

CrowdStrike is a class-leading endpoint monitoring solution. It collects a wealth of activity data from each managed endpoint that can be fairly voluminous. This includes network connectivity, DNS request, process activity, health checks, and the list goes on. In fact, there are over 400 event types reported by CrowdStrike! These events are a gold mine for threat hunters and blue teams looking for unusual or malicious activity. It can be extremely costly to place all this data in a SIEM. Cribl offers a much more cost-effective solution by giving you the choice to send a full-fidelity copy of these logs to a cheap object storage data lake, and the SIEM-worthy events to a SIEM.
The Cribl Pack for CrowdStrike addresses the common challenges of processing all this data. The end result is asset level enrichment (e.g. Computername from aid field) & 40-95% reduction in data volumes sent to a SIEM. The reduction isn’t just a matter of dropping unwanted events, but a combination of:
aggregating network events
removing DNS requests mapping to top 5,000 popular websites
dropping unwanted events based on event_simpleName field value
removing unwanted fields
removing null fields
removing duplicate fields
sampling noisy ‘External API’ events
The screenshot below shows samples of various reduction amounts by event type.
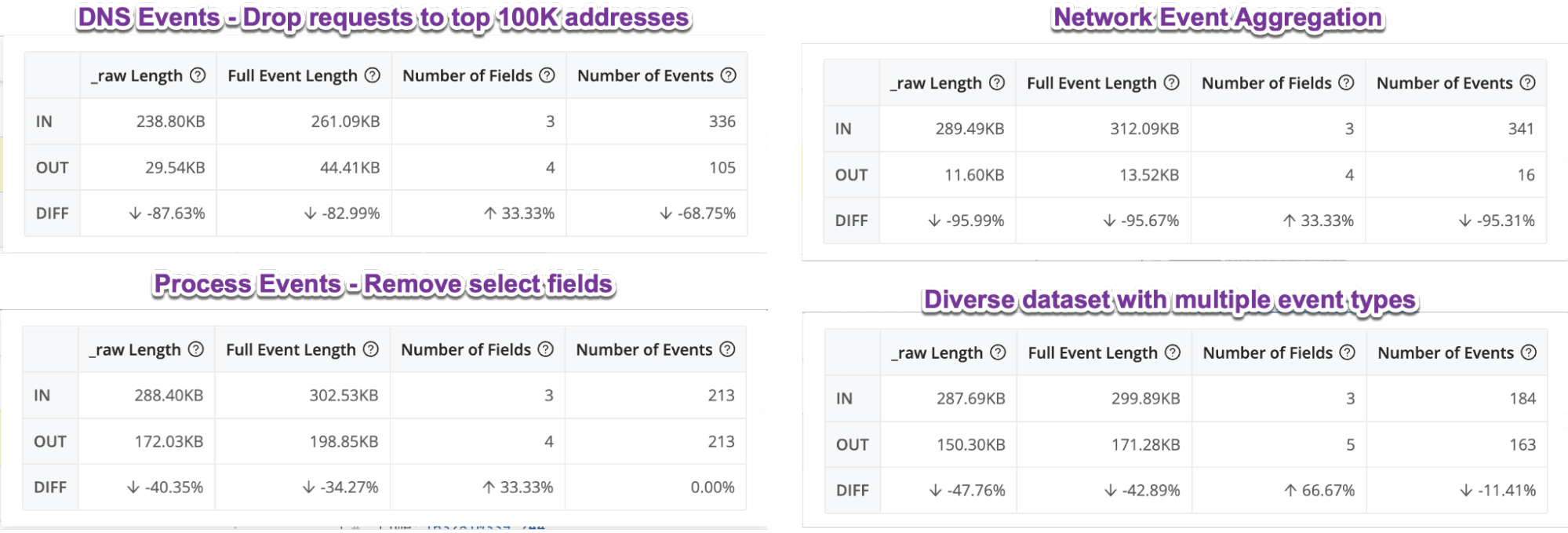
The pack includes sample files and instructions. If you’d like, you can even take the pack for a test drive by signing up for a Cribl.Cloud account, installing the pack, and reviewing how the data is shaped using the sample data preview features in Cribl Stream on those sample files.
The below diagram illustrates the pack workflow. The pack optionally uses Redis for enrichment as well as stateful aggregation across worker processes. I found this blog useful for installing Redis quickly on my Mac. You will additionally need a UI, as one isn’t provided with Redis. This blog lists some available packages. I used Redis Commander.
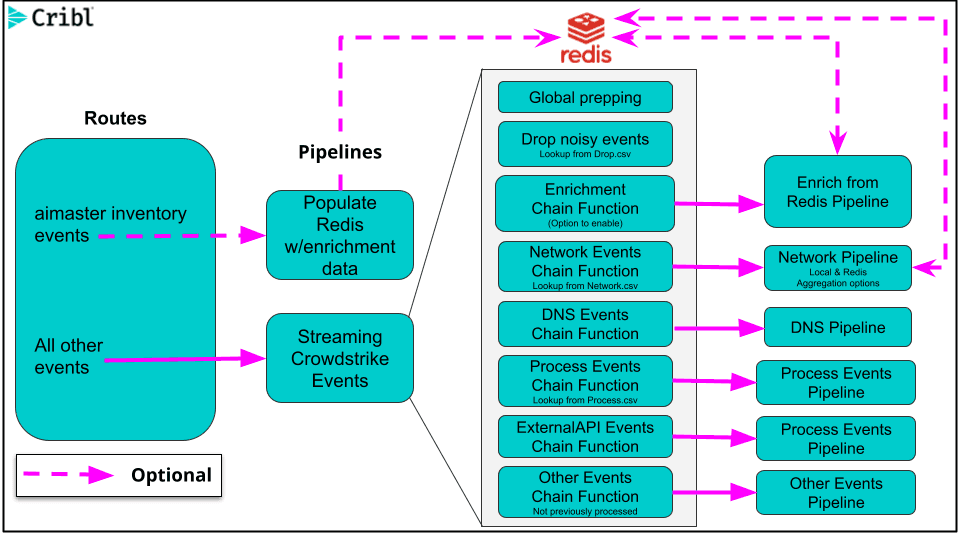
In the remainder of the blog, I’ll cover some of the typical setup including:
Capturing data from CrowdStrike FDR
The CrowdStrike Pack is designed to work with Falcon Data Replicator logs written to the CrowdStrike provided S3 bucket. Contact your CrowdStrike team to obtain access to Falcon Data Replicator. When setup, you will be provided an SQS queue URL and S3 bucket URL, an access and secret key. WIthin Cribl, you will need to configure a CrowdStrike source with this respective information. Be sure to select ‘Commit’ and ‘Deploy’ for the changes to take effect.
