

I’ve been in the log data analytics space for years, and I have loved seeing the technology and methodologies change and evolve. One of my favorite changes has been the emergence of index-less solutions, and LogScale has a great solution here. If you haven’t heard of LogScale, you should check out their index-less log management solution for yourself (free up to 16 GB/day too). In today’s blog, I want to walk you through how to set up Cribl Stream v.3.5.1 and later to start sending data to LogScale, so you can get up and running fast.
I’ll show you how.
Setting Up LogScale to Receive Data From Cribl Stream
To start, let’s make sure you have a repository for this data setup in LogScale. For a little context, think of Repositories as a collection of data, parsing rules, users, dashboards, searches, and alerts (if you want to learn more about it, I suggest starting here). Specifically, we need to do this step as data inputs are tied to a repository.
Once you’ve created your repository (or if you already have one), you will need to get your ingest token. Do this by clicking on the repo you want to send data to, this will take you to the search page. In my example, I’ve created a repo called “infra-metrics”.
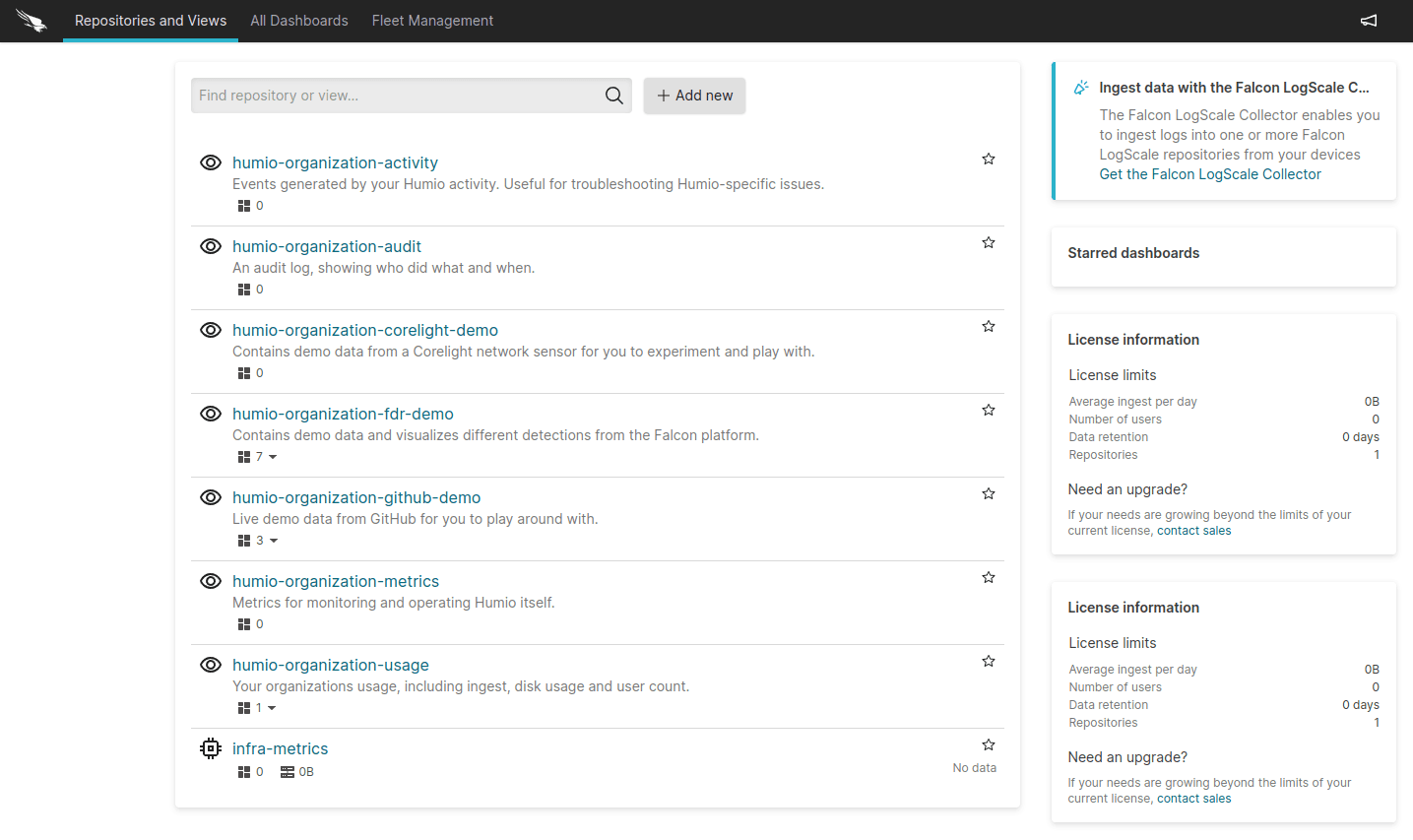
Click on the “infra-metrics” repo and navigate to “Settings” for the repo, located on the top bar.

