
Transunion is an American consumer credit reporting agency that operates in over 30 countries. They use Cribl Stream to aggregate and route regional data into a centralized hub, presenting it in a single dashboard that admins can use to interpret the overall health of their system. Watch the full video on YouTube or below to see Transunion’s Steve Koelpin and Don Reilly walk through this use case.
Transunion operates in many countries in the developing world, where unreliable internet access causes issues getting data back to their Global Operations Center.
They have data lakes in each region to capture data locally — but have difficulties moving data and monitoring system health because of limited bandwidth on WAN links, latency over the distance of the internet, and outdated hardware cycles.
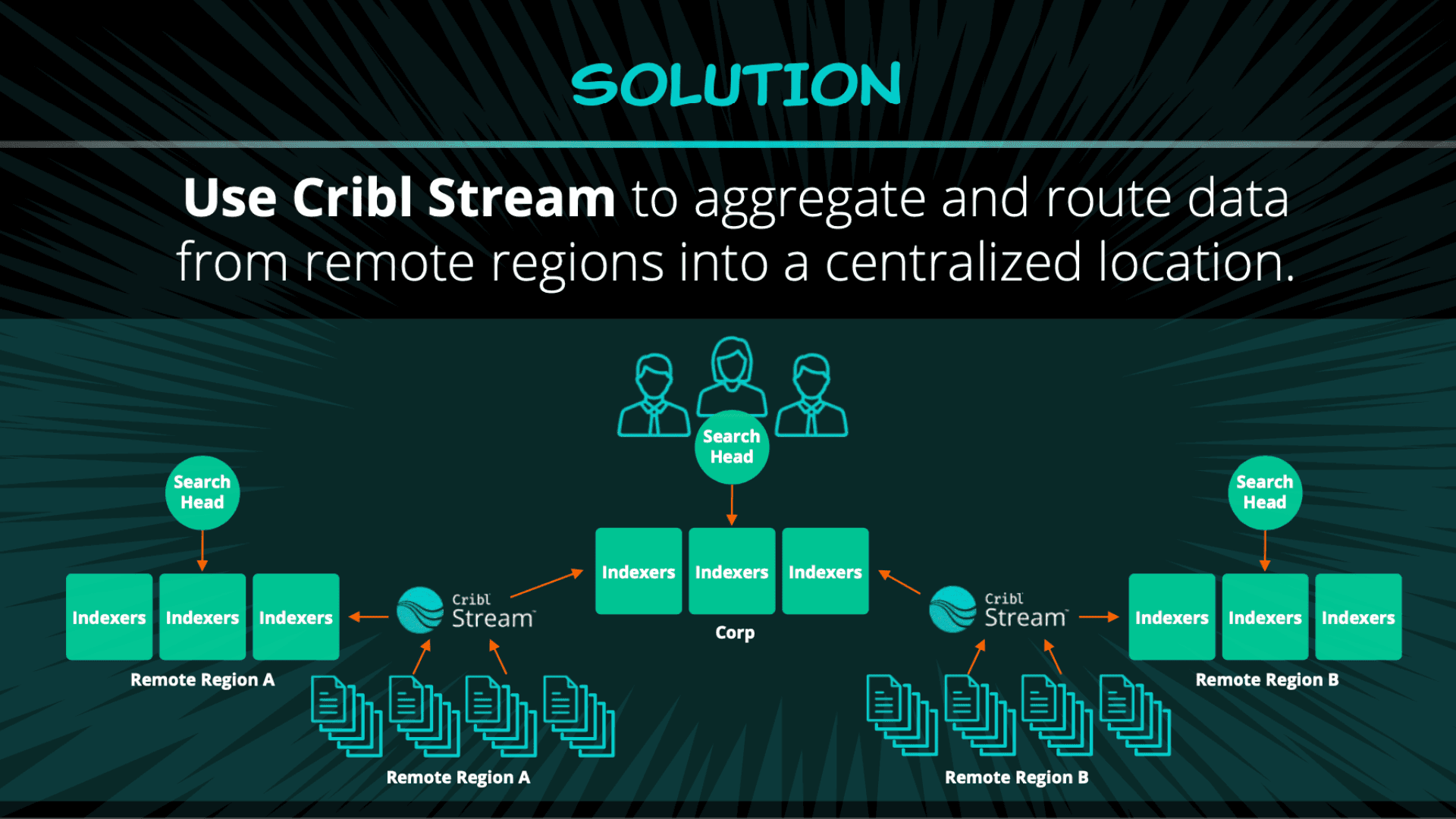
Aggregate & Route Data From Remote Regions Into a Centralized Location
Requiring admins to log in locally to each region wasn’t an efficient way to get an accurate reading on the health of their overall environment, so Transunion turned to Cribl Stream for a solution. They use it to aggregate data from each region into a single dashboard, where they can see a comprehensive, quantitative analysis of all the data flowing through.
