


If you’re a Splunk user relying on Dynamic Data Self Storage (DDSS) or Active Archive (DDAA), you’re likely familiar with this frustrating loop:
You archive petabytes of data to S3 via DDSS to save on hot and archive storage costs.
You need that data later — for an investigation, compliance request, or audit.
You wait. You’re forced through a time-consuming rehydration process via DDAA and DDAS or with a different Splunk Enterprise instance.
You pay. Not just in time, but in added storage and compute costs.
The Real Cost of SIEM Archiving
Splunk’s archiving process wasn’t built for flexible, long-term access:
Slow data access: Restoring large datasets from DDAA often takes 24+ hours and has a strict 10% DDAS entitlement cap.
High storage and rehydration costs: Replaying data into Splunk active storage consumes expensive capacity.
Limited accessibility: Archived data is locked into vendor-specific formats and can’t be easily used elsewhere.
What’s New: Splunk DDSS → Cribl Lake
We’re changing the game.
Cribl Lake now supports direct ingestion of Splunk DDSS data. That means your self-storage archive data can be written directly to a Cribl Lake dataset — unlocking a whole new world of accessibility, flexibility, and cost control. This allows for:
Unlimited searches: With Cribl Search, you can instantly query your Lake DDSS dataset — no access delays, no rehydration.
Simplified storage management: Cribl Lake becomes a seamless destination for Splunk self-storage, with no need to manage S3 yourself. Cribl handles it all for you.
Simplified Replay back to Splunk: If specific datasets need to be reprocessed by Splunk or another SIEM tool, forwarding that data to the appropriate destination is a simple process. And the best part? There’s no restriction on the time range or amount of data you can Replay.
Built for global teams, managed from one place. With Cribl Lake’s Splunk Cloud Self Storage support, global organizations with distributed Splunk deployments can now centralize their archive strategy, no matter where their data lives.
Teams can configure and manage DDSS ingestion across multiple regions from a single, unified interface. This ensures consistent policies, simplified operations, and seamless access to archived data across all environments — whether you’re archiving logs from North America, EMEA, or APAC.
One archive strategy. One search platform. Globally managed.
Why It Matters
Instant Search with Cribl Search
No more 24-hour SLAs. No rehydration. Just fast, powerful search across archived Splunk data stored in Cribl Lake.
Slash Storage and Search Costs
By keeping data in Cribl Lake instead of hot storage:
You avoid the high per-GB cost of SIEMs
You’re charged only for compressed data
You control compute costs with Cribl Search on your terms
Effortless Replay to Splunk or Anywhere
Need to bring data back into Splunk for analysis? No problem. Cribl makes it easy to Replay data from Cribl Lake into any destination, including your SIEM, observability tools, or data lakes.
How It Works
Setting it up is simple:
Add Splunk Cloud as a Source in Cribl Lake
Configure your self-storage location in Splunk
Run an S3 policy test in Splunk Cloud
Splunk archives journals directly to Cribl Lake
Start querying with Cribl Search — instantly
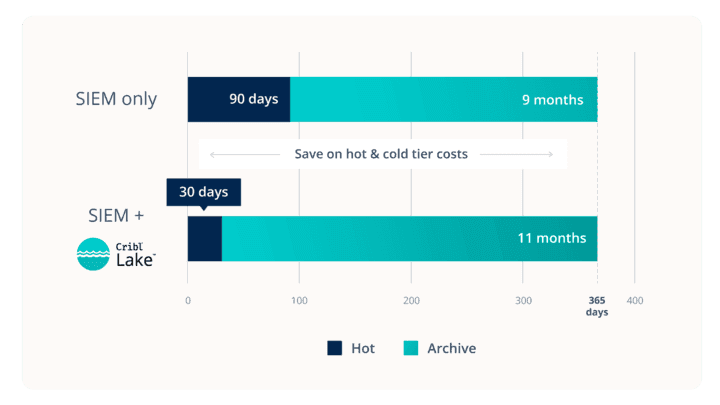
Compared to Traditional DDSS...
Get Started With Splunk DDSS Ingest to Cribl Lake
Stop letting your data sit idle. Create a Cribl Lake destination in Splunk DDSS today — and unlock fast, flexible access to the data you already own.
What’s on the horizon for Cribl Lake? Look forward to ingesting JSON formatted data via HTTP directly into Cribl Lake, as well as bring your own storage - coming real soon!