Once on the settings page go to the “Ingest Tokens” side tab.
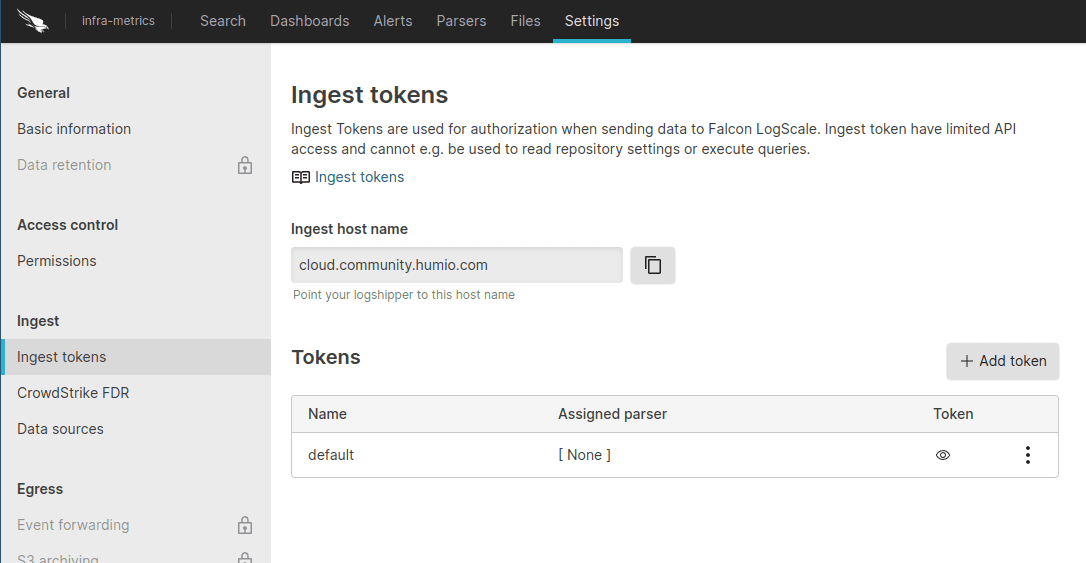
We are going to create a new token called “Cribl-Stream”, without selecting an assigned parser. This is important (we’ll go into why after we set up the destination in Cribl Stream).
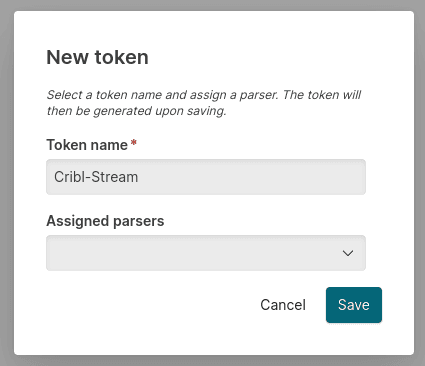
Once saved click on the eye icon (…or eye-con 😉 ), and copy the token.
Great! Now we have LogScale set up to receive data, we just need to start sending!
Setting Up the Stream Destination
So let’s head to the Stream “destinations” page and select a “LogScale HEC” destination.

We are going to add a new “LogScale HEC” input for LogScale. Feel free to name your output however you want, but we do need to change the endpoint. We are going to use the following URL structure:
If you have a custom endpoint: <URL for your LogScale deployment>:443/api/v1/ingest/hec
OR
If using the community edition: https://cloud.community.humio.com:443/api/v1/ingest/hec
Then paste the ingest token we created earlier in as the “HEC Auth Token”.