Splunk’s universal forwarders push data to Cribl Stream, which acts as a pass through. All the data continues through to the local index, but Stream aggregates, standardizes, and pushes some of that data over the line to Transunion’s corporate environment. During the process, the team at Transunion can eliminate any fields they don’t need and keep the ones they do, significantly reducing transferred data volume even further.
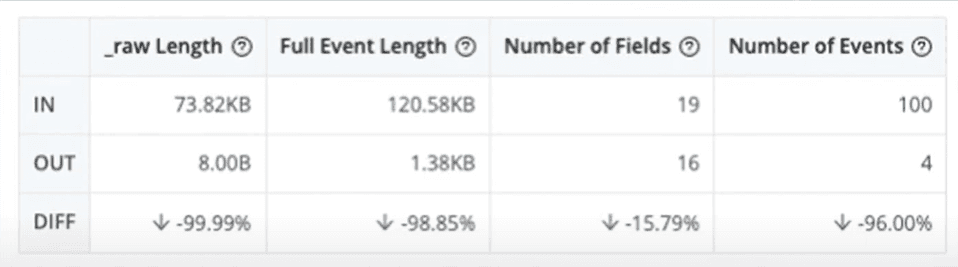
98% Reduction in Data Volume
For the 100 events Transunion sampled — a tiny fraction of what actually gets sent through — they went from 120 KB of data IN down to 1.3 KB of data OUT.
“We knew that because we were throwing out a lot of unnecessary data and distilling out what we really cared about, we were going to have reductions. But we weren’t expecting this type of reduction, down almost 98-99%” – Don Reilly – Senior Manager, Enterprise Logging and Analytics
How Data Aggregation Works in Cribl Stream
Aggregation in Cribl Stream is similar to Splunk and other logging tools. For Transunion’s specific use case, the first thing they do is group events by status and a 60-second time window. Then, they select attributes around the metrics they care about — like max, average, and median response times.
Cribl Stream collects the data in transit, instead of doing a federated, distributed search against the data at rest. Collecting data in transit, aggregating what’s needed, and pushing only what’s relevant to an indexing tier provides quite a few benefits — but there are also cons. We’ll walk through those now so you can decide which strategy is right for you.
Pros and Cons of Pulling Data
Pulling data via federated search is relatively easy to implement. You don’t necessarily have to understand the data format up front — just run a query, let it hit those search peers, and return the data that’s needed. This works well for ad hoc searches or if you don’t necessarily know what you want to look for.
One of the cons of this approach includes increased network load. It’s not a concern for small queries, but the network can get easily oversaturated as you scale up. Pulling data also makes it impossible to isolate the data you care about. It can make for unpredictable search runtimes due to variations in standards, network speeds, and traffic. You won’t get a complete result until everything is done ascending, which will depend on how long it takes for your slowest servers to respond.
Pros and Cons of Pushing Data
Pushing data is much better suited for recurrent searches like security alerts, dashboard queries, or anything you do on a daily or minute-to-minute basis. You’ll have uniform data structures because you’re only putting necessary data into these indexes that you need, and 100% search relevancy from pushing data to a more central location.
Since the data is being fed from that central distilled index, you can easily predict search times. Because of the reduced data over the WAN, and interconnect links in particular, you’ll also have a significantly reduced data load.