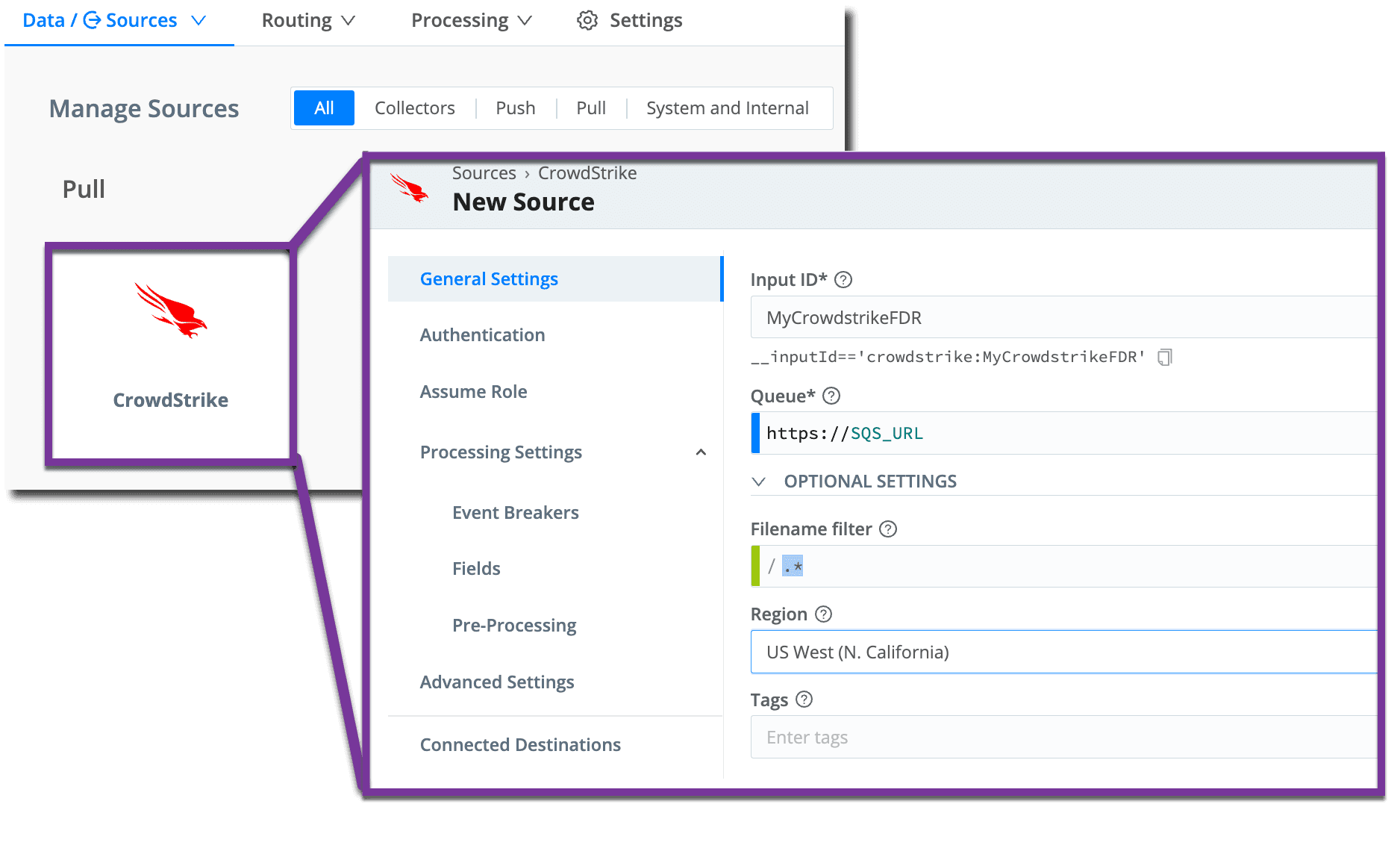
Note: You can configure either a CrowdStrike source or an ‘Amazon S3 pull source’ in Cribl. Do NOT configure an S3 Collector.
Enabling the Processing You Want
And disabling what you don’t want….
As illustrated in the diagram above, there is one master pipeline that processes all streaming CrowdStrike events. Within that pipeline are various chain functions with filters. To enable/disable any processing, merely toggle the on/off button. For example, if you don’t have Redis, ensure the Enrichment chain function is turned off as in the screenshot below.
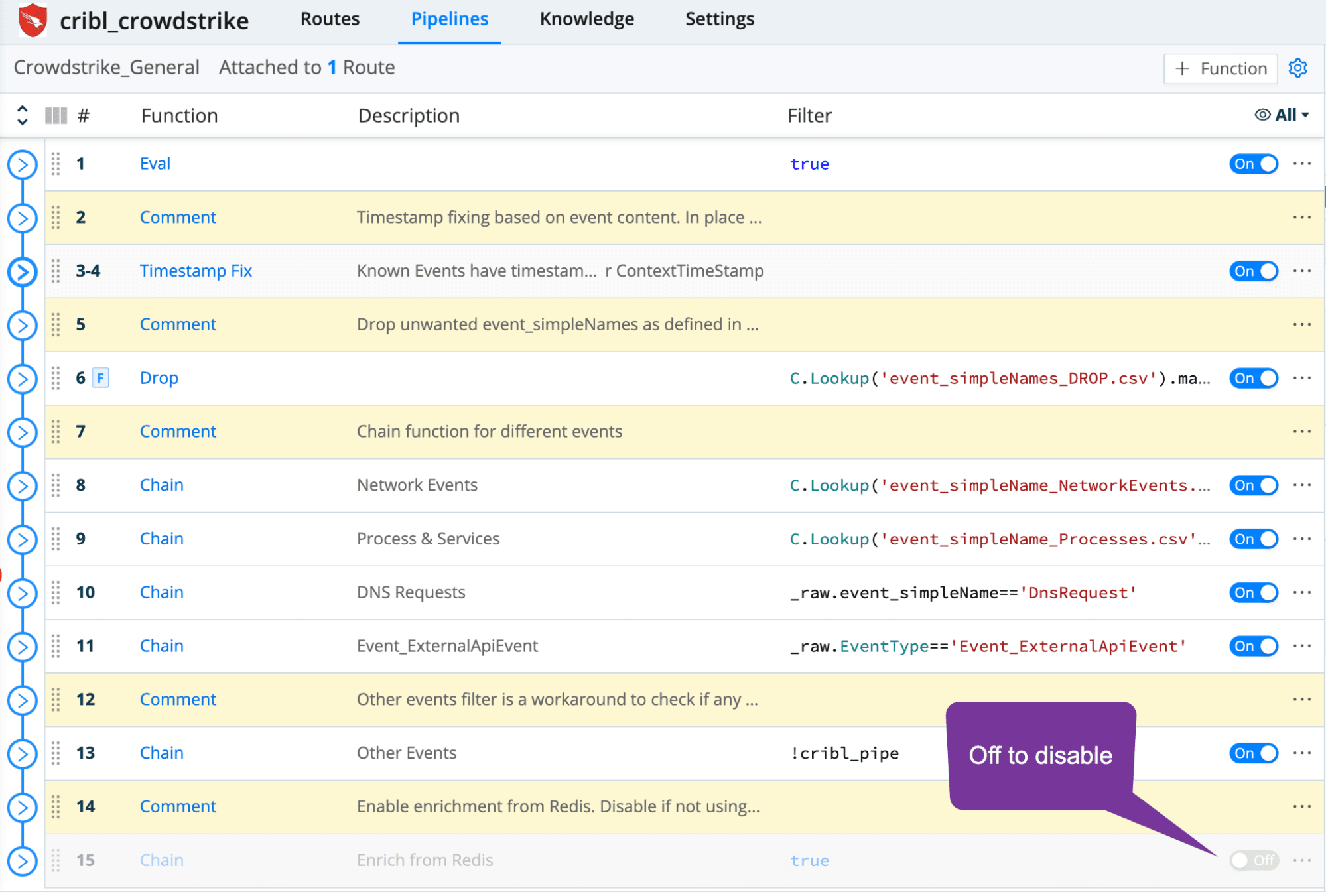
