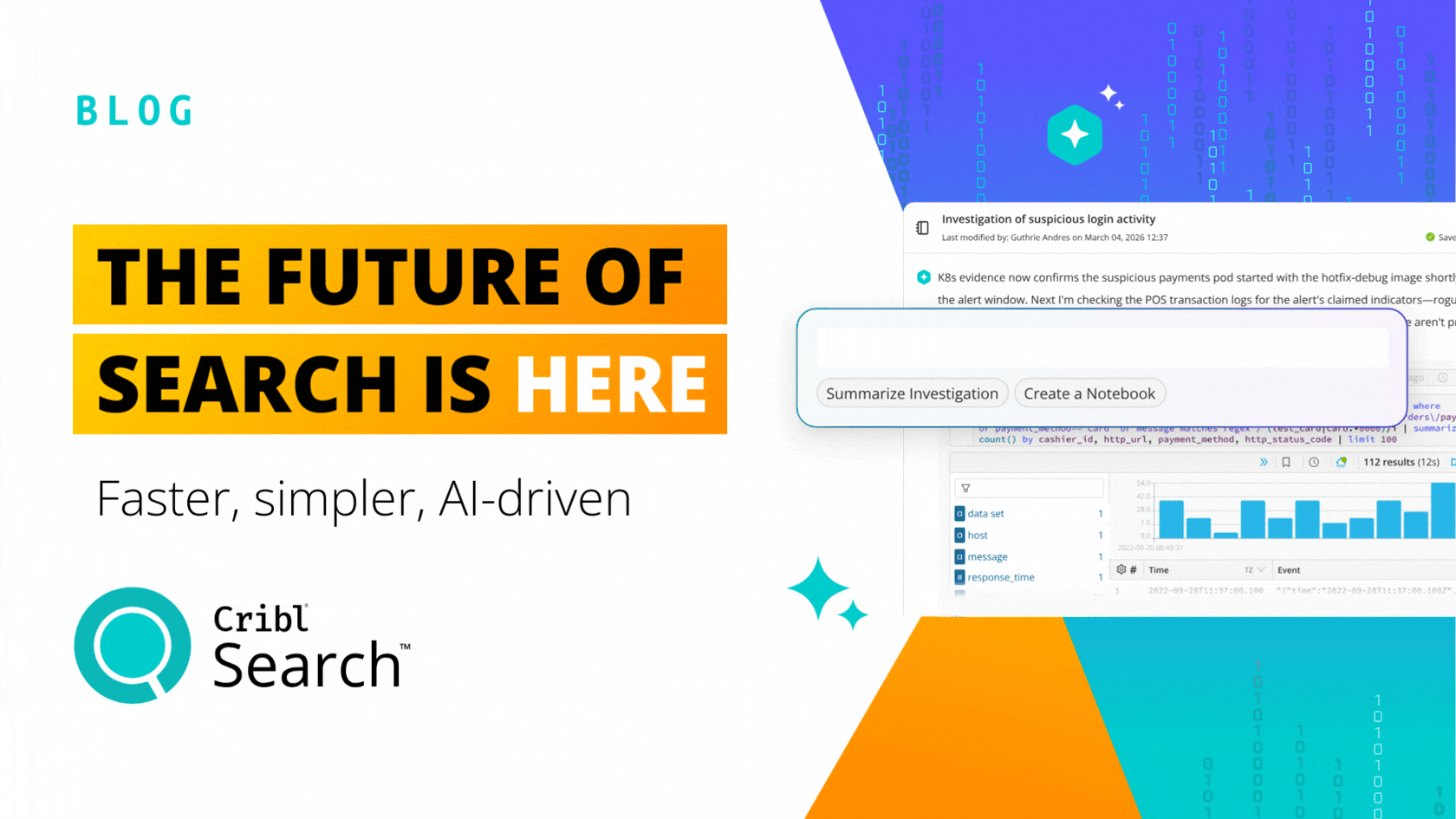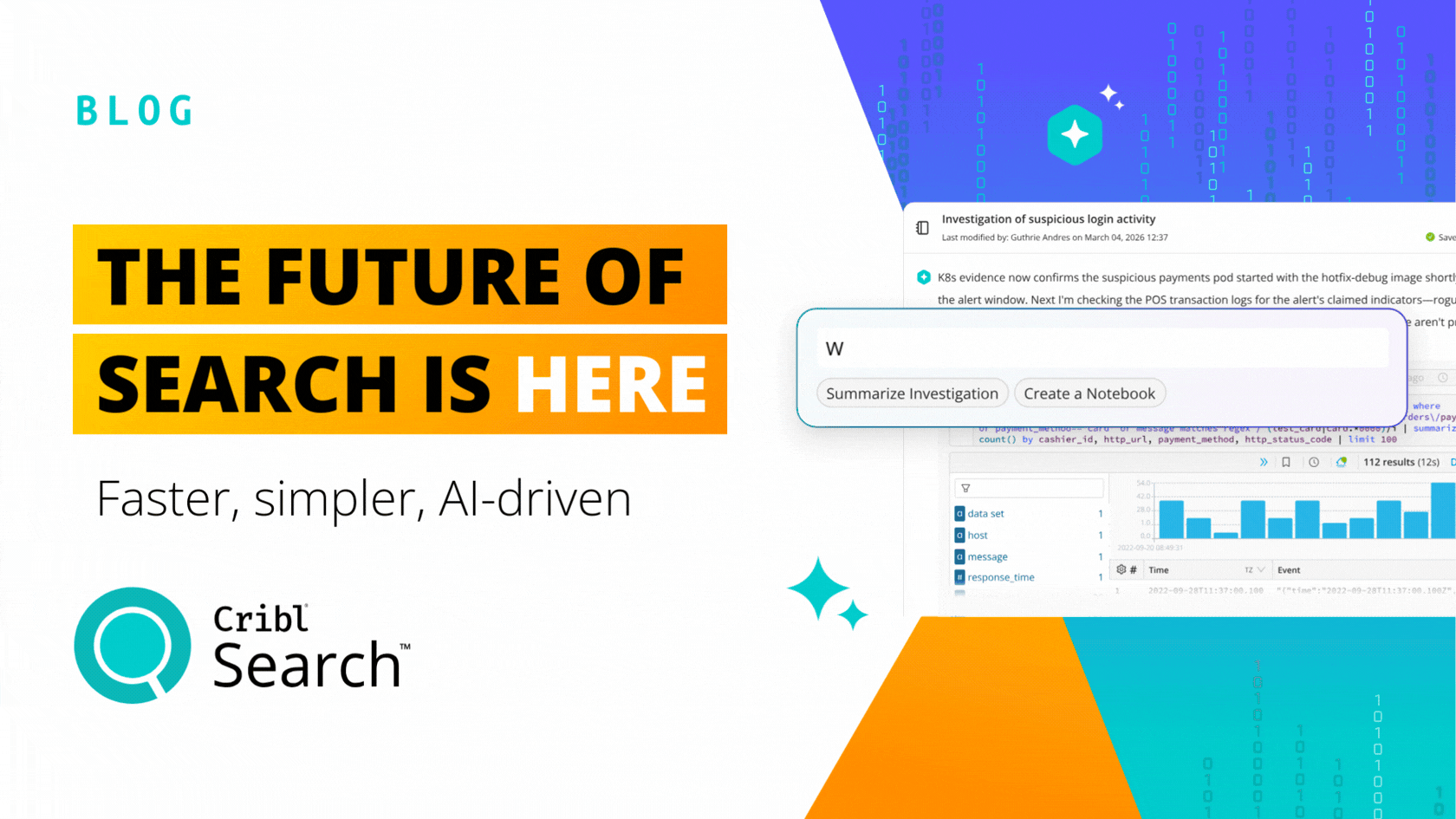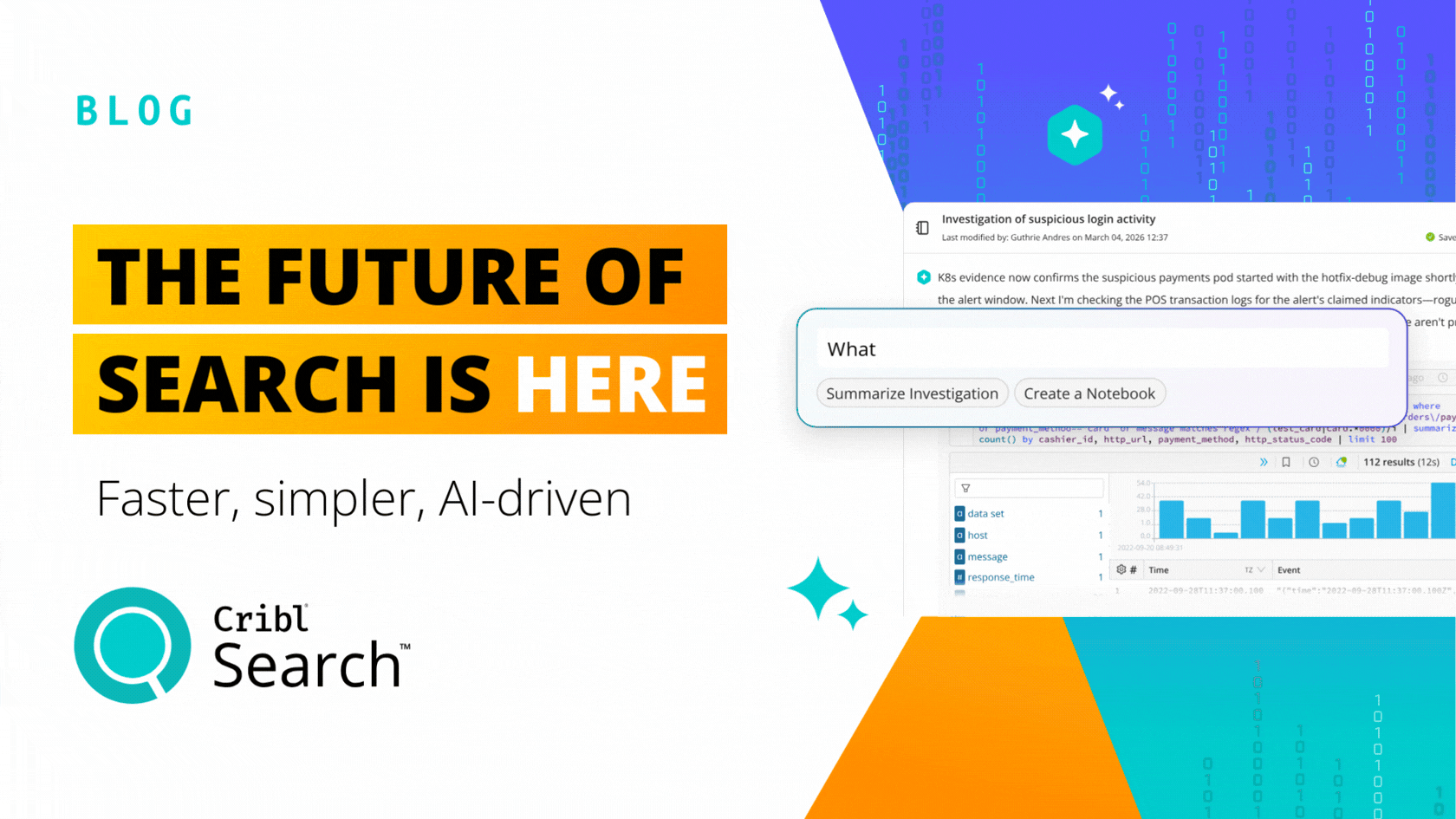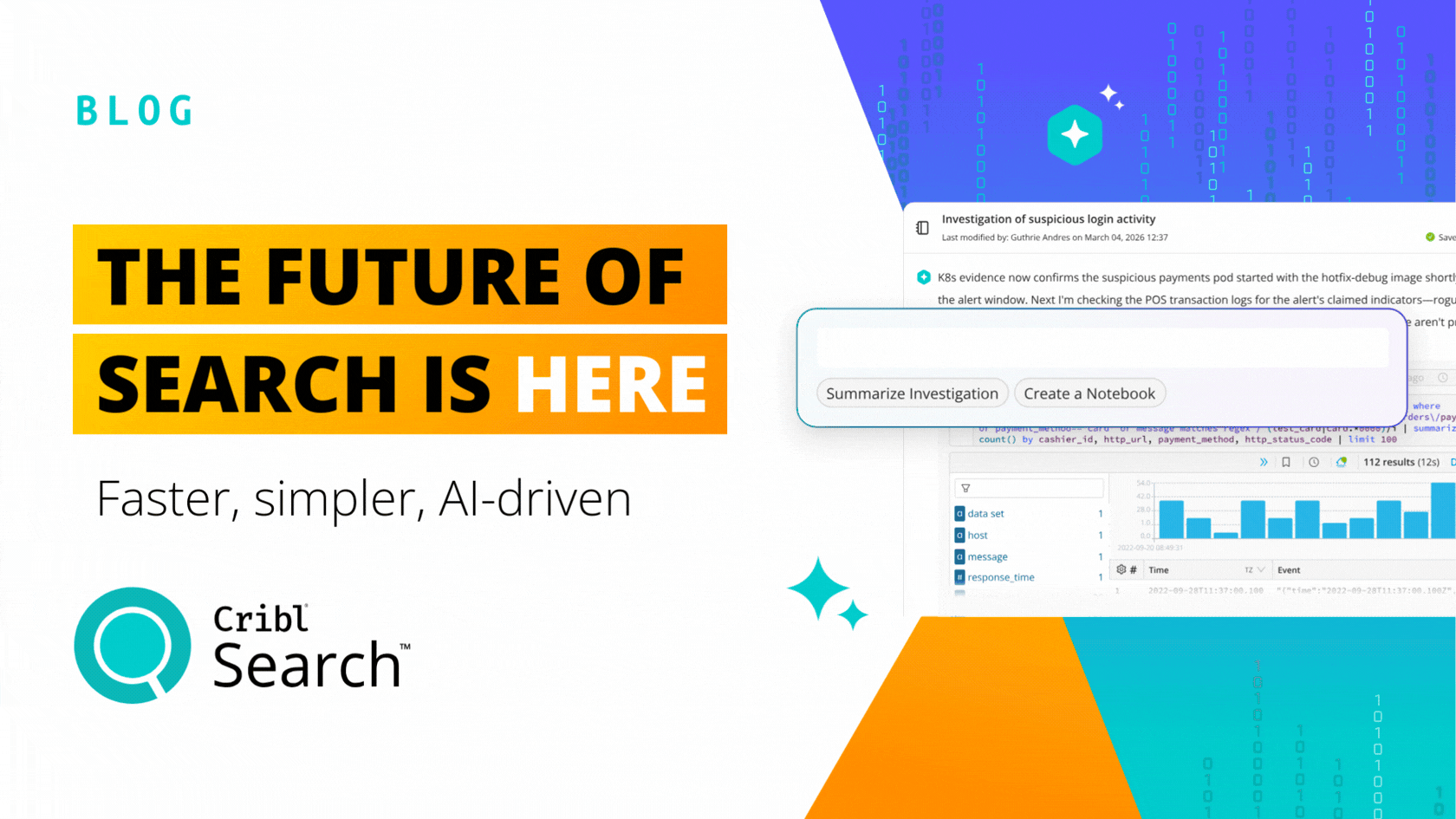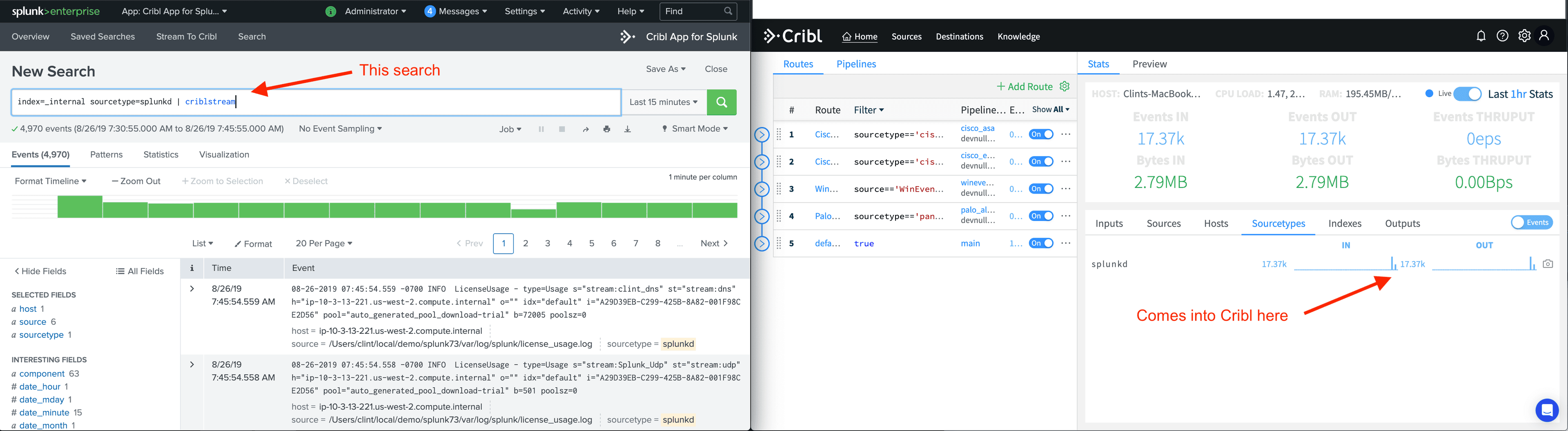

People’s log analysis systems are critical to their day to day work. How do you observe what’s going on in your environment without data flowing into your metrics and logging tools? It’s business critical that production log ingestion pipelines remain logging. Which presents a unique problem for LogStream, because while we give you fundamental new capabilities to work with log and metric data in motion, how do we prove that it works without putting it into your pipeline? Many prospects end up setting up a test environment just for trying us out. LogStream enables you to upload samples so you can work with data that isn’t streaming through LogStream, but the sizes of these are limited and it’s up to you to download an extract from something like Splunk and upload to us. We wanted to make it easy for Splunk customers to try out working with their data in LogStream without having to first put us in their log pipeline.