This approach does have its drawbacks — it requires planning and a full understanding of the data you’re using, how to implement it, and where you aggregate and compare data. Changes to your dataset won’t be retroactive, so if you decide to add a field to what you’re searching, you’ll only get it from that point forward.
Taking data out of the local clusters and sending it to the central location does come with some costs for the extra storage and ingestion — but those costs are covered multiple times over by an enormous decrease in storage and license spend in each region.
A Single Dashboard View for Admins
The result is a single pane of glass view for their operators to look at health per region. Each region has different volumes, response times, etc. — so Transunion built it in a way that baselines all that information, puts it through anomaly detection, and picks out outliers, which adjusts the score up and down.
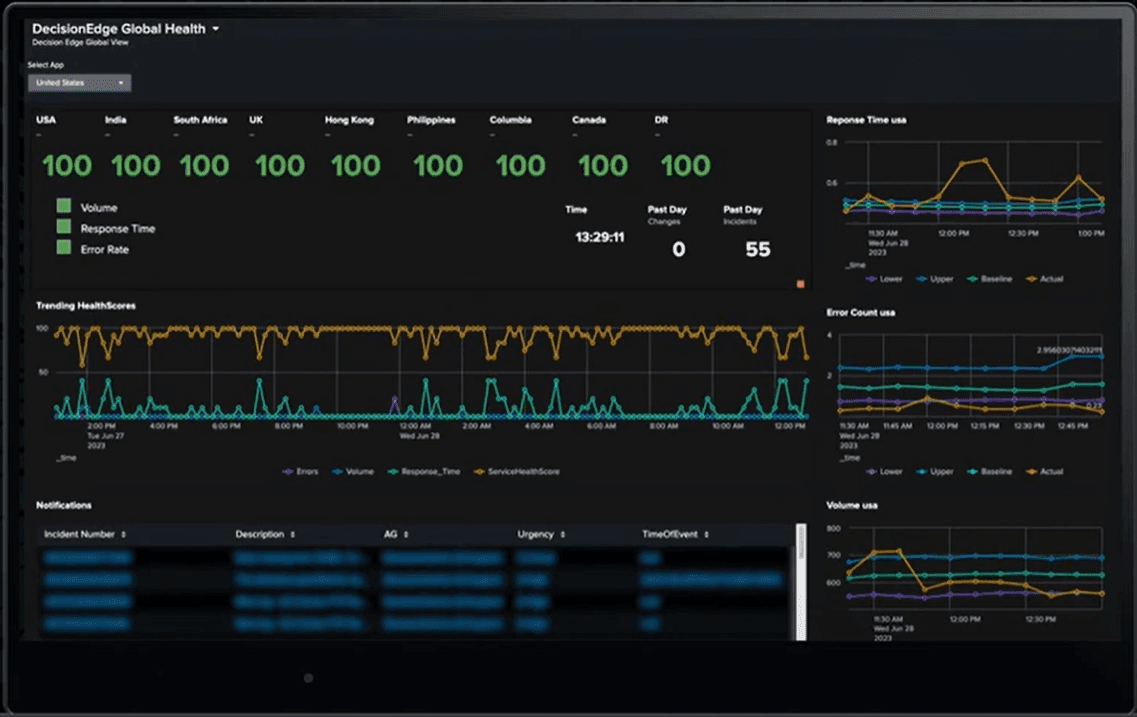
When they want to understand the health state of one of their remote regions, they no longer have to try and interpret it by logging into that region locally, looking at various dashboards, and trying to figure out how it looks relative to yesterday.
Be sure to watch the full video to learn more about how Transunion accounts for worker node independence in their architecture and to get more details about how they leverage Cribl Stream to make the life of their admins easier.
Join the conversation and learn more about Cribl!
Cribl Curious: A Q&A site for getting all of your sources to the right destinations
Cribl User Group: A Virtual meetup to connect with fellow Criblers from around the globe. Check out previously recorded sessions too!
Cribl Community: The jumping off page for all things Cribl education and community.
Cribl University: Find the right learning path and certification for you to start using and getting value from Cribl’s portfolio of products.