Dropping Unwanted Events
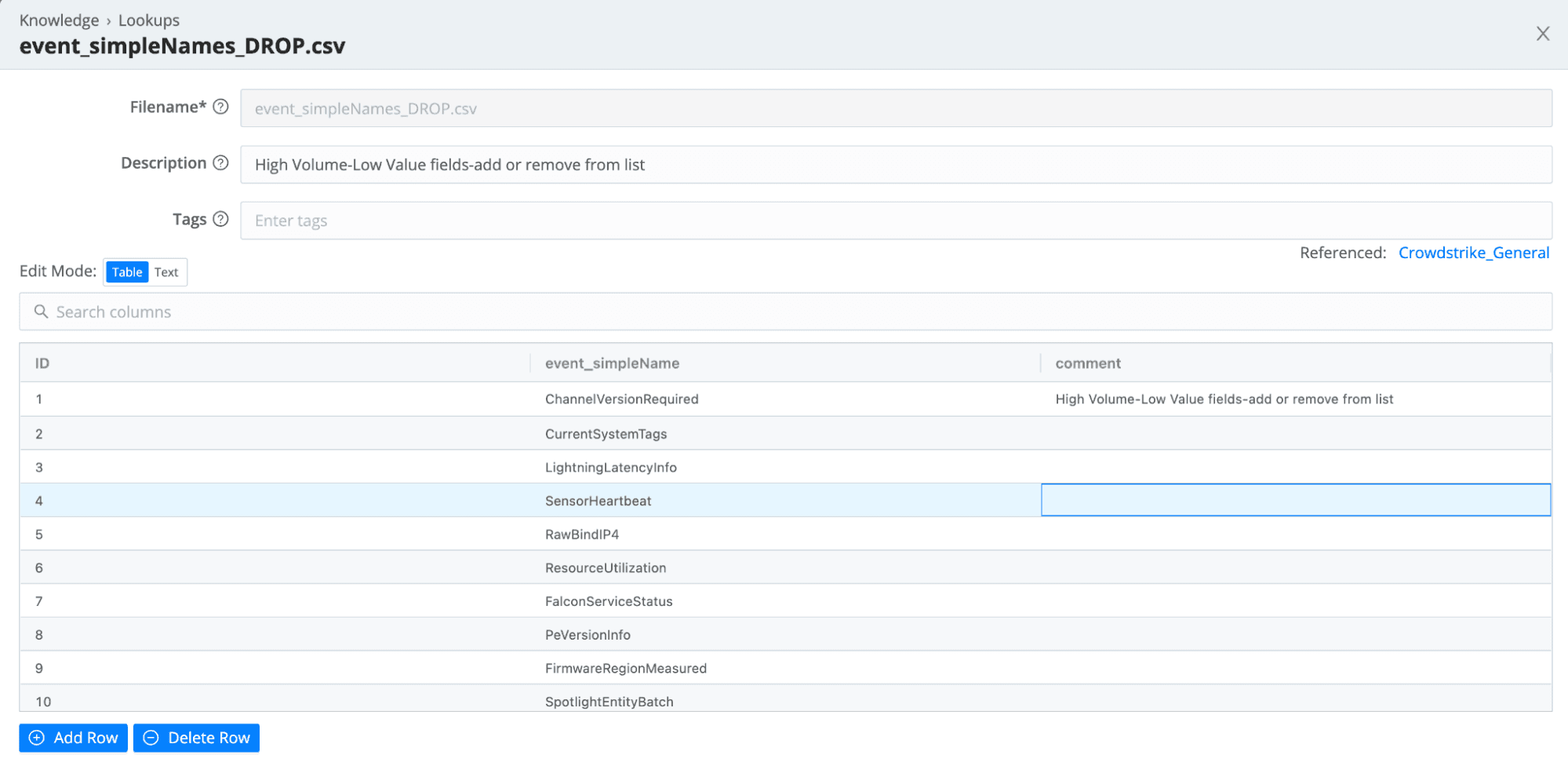
One of the first things you’ll likely want to do is control which CrowdStrike events are kept and which are dropped. To simplify this process, the pack ships with a lookup containing event_simpleNames values to drop. The pack’s main pipeline, CrowdStrike_General has a section to drop any matching events.
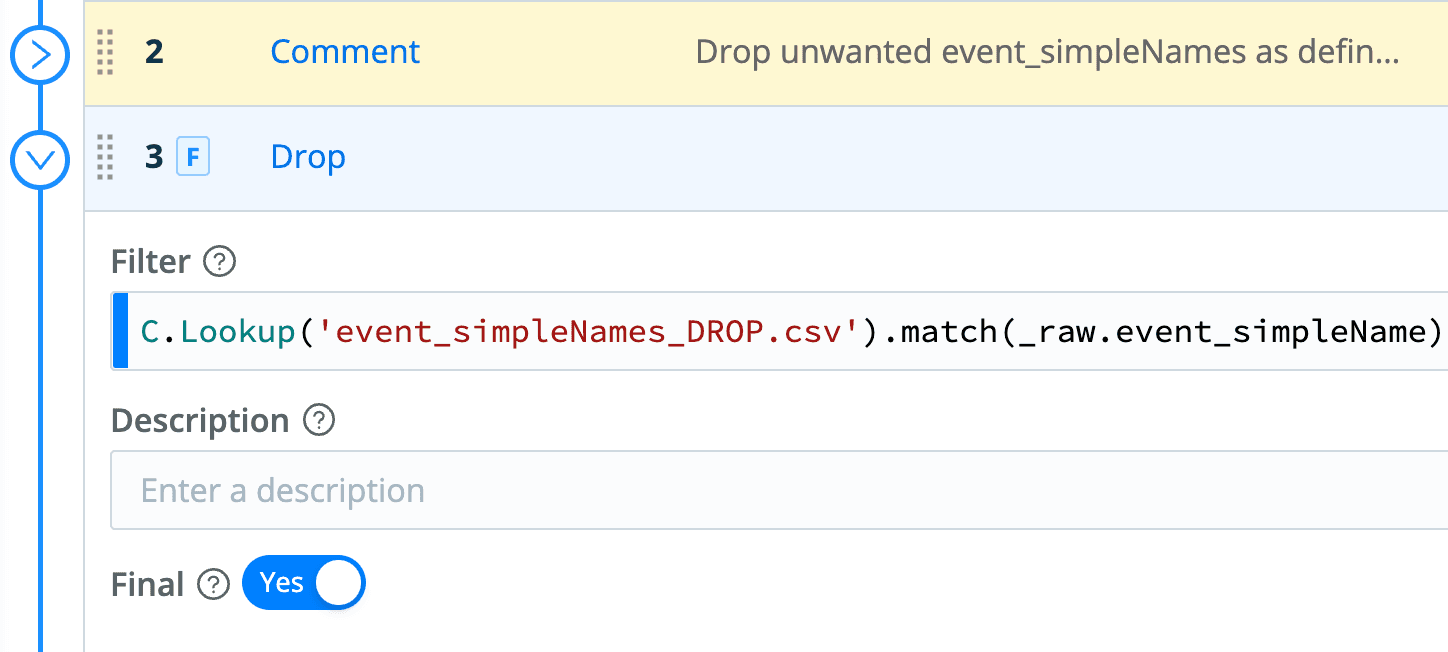
To control the list of events being dropped, access the ‘Knowledge’ section within the pack and navigate to lookups. You can directly edit the lookup within the Cribl UI and add or drop rows.
