

Cribl Stream continues to raise the bar for data enrichment with support for disk-based lookups in Stream 4.12. This feature is designed to help IT and Security teams enrich massive datasets efficiently, without the memory constraints of traditional in-memory lookups. Scaling enrichment at ingest time is critical for real-time analytics and operational agility.
Here’s how support for disk-based Lookups unlocks new possibilities for your data pipelines.
Why Disk-Based Lookups?
Scaling Is Hard
In-memory lookups require memory to scale linearly with the number of Worker Processes and the size of lookup data. While that works fine for small data sets and/or a limited number of cores for processing data, it does not map to the “enrich-on-ingest” strategy needed by IT and Security teams in a dynamically scaling environment. Limiting what data can be injected into an event at the time it is processed shifts the burden to query time, slowing down query performance and introducing the risk of inaccurate enrichment data.
In smaller environments, operating a single Worker Process with a 10MB lookup source is easily supported entirely in memory. Scale that single Worker to 14, 30, or 62 Worker Processes and storing all 500MB in memory becomes impractical.
Performance at Scale Is Hard, Too
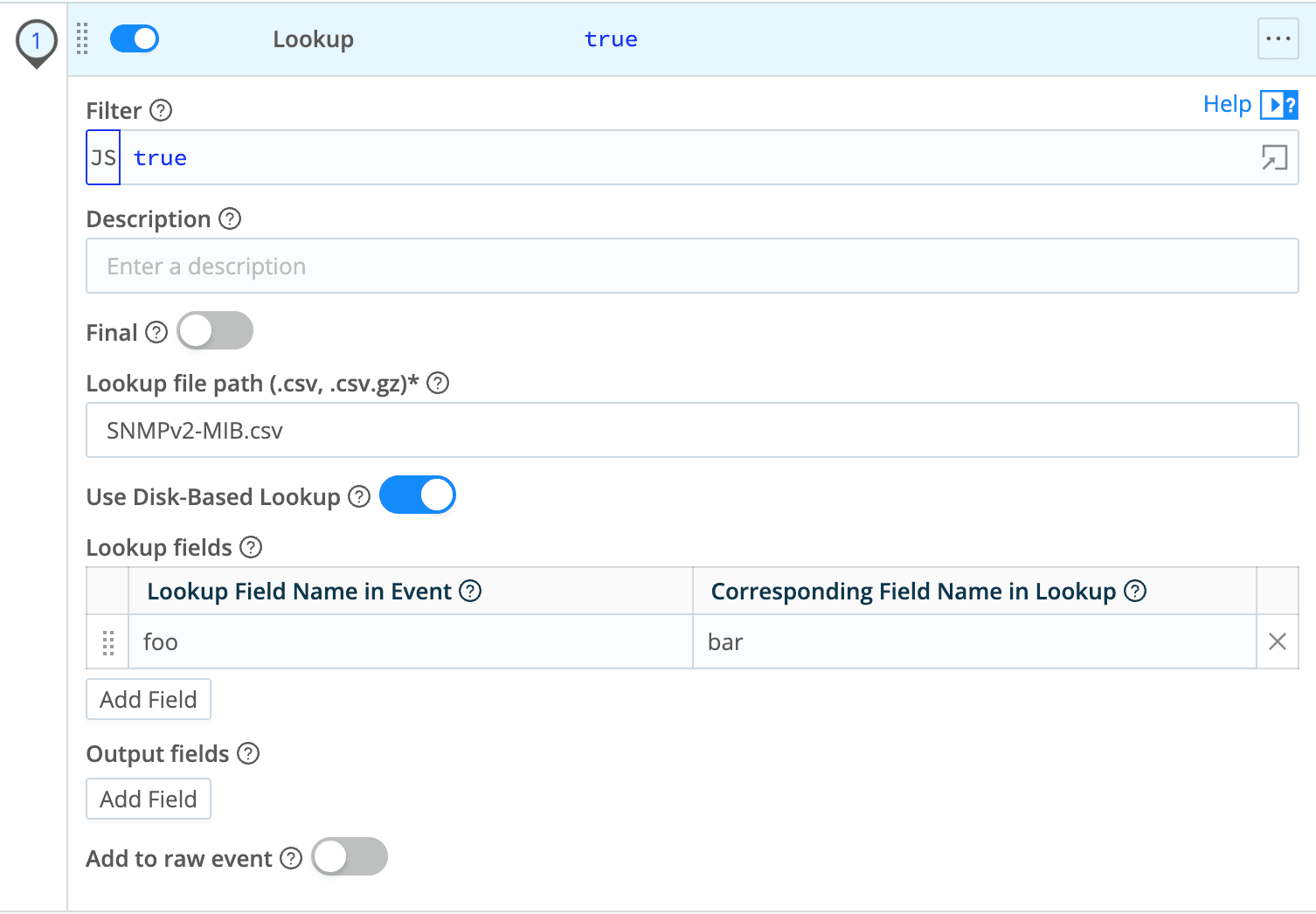
Cribl has long had the option to use files stored locally on a Worker, but the solution lacked the ability to optimize the data for thousands of events per second. With disk-based lookups, Cribl now supports up to 4 separate indices per lookup without any limit on the number of columns in each index. (Though we typically see 3-5 columns per index.)