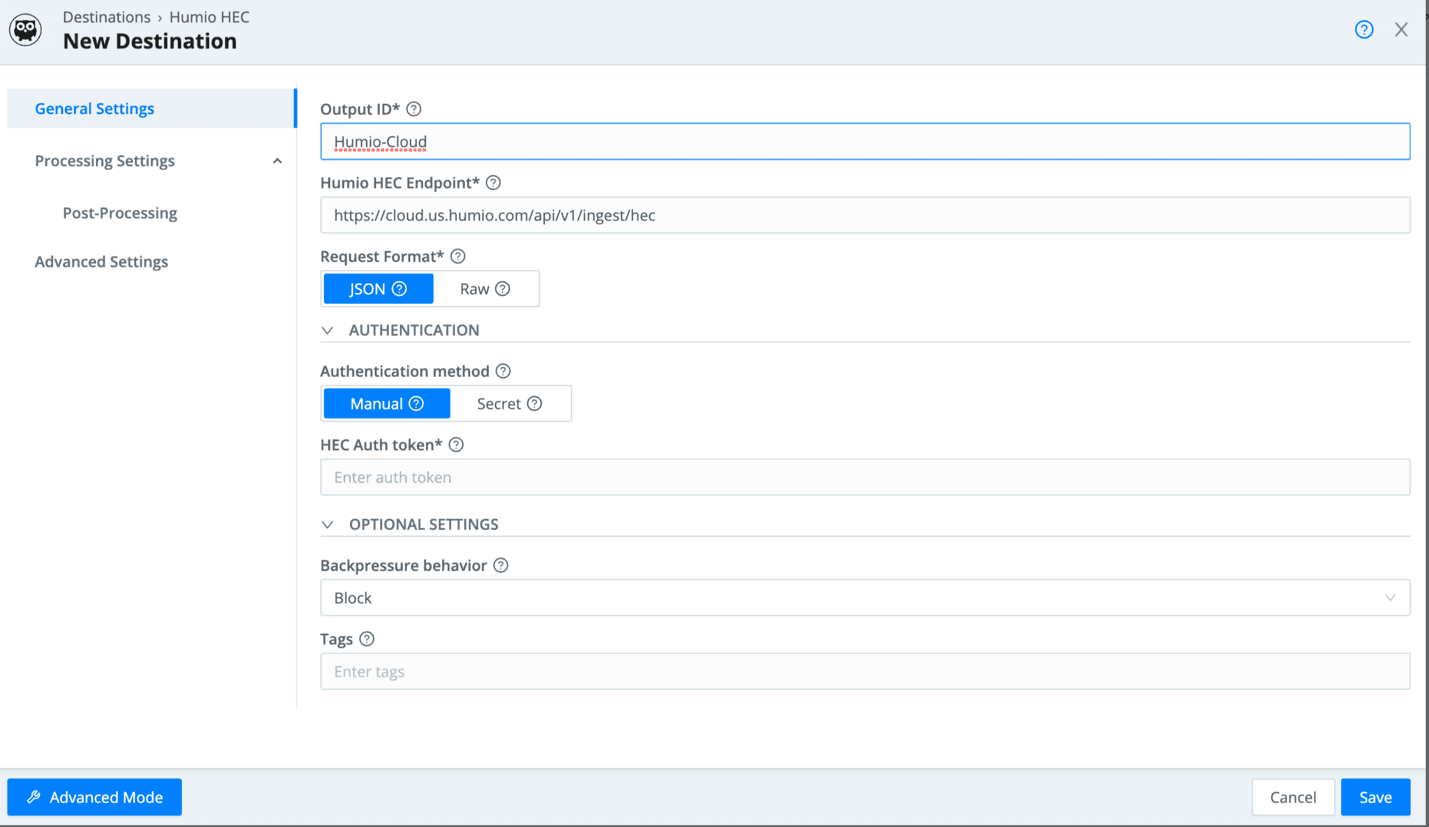
Once you save it, open the configuration page back up and go to the “test” tab so we can send some sample data.