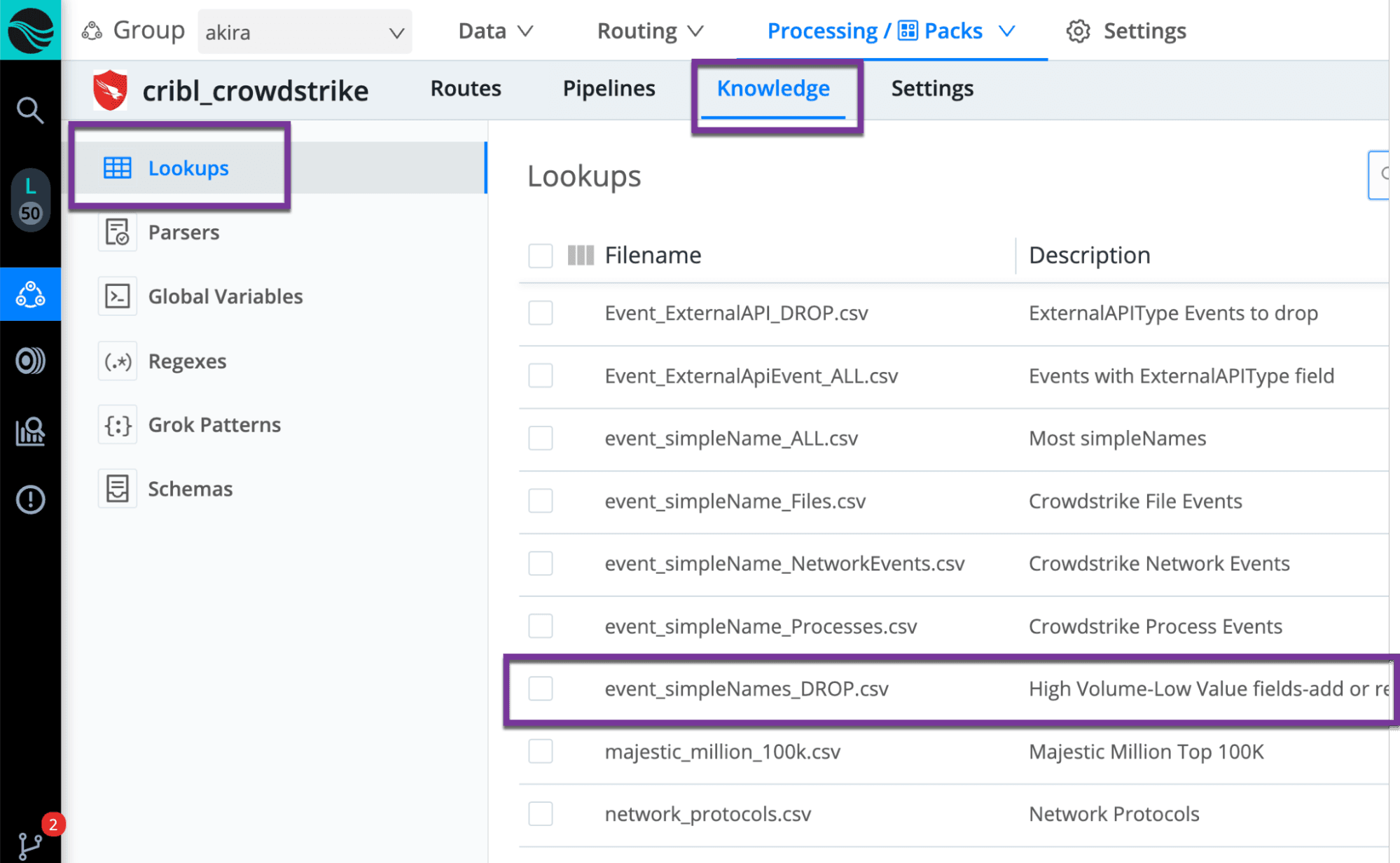
Validate with your security analyst team on whether to keep the list as is or modify it
Enriching Computer Names in Events
Enrichment is valuable as the streaming CrowdStrike events only include a computer id as the ‘aid’ field. The actual Computer Name or hostname is not populated in those events.
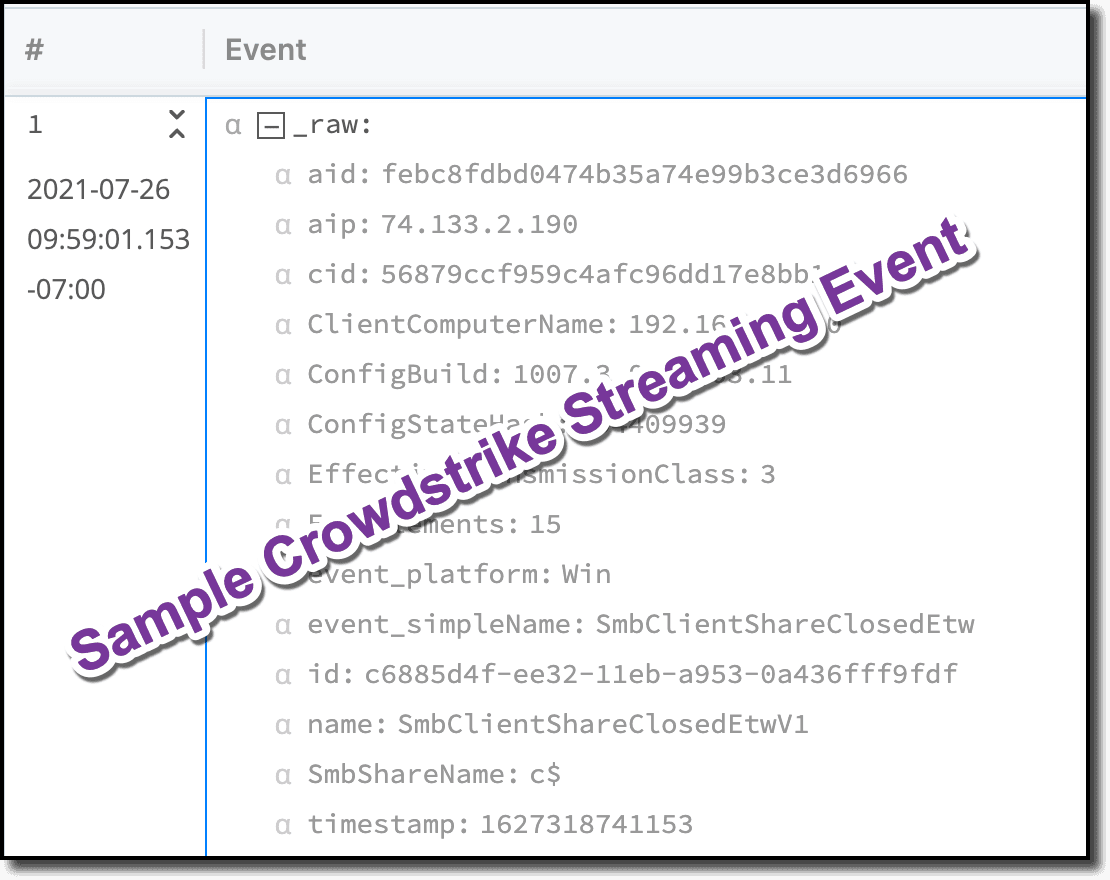
Instead, CrowdStrike exposes inventory information in separate events that are typically published nightly.

Because of the nature of how this information is sent, Redis is required for Cribl to enrich the computer name and/or other asset information in each streaming event. Here’s a short video illustrating how Cribl works with Redis. To enable this functionality:
1. Stand up a Redis server (Tutorial)
2. Edit the Inventory_Events_Redis pipeline within the pack. Update the Redis URL and create a user or admin password that you’ll be able to reference in all other Redis functions.