We’re solving this problem with the release of Cribl LogStream 1.7. With our Cribl App for Splunk package, we are now including a new Splunk search command, criblstream, which will send data to Cribl (by default on the same machine). You can now use the data you already have at rest in Splunk to stream over and work with in Crib, and see how we can transform, sample, suppress, and aggregate information without having to put us in the pipeline first. This is also an excellent way to feed data to Cribl for testing of your pipelines before you configure a route to run data through that pipeline.

In addition to our new Splunk search command, we’re also releasing a highly requested feature: Persistent Queues. If a destination is unavailable, you can configure Cribl to spool data to disk until the destination comes back online. This is especially important for more ephemeral data producers, like Splunk’s HTTP Event Collector or Syslog, as those producers often do not retry if the destination is unavailable, or in the case of UDP syslog, have no way of knowing. In addition to Persistent Queueing, we’re now also shipping Cribl as a statically linked binary which includes the NodeJS runtime, a slew of routing enhancements, and a few other features. Let’s review the new features in more detail.
Splunk Search Command
If you install the Cribl Splunk App, you’ll now get a new search command called criblstream. criblstream allows you to take the output from any search and send it over to Cribl via our TCPJSON protocol. Now, you can easily shuffle any data you have at rest in Splunk over to Cribl. Cribl can be configured to output that data back to Splunk, or anywhere Cribl can output data. Do you want to see how Cribl lays out data in S3? See what it’s like to output to Elasticsearch? It’s easy to take any data you have in Splunk and use Cribl to route it anywhere, although you won’t be able to move more than around 200 GB of data a day with today’s implementation.
Using criblstream paired with Cribl’s Aggregation function, its trivial to estimate the size of datasets before and after cleaning out noisy data. We can output data back to Splunk for easy query, so you can see if the transformations break any your existing apps before putting us in the pipeline. You can even try out Cribl’s encryption functionality, and the decrypt command will work out of the box.
Persistent Queueing
New in LogStream 1.7 is the ability to spool data to disk in the event a destination becomes unavailable. By default, Cribl supports backpressure, so for agents like Splunk’s Universal Forwarder or Elasticsearch’s Beats agent, they will back off sending until the destination is again accepting data. However, ephemeral producers of data like Syslog (especially over UDP), or HTTP based transport mechanisms, often don’t support backpressure behavior and so data loss can occur if a remote system is unavailable. In LogStream 1.7, you can now configure persistent queueing for a given destination. After we detect that a given destination is unavailable, we will begin spooling data to disk. This is especially helpful in systems where backpressure is a regular occurrence. Persistent queueing can help minimize data loss.
Native Binary
As pointed out in our recent blog post, Going Native, by our CTO Ledion Bitincka, we’ve open sourced a new project called js2bin which we’re using to compile Cribl into a statically linked binary. Note, this impacts our packages, so when you go to download the newest version of Cribl, you’ll need to pick what platform you want to download. As of LogStream 1.7, we no longer depend on NodeJS, so no more having to figure out the best version of Node to run! Over time, this will also allow us to move some code off into C++ for better performance and you won’t have to worry about compiling node native modules on whatever platform you happen to be on.
Routing++
This release, we’ve added a number of enhancements to routing, almost all driven directly by customers pushing the boundaries of our current UX. Firstly, and simplest, you can now insert routes easily via contextual menu anywhere in the list. Next, you can now group routes in the UI. This is purely cosmetic, but it can really help declutter a route list growing into the dozens of routes. Lastly, we’ve added a new output type called the Output Router, which allows you to defer the routing decision to the end of the pipeline. With an Output Router, you can output to multiple destinations from a single pipeline, or choose the right destination based on a filter expression which matches against the event. One of our customers real world use case was to be able to choose which Splunk cluster to send data to based on a tenant ID they had embedded into the event.
Other Features
Also in this release is a new Serializer function. Similar to our Parser function, this allows you to take an object and serialize it out to a field in a number of formats, like JSON, CSV, etc. Additionally, we’ve now added capture icons throughout the UI so it’s easier than ever to capture data coming from just a particular Input, Sourcetype, etc.
That’s it for 1.7! Check out the Release Notes for more detail. Head to our website to download the latest.