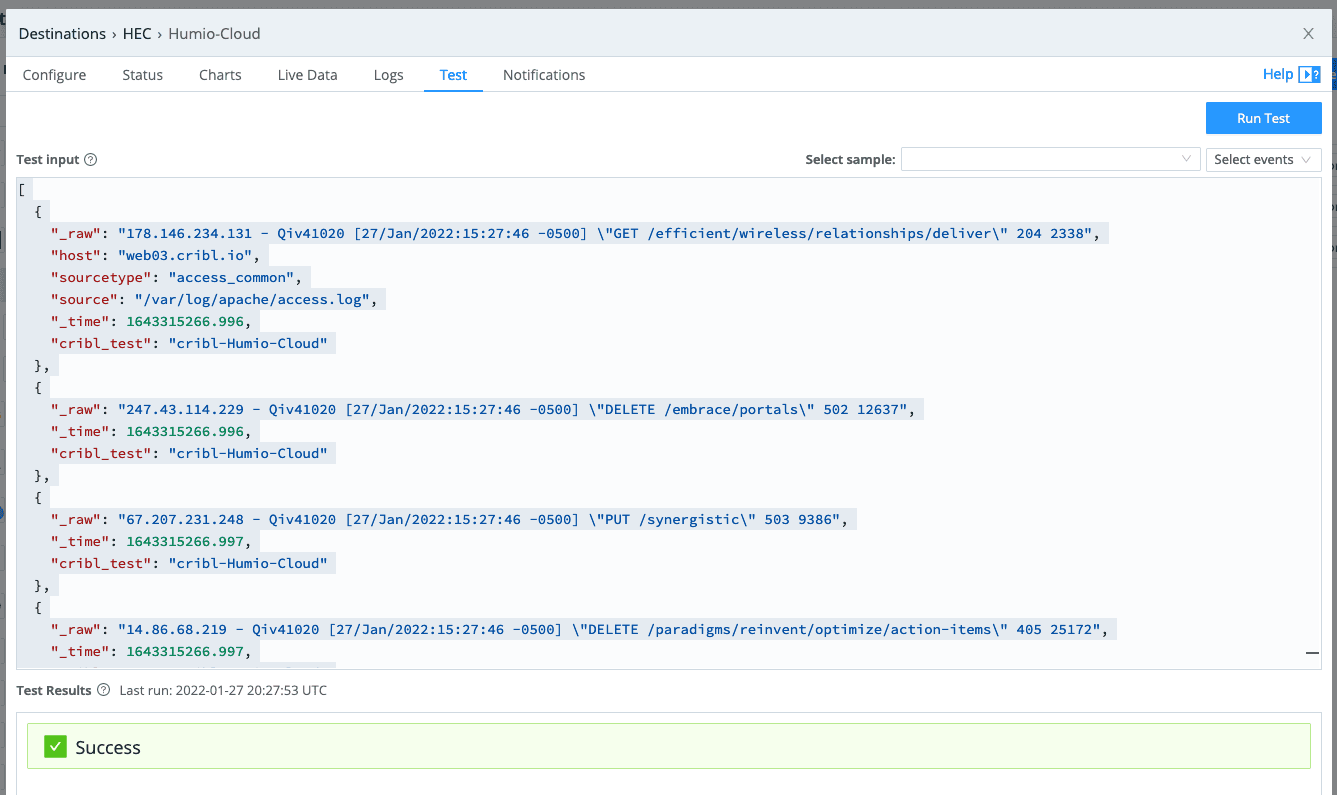
You should see the sample log go through without a hitch, and if you flip over to LogScale, the events should have already shown up.