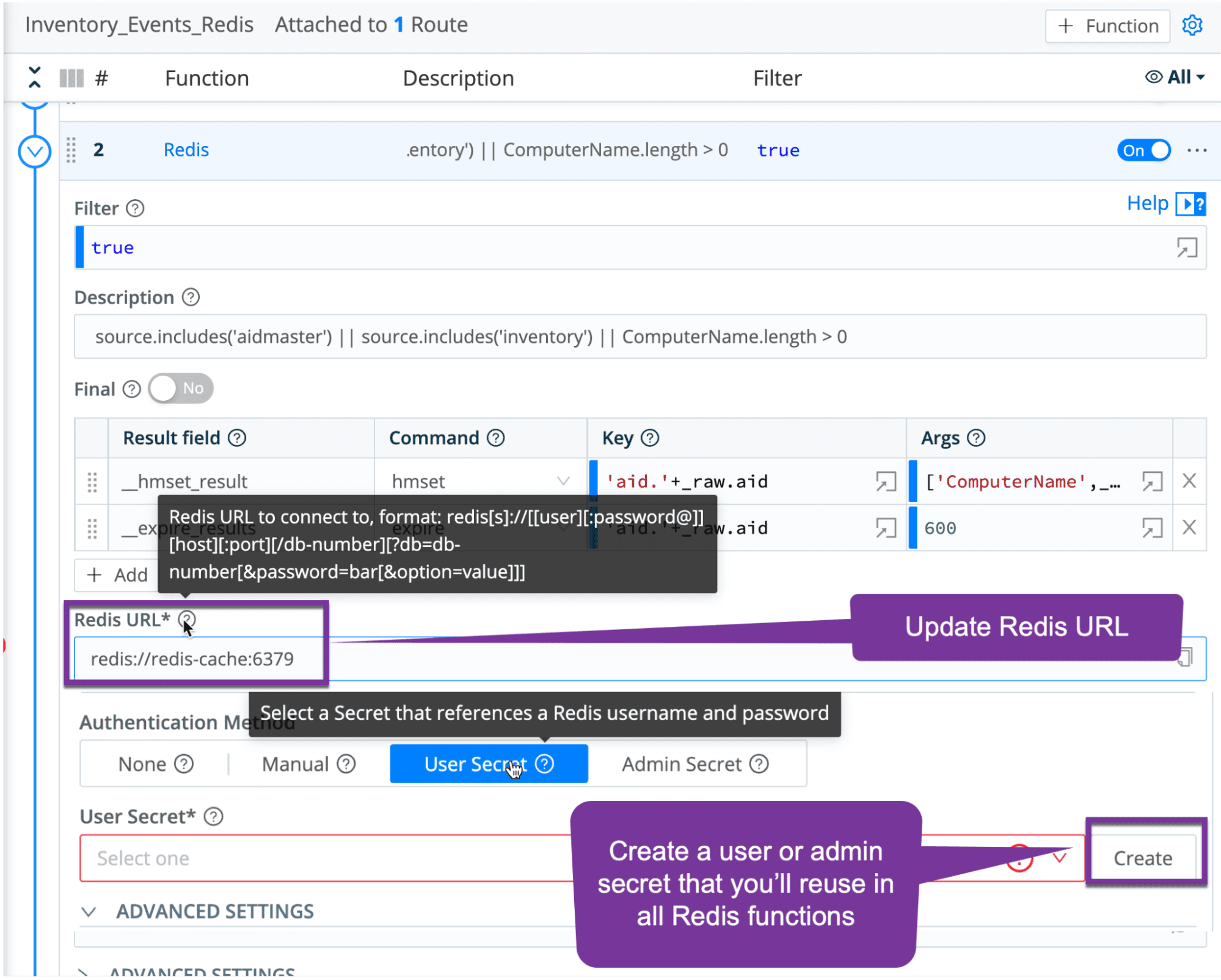
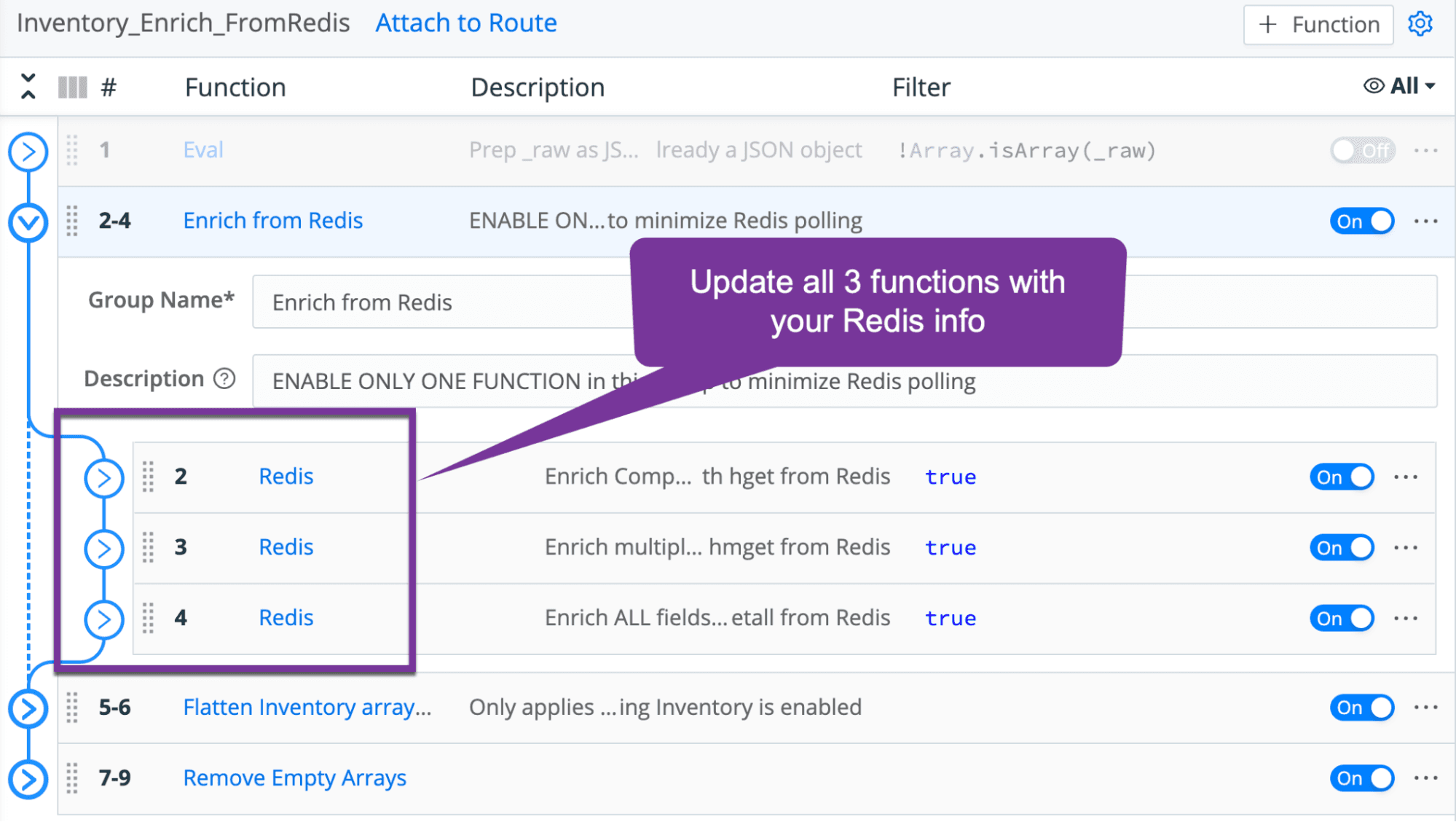
3. Update the Redis settings for each function within the Inventory_Enrich_FromRedis pipeline
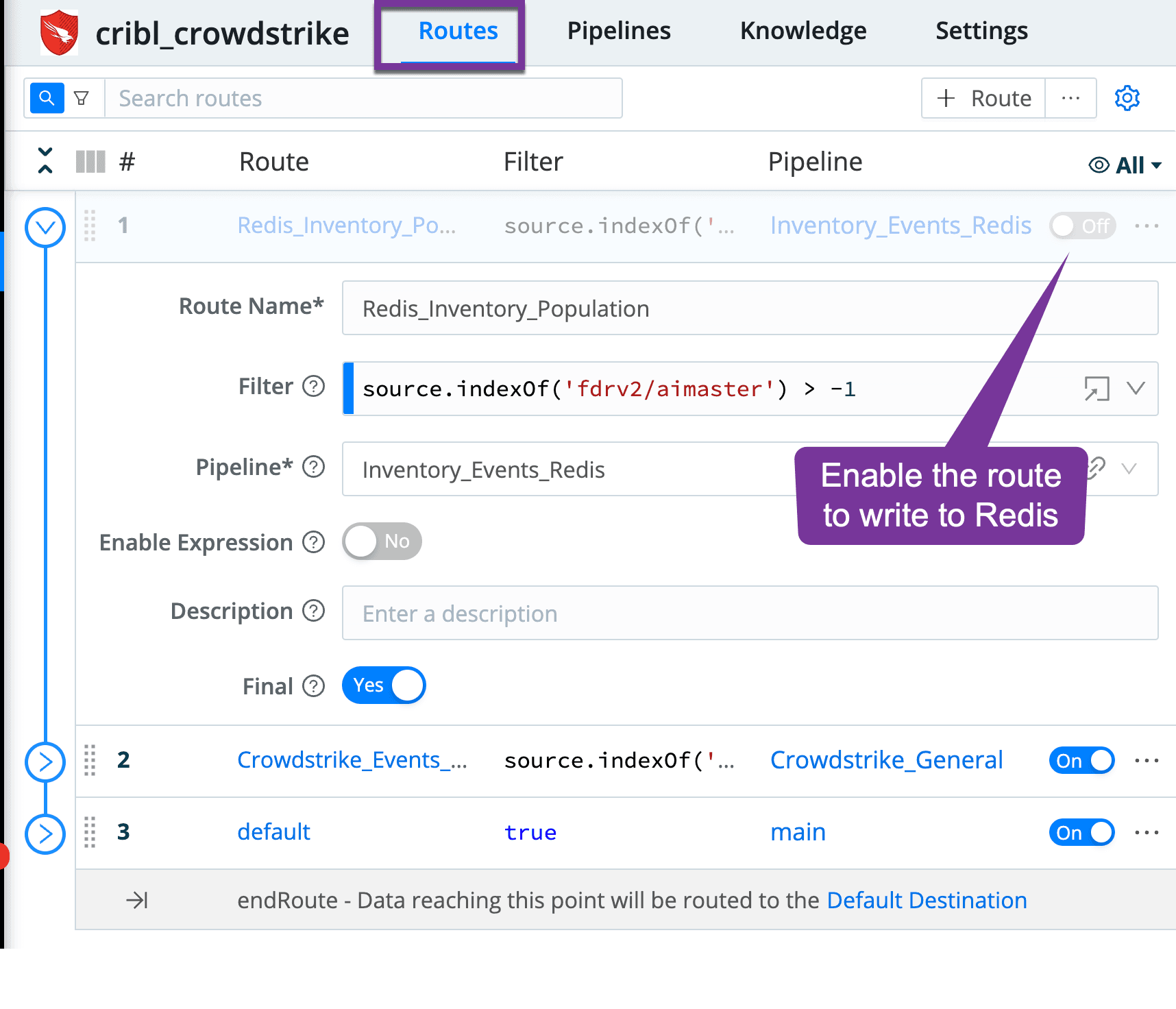
4. Enable the route (within the Pack) to have inventory events written to Redis
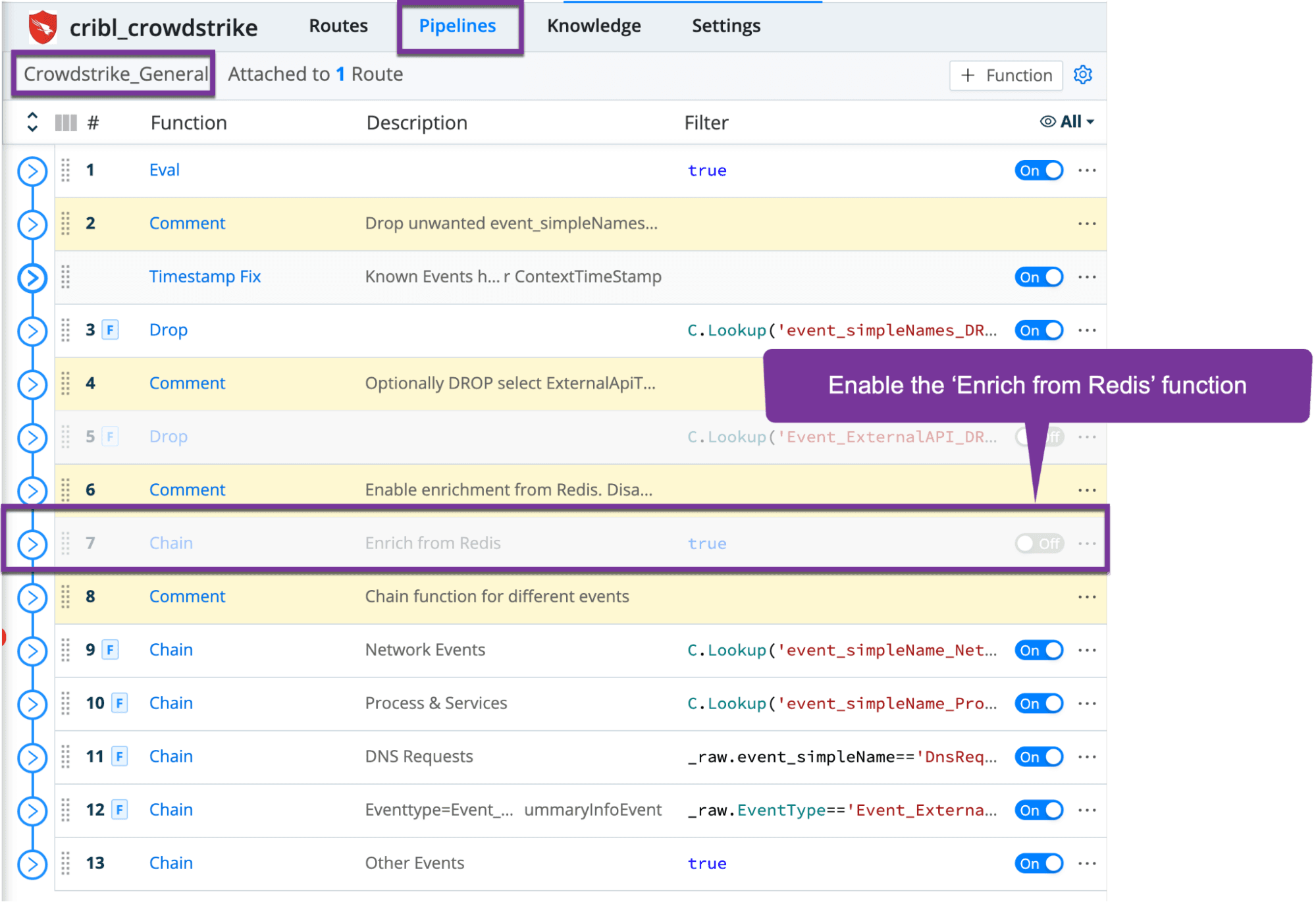
5. Enable the function that enriches from Redis (note that location in latest pack might be different from screenshot)
By default, all contents of the CrowdStrike inventory event are populated in Redis and are available to be enriched. However, if all you care to enrich is computername, it would be wise to update the Redis population pipeline to only write those fields into Redis. For enrichment, there are 3 enrichment options to enable, but only one should be enabled. You can enrich only the computer name field, enrich a set of fields that you control, or enrich all available fields. This is exposed as different functions in the Inventory_Enrich_FromRedis pipeline.

If you desire to control which fields are enriched, edit function 3 and add the desired fields to the Args section. Maintain the same format with comma and single quotes.
