

In this blog series, we’ll explore how Cribl Stream can leverage your existing cross-domain solution (CDS) to easily collect and send your log and metric data between disparate security domains or across air-gapped networks. The goal is to retain as much fidelity of the data as possible, deduplicating processes and simplifying management efforts.
Delivering Data Through a One-Way Transfer
Many customers with critical infrastructure highly desire a specific capability: the ability to transfer data between networks while maintaining a strict separation. In a CDS, where the secure transfer of data is imperative between two distinct security domains or networks featuring varying levels of access control, the adoption of one-way transfer (OWT) stands out as a highly effective approach for safeguarding sensitive information. The following techniques demonstrate how to leverage OWT while ensuring the data’s integrity. To initiate the process, the source network utilizes Cribl to onboard the data from the data producer for output. Subsequently, the data is directed towards an OWT sender, or “pitcher,” to transit between networks. Once the data reaches the OWT receiver or “catcher” on the destination network, another instance of Cribl in that network retrieves the data. At this stage, the data can be modified and/or directed to the desired destinations on the network. The significance of this approach lies in its ability to preserve the fidelity of the data between networks easily.
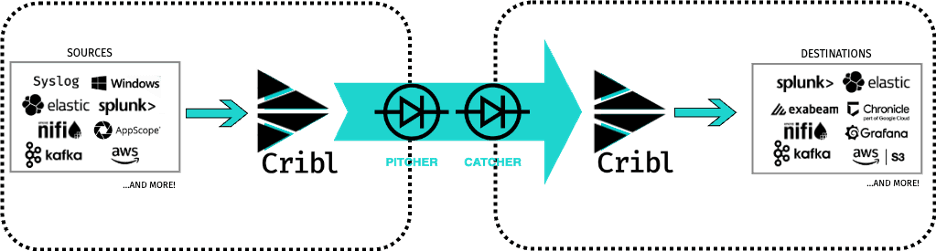
Example Data Flow
Let’s walk through the steps for configuring an example data flow utilizing both Splunk and Elastic.
Source Network:
1. Install Cribl Stream
First, download and install Cribl Stream on the source network.
Note: If deploying onto servers without internet access or on air-gapped on-prem servers, you must ensure that every Cribl node can communicate with its leader.
2. Configure Cribl Source to collect data
Configure the Cribl Source to collect the data from the source network.
List of Cribl Sources: https://docs.cribl.io/stream/sources/
Configure the Cribl Splunk Source to collect the data from Splunk on the source network:
Splunk TCP – Collects data directly from Splunk Forwarders over TCP
Splunk HEC – Collects data from an address, port, and Splunk HEC Endpoint
Splunk Search – Collects data from source systems via Splunk HTTP Event Collector
Configure the Cribl Source to collect the data from Elasticsearch on the source network:
REST Collector – Collects data from Elasticsearch endpoint with an Elastic query
Elasticsearch API – Collects data from Elastic agents over HTTP/S using the Elasticsearch Bulk API
Repository Collector – Collect Elastic data or Snapshot archived in S3, Azure Blob, Google Cloud, or file system storage
3. Configure the Cribl Destination to send to OWT Pitcher
Select the Destination to send to the OWT Pitcher on the source network.
This depends on the device of the OWT device and the protocols that it accepts.
HTTP/S: Webhook Destination
TCP: TCP JSON Destination – Can be configured to send over TCP with TLS encryption
UDP: Syslog Destination
Filesystem: Filesystem Destination
Destination Network:
4. Install Cribl Stream
Download and install Cribl Stream on the destination network.
Note: If deploying onto servers without internet access or on air-gapped on-prem servers, you must ensure that every Cribl node can communicate with its leader.
Note: Docs on Installing in an internet-disconnected environment
5. Configure Cribl Source to collect data from the OWT Catcher
Once Cribl Stream is up, open the Cribl leader URL and configure the Cribl source to collect the data from the OWT pitcher on the destination network. Select the source to send to the OWT pitcher on the source network.
This depends on the device of the OWT device and the protocols that it can send:
HTTP/S: Raw HTTP Source
TCP: TCP JSON Source
UDP: Raw UDP Source
Filesystem: Filesystem Source
6. Configure the Cribl Destination to distribute data
Configure the Cribl source to collect the data from the source network.
