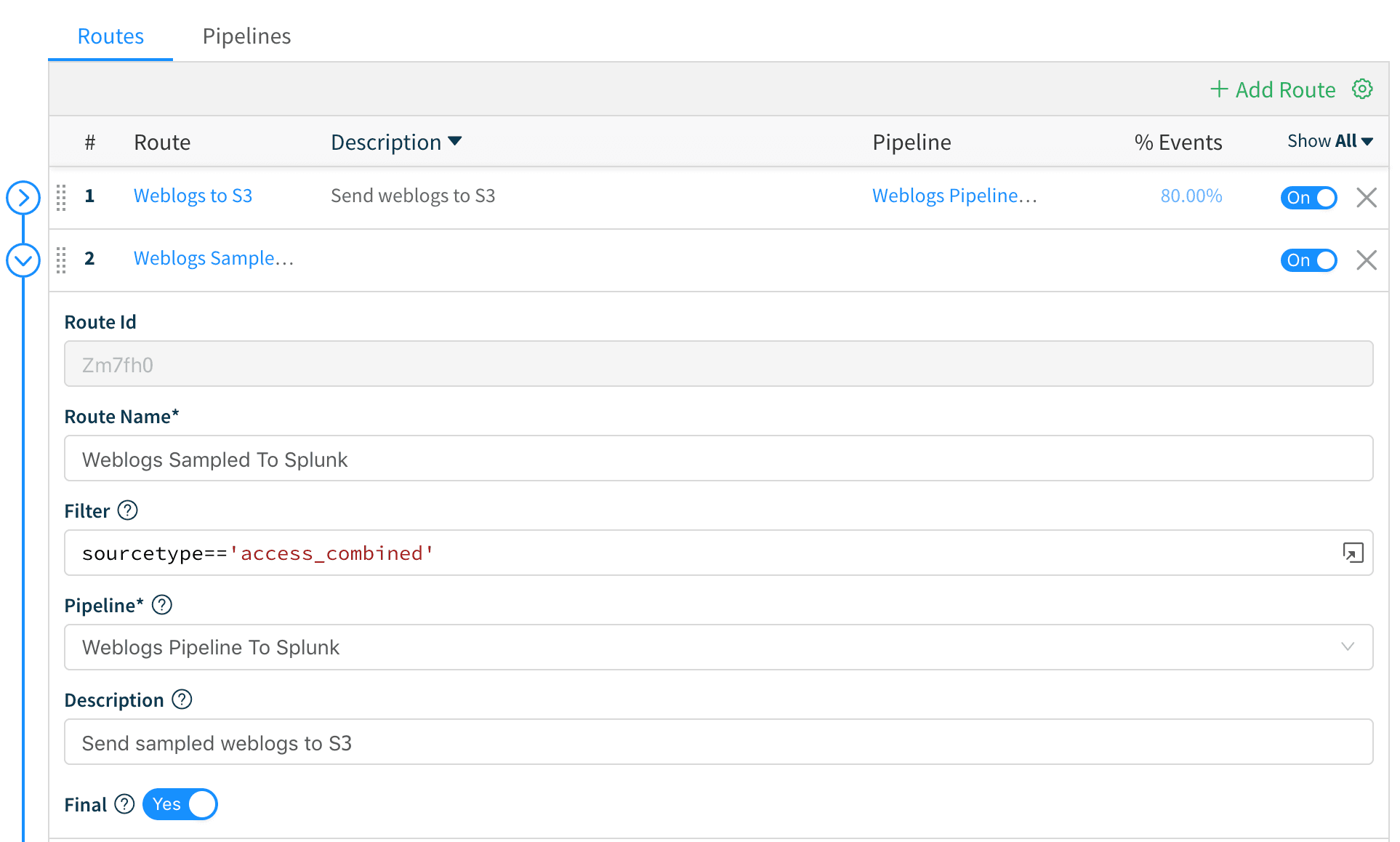
We Save the route and we’re all set.
If you’d like to work with these configurations you can get them for free in GitHub
Candidate Sources
There are a number of log/event source types that will benefit from this technique. Here are a few families of them:
Firewall/Network: Cisco ASA, Palo Alto, Juniper, Meraki, F5 etc.Web Access: Apache, NGINX etc.Proxy: NGINX, Bluecoat, Palo Alto etc.Loadbalancers: F5, HAProxy etc.
Conclusion
Combining routing with sampling achieves the best of both worlds; you can route all your data in full fidelity to a long-term/archival system and route a smart sample of it to your real-time/short term system without losing operational visibility and yet meeting compliance and auditing mandates.
If you are interested in Cribl, please go to cribl.io and download your copy to get started. If you’d like more details on installation or configuration, check out our documentation. If you need assistance, please join us in Slack #cribl, tweet at us @cribl_io, or contact us via hello@cribl.io. We’d love to help or hear your feedback!