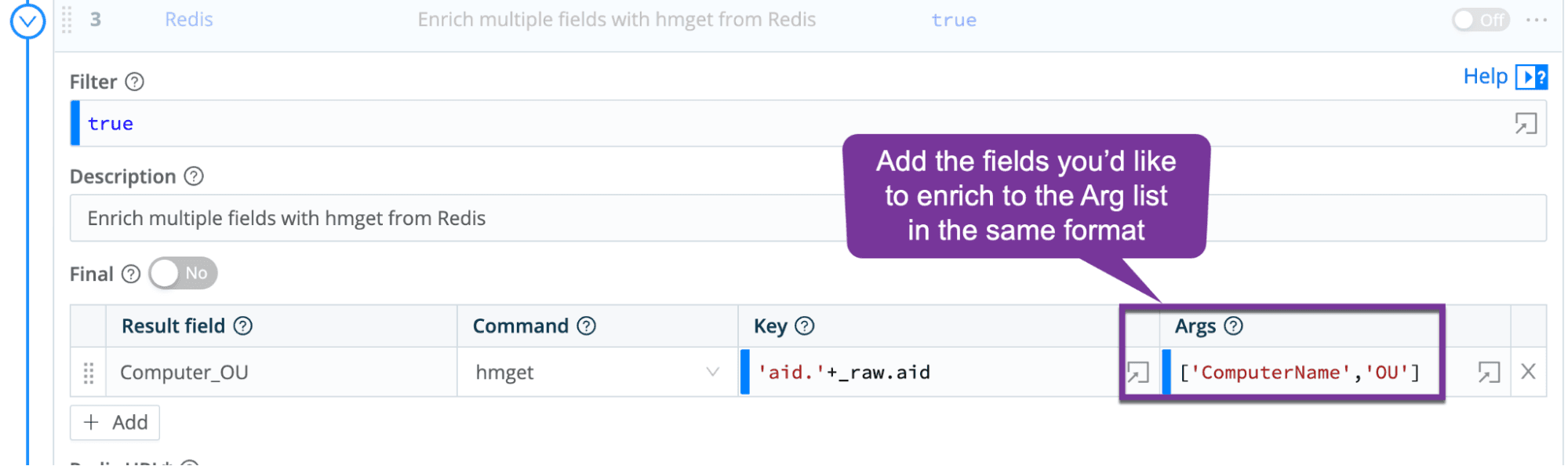
The result is every event being enriched with the desired information.
Stateful Aggregation Through Redis
The pack offers two methods for aggregating the voluminous network connectivity events, either natively with an aggregation function, or statefully across all worker processes through use of Redis. Only one of those groups should be enabled within the CrowdStrike_Network pipeline, not both.
The aggregation works by counting the number of occurrences the client connects to the same server on the same destination port. Logic is used to assume the lower port in a network event is the server port, and the higher port reflects a client side source port. The values of the unique source ports are preserved and passed as a list in the aggregation event.
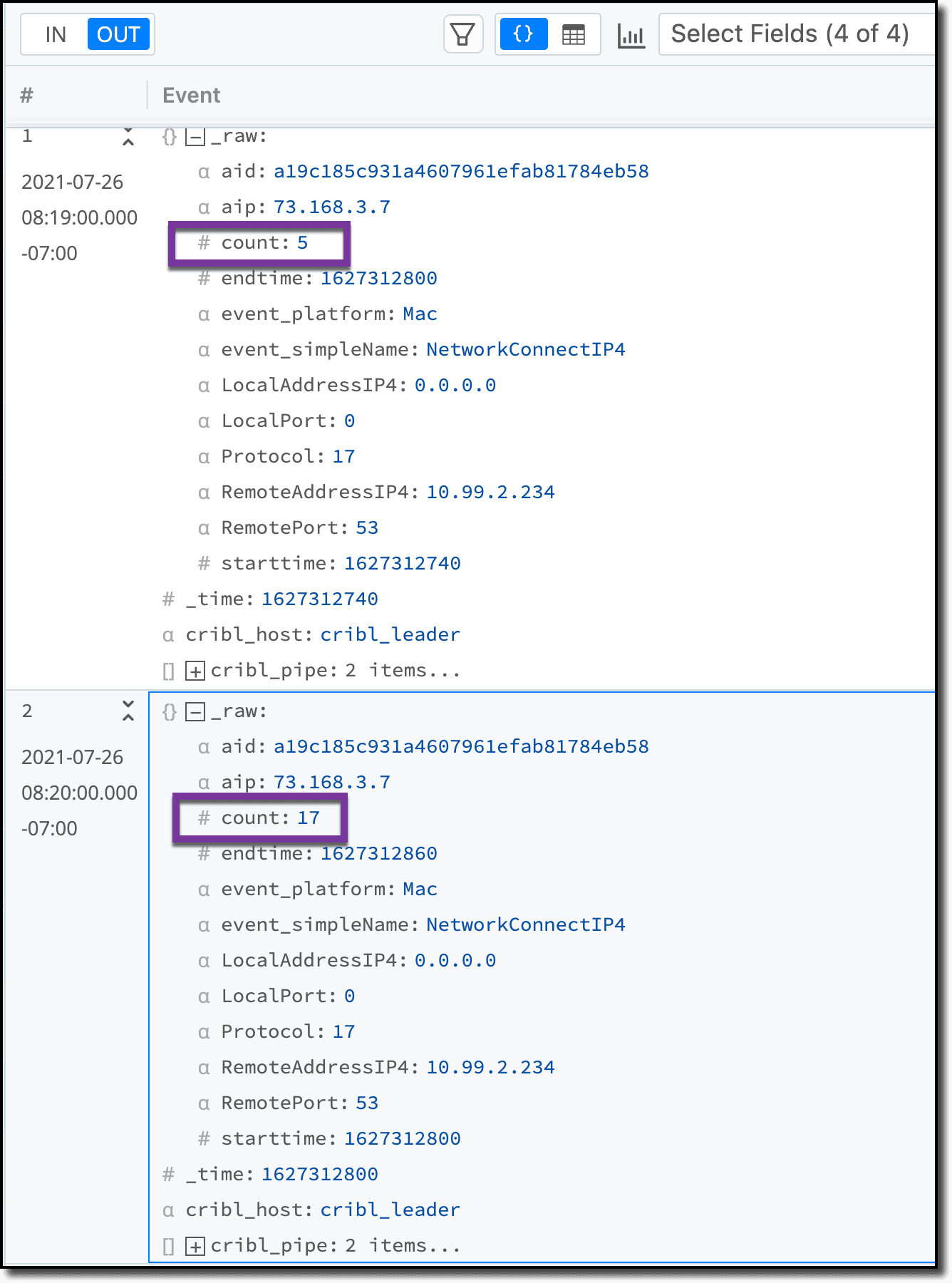
For example, if CrowdStrike reports the following 7 events:Source IP: 192.168.1.1 Source port: 12345 Destination IP: 172.16.9.9 Destination port: 53Source IP: 192.168.1.1 Source port: 12346 Destination IP: 172.16.9.9 Destination port: 53Source IP: 192.168.1.1 Source port: 12347 Destination IP: 172.16.9.9 Destination port: 53Source IP: 192.168.1.1 Source port: 12348 Destination IP: 172.16.9.9 Destination port: 53
Source IP: 192.168.1.1 Source port: 12345 Destination IP: 172.16.9.10 Destination port: 389Source IP: 192.168.1.1 Source port: 12345 Destination IP: 172.16.9.10 Destination port: 389Source IP: 192.168.1.1 Source port: 12345 Destination IP: 172.16.9.10 Destination port: 389
They will get aggregated into the following 2 events:
Event 1: Count: 4 Source IP: 192.168.1.1 Source ports: [12345,12346,12347,12348] Destination IP: 172.16.9.9 Destination port: 53Event 2: Count 3 Source IP: 192.168.1.1 Source ports: 12345 Destination IP: 172.16.9.10 Destination port: 389
The default aggregation period is 60 seconds
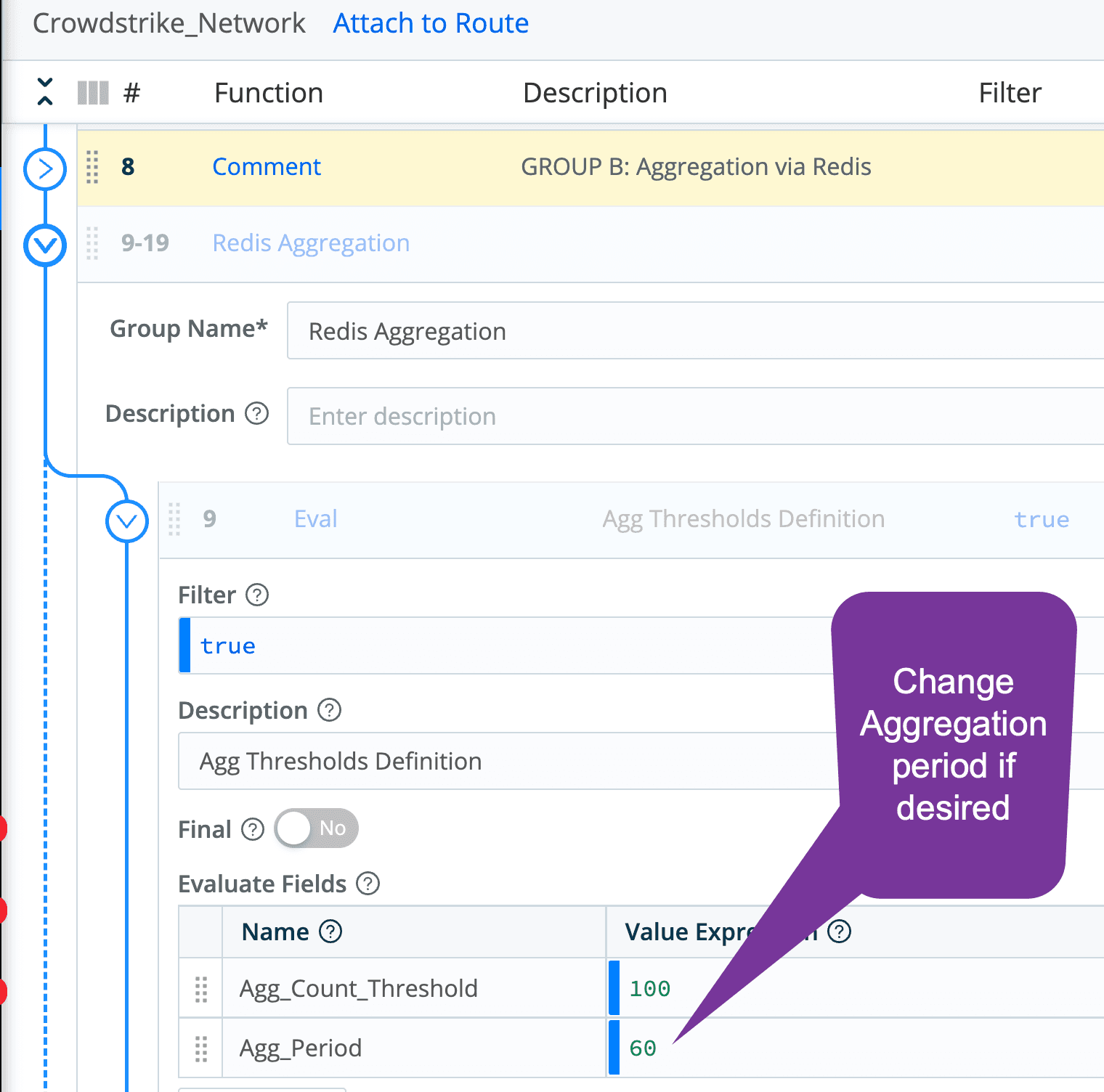
To enable the Redis aggregation, the steps include:
Edit the CrowdStrike_network pipeline
Disable Group A (Native Aggregation)
Edit all Redis functions in Group B to update the Redis URL and user or admin secret
Enable Group B
Save, commit, & deploy
The result will render events similar to these:
Do You Really Need All DNS Events?
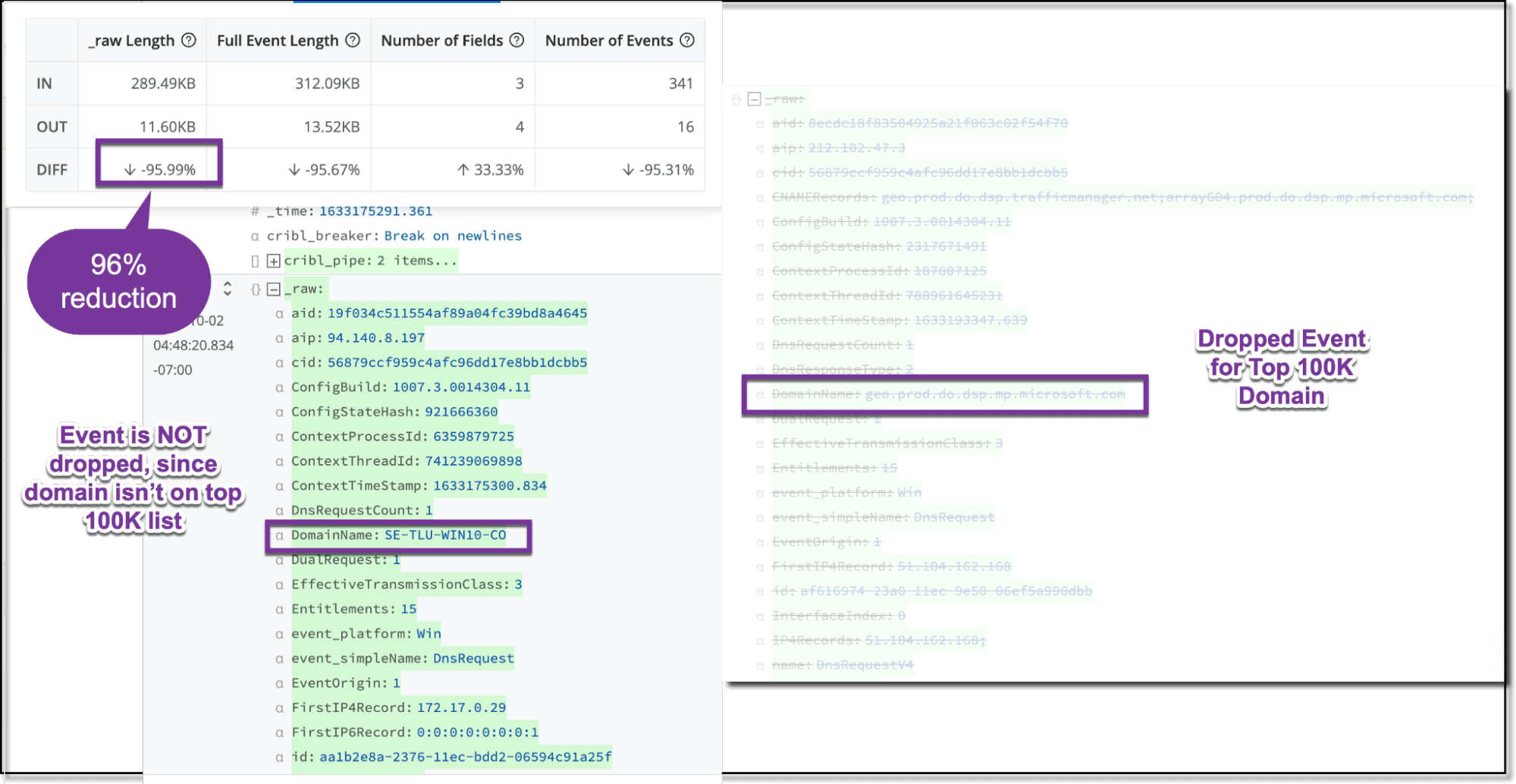
DNS is very voluminous but has huge value for Security Ops teams. However, do you really need to keep DNS records for known addresses? A perfect example are records for someone accessing Google mail, Facebook, and more. You will have other events that show you file transfer activity and process-level information, so lots of it will be redundant, but in a different form. The DNS records you truly need are for malicious addresses, not for the top 10 or top 5,000 addresses.
The pack ships with 5,000 URLs. Through the DNS pipeline, if there is a match within the last 4 portions of the domain, the events will be dropped. (e.g. my.docs.google.com).
The CrowdStrike Pack accounts for the most typical use cases and largest volume event types to help you maximize value from Cribl and CrowdStrike. Customers can always modify the pack and add content to it to suit their needs.
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.