List of Cribl Destinations: https://docs.cribl.io/stream/destinations
Configure the Cribl destination to send the data to Splunk instance on destination network:
Splunk Single Instance – Sends to one host and port via TCP
Splunk Load Balanced – Sends to multiple hosts and ports via TCP and can optionally utilize Indexer Discovery and TLS
Splunk HEC – Sends to Splunk HEC Endpoint(s)
Configure the Cribl destination to send the data to Elasticsearch on the destination network:
Elasticsearch – Sends events to an Elasticsearch cluster using the Bulk API
Without Cribl Stream
Transferring data from one security domain to a SIEM such as Splunk or Elastic can be done in several ways. The basics are leveraging custom scripts or open-source tools such as NiFi to:
Collect data from producers on the source network. If it is a SIEM like Splunk or Elasticsearch, it would be extracted from these tools as files
Drop data into an OWT pitcher or physical data transfer to send from the source network to the destination network
Collect from the OWT catcher on the destination network
Send to a SIEM or tool via Splunk Forwarders, Elastic Agents on the destination network
Maintaining data fidelity across different fabrics or analytic systems instances can be a challenging task. This is particularly the case when considering critical values essential for compliance and analysis, such as index, host, source, source type, security markings, program IDs, or asset and identity information. Among these options, leveraging NiFi proves to be the most advantageous. In this scenario, data from the SIEM on the source network is collected and transferred using multiple NiFi connectors or “processors”. On the source network, NiFi plays the role of collecting data from Splunk via the “GetSplunk” processor, or depending on where the data lies within the Indexing Lifecycle Management of Elasticsearch, with a “GetElasticsearch” processor. Both of these processors utilize a search query to extract the desired data based on specific search criteria from either the Splunk search head or Elasticsearch. To ensure a successful transfer to the OWT pitcher, additional NiFi processors must be configured to determine the timestamp, filename, merging strategy, and compression. Upon reaching the destination network, NiFi collects the transferred file and distributes it to the SIEM.
Splunk
For Splunk, it’s usually a Splunk universal forwarder (UF) agent. Proper configuration of the inputs.conf file is required for the UF, which then forwards the data to a Splunk heavy forwarder (HF). The HF is where the NiFi Parser App comes into play, utilizing the appropriate configurations for props.conf, and transforms.conf files. Each step in this process is vital to effectively collect and transmit data from one Splunk instance to another while striving to maintain maximum data fidelity.
Elasticsearch
For Elasticsearch, NiFi can send the uncompressed files to other tools, scripts, or Elastic agents. This is where they would collect the data and then send them to something to aggregate, parse, and transform the data, like Logstash. Alternatively, NiFi can send to Elasticsearch via HTTP with a PutElasticsearchJson processor. NiFi could treat the file as a payload and not extract the fields as NiFi FlowFile attributes or metadata. It might read the content of one file as one record, and if anything is desired to be extracted or added, additional processors would need to be added. The individual records would need to be split, the text extracted, merged, or replaced. It would also require to be in a format that would fit Elasticsearch’s post-bulk API.
With Cribl Stream
All these nebulous configurations are not required when leveraging Cribl. As shown in Figure 3, Cribl Stream has the option to collect data from Splunk with out-of-the-box source connectors: TCP, Splunk HEC, or Splunk Search. It would then be distributed to another Splunk through the TCP or Splunk HEC destinations. For Elasticsearch, it can retrieve data via Elasticsearch API, Rest API, or AWS S3 Cribl sources and send it to Elasticsearch through the Elasticsearch Bulk API destination. That’s it! By leveraging Cribl, it becomes possible to overcome the complexities associated with preserving data fidelity across different Splunk and Elastic instances, ensuring a smooth and accurate data transfer process. No additional agents, processors, or duplicative configurations are required.
Without Cribl Stream, the process is highly dependent on the accuracy of the data and query being performed for pulling the data, such as the timestamp, filenames, indexes, etc. Without visibility into the ingestion, this creates complicated and duplicative processes. What happens to ensure the right data is collected or that data loss is mitigated? With Cribl, observability is provided in your ingestion and transformation process and is delivered securely and efficiently. This is aided by Cribl’s other super cool out-of-the-box capabilities:
Tag: Easily tag, extract, or enrich values in flight to provide the ability to route intelligently and ensure your data reaches the right downstream systems.
Normalize: Cribl can normalize key-value pairs and timestamps to standard compliant formats. This can mitigate transformations or any resource-intensive searches that would have to be done in the systems of analysis.
Obfuscate: Mask and encrypt data in-flight to ensure the right data reaches the right audiences.
Optimize: Cribl optimizes data volume and can encrypt and compress data in flight to the destination, reducing bandwidth consumption and improving data transfer efficiency.
Test: Test and actually see the output from configuration changes without affecting data flows.
Simplify: Monitoring capabilities provide a unified view of data ingestion and routing activities, reducing management effort and deduplicating processes.
Wrap Up
Users might operate in an environment with data and tools in different security domains or within air-gapped networks. The data sources are on one network, while the destinations or analytic tools may be on another. In some cases, the data might be in one SIEM in one network, while there is a separate SIEM in a disparate network that it needs to get to.
This architecture might have a one-way connection from one network to the other. The connectivity is limited to a few unidirectional protocols, such as UDP. TCP is specifically not an option in this case; the three-way handshake is unavailable, and therefore, so are most vendor solutions. Traditional data transfer methods can be complex, error-prone, and lack efficiency. This results in increased management efforts and duplicated tasks. There is a need to transfer data between such environments while trying to retain as much data fidelity, loss prevention, and visibility while staying as close to real-time as possible.
Cribl Stream empowers users to securely route data across different security domains or air-gapped networks, enabling seamless integration and efficient data management. By leveraging Cribl, organizations can streamline operations, enhance security, and maintain compliance while efficiently exchanging data across disparate environments. Are you ready to try it out? Spin up one of our cloud sandboxes for free to try it out right now!