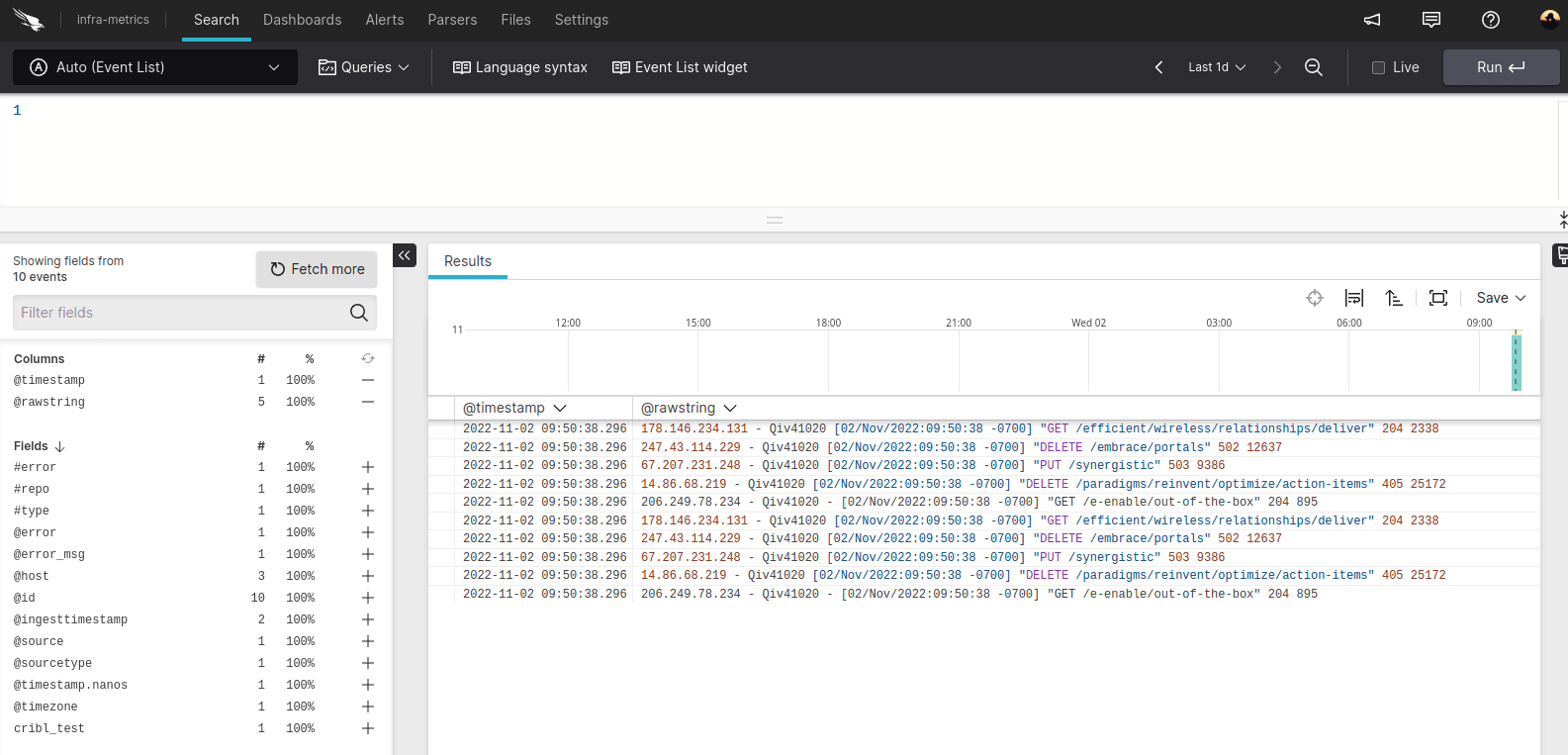
Alright, we now have the destination setup in Stream, we just need to start sending data in! The destination is ready to be used like any other destination in Stream, you just need to attach it to a route.
Parse That Data
LogScale will read the fields designed for Splunk notation to LogScale notation without you needing to do much of anything. But this is where the parsers kick in. If you are having trouble with the format of events in LogScale, that’s where you need to start looking.
Inside your repo on LogScale you will see a tab named “Parsers”, if you open that page you will see all the pre-built parsers.

If you click into any one of these parsers you will see the parsing logic or regex used for that data type.
When you leave the assigned parser empty, LogScale will try to match the sourcetype (what LogScale calls the “@Type”) to a parser. If your data is getting malformed, this is the best place to start looking. An easy way to make sure you have no issues with the parsers is to either create your own parser for the event in question or reformat events into JSON and set the sourcetype to “json”.
That’s all for now! Thanks for joining me on a dive into how Cribl and LogScale integrate, we will be doing more with LogScale over the coming weeks, so stay tuned! And remember, the bird is the word.
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.