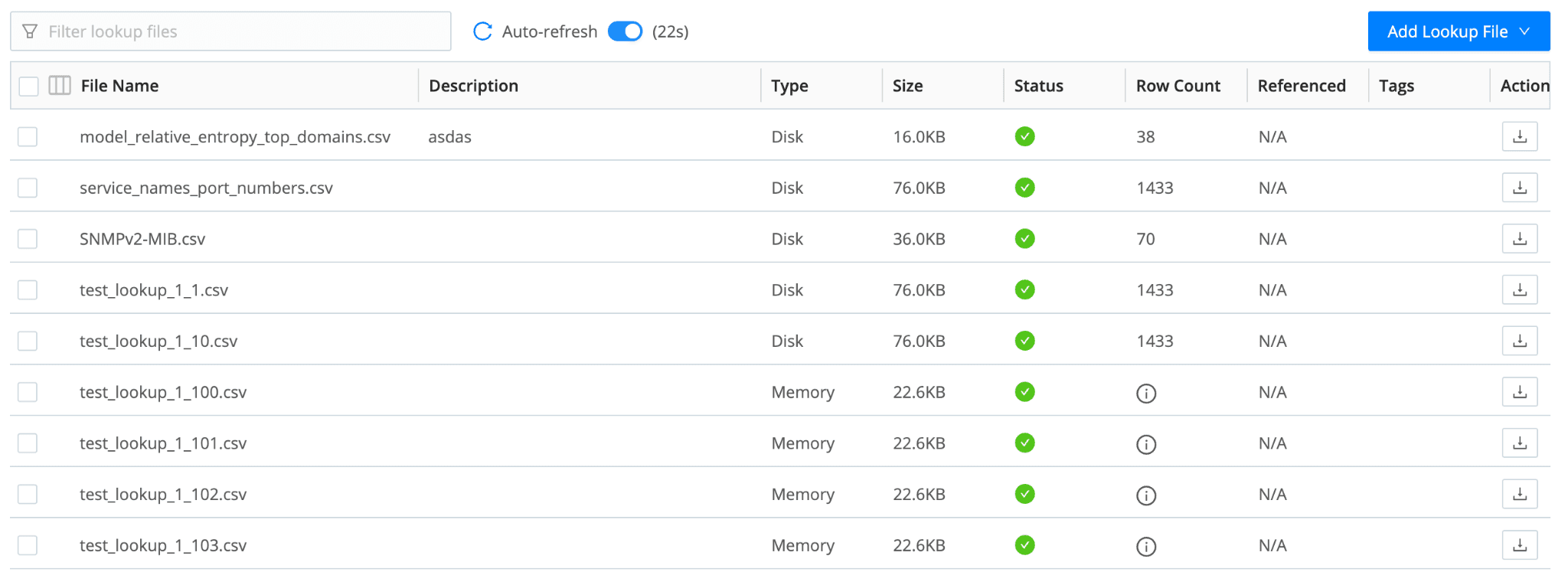
Cribl now supports Lookups that can be stored in memory or on disk.
Multiple indices on the same dataset allows performance optimization for different use cases without the need to manage multiple lookup instances. Does the Security team need to perform a lookup on column A, C, and J? No problem — create an index of those columns. Does the IT team need to lookup using columns C, J, K, and L? Another index!
Indexing is the magic that allows scaling the size of a lookup without sacrificing all of the performance of in-memory and without the in-memory penalties working with truly massive datasets. With disk-based lookups, you get the best of both worlds: the flexibility to support huge lookup tables that would overwhelm memory in a traditional setup, and the speed to keep up with demanding, real-time enrichment workloads.
Performance at Scale, Without the Memory Tax
In-memory enrichment has a memory tax in a shared-nothing architecture. Disk-based lookups in Cribl Stream solve this by introducing a hybrid model: lookups are read from disk, while frequently accessed data is cached in memory. This approach enables you to handle huge datasets — hundreds of megabytes or more — without having to allocate massive amounts of RAM to every Worker Process. This means you can scale enrichment to match your data growth, without even breaking a sweat.
The Lookup Function in Cribl Stream, complete with the disk-based lookup toggle. This new feature reduces the memory footprint on Workers.
Key capabilities include:
Multiple indices per lookup
- Create up to four indices on a single lookup, each optimized for different access patterns. This means security teams can index on columns A, C, and J, while IT can index on C, J, K, and L — all on the same dataset, without duplicating data.
No hard limits on columns
- There’s no restriction on the number of columns per index, so you can adapt your lookups to your business needs.
Optimized for high throughput
- Disk-based lookups are engineered to support thousands of events per second, ensuring enrichment keeps pace with your data flow.
Worker Smarter, Not Harder
Managing large lookups is now easier than ever. Disk-based lookups are created using the same UI or APIs as in-memory, preserving your existing workflows. Why mess with a good thing!?! Larger lookups add some interesting wrinkles to the process, so we have decoupled disk-based lookups from the mandatory commit/deploy cycle. This means you can push updates to individual lookups — or all disk-based lookups — without any configuration changes, and Worker Processes will not require a restart.
Be sure to check out our Docs for large lookup best practices, including configuration and memory sizing.
Ready To Get Started?
Ready to scale your enrichment workflows? Disk-based lookups are available now in Cribl Stream. Start by configuring your first disk-based lookup via the UI or API, define your indices, and push updates as needed, without disrupting your data pipelines.
This allows you to:
Refresh CMDB data every 30 minutes
Reload NAT tables or threat intelligence feeds multiple times a day
Update lookup data as often as needed, without interrupting data processing
With disk-based lookups, you can enrich more data, more often, with less operational friction. Scale confidently, enrich intelligently, and keep your teams focused on insights, not infrastructure.






