


When we introduced cribl-privacy-1.0, our custom model for Cribl Guard’s background detection capability, we made the case that telemetry needs a different kind of privacy model: one built for the semi-structured, high-throughput shape of real machine data rather than polished natural-language text. Today we're releasing cribl-privacy-1.5, the next version of the in-house transformer powering Cribl Guard. It catches significantly more sensitive data and all in the same memory footprint as before.
This post walks through what changed, why we prioritized recall, how we held the footprint steady, and how to start taking advantage of Cribl-Privacy 1.5 today.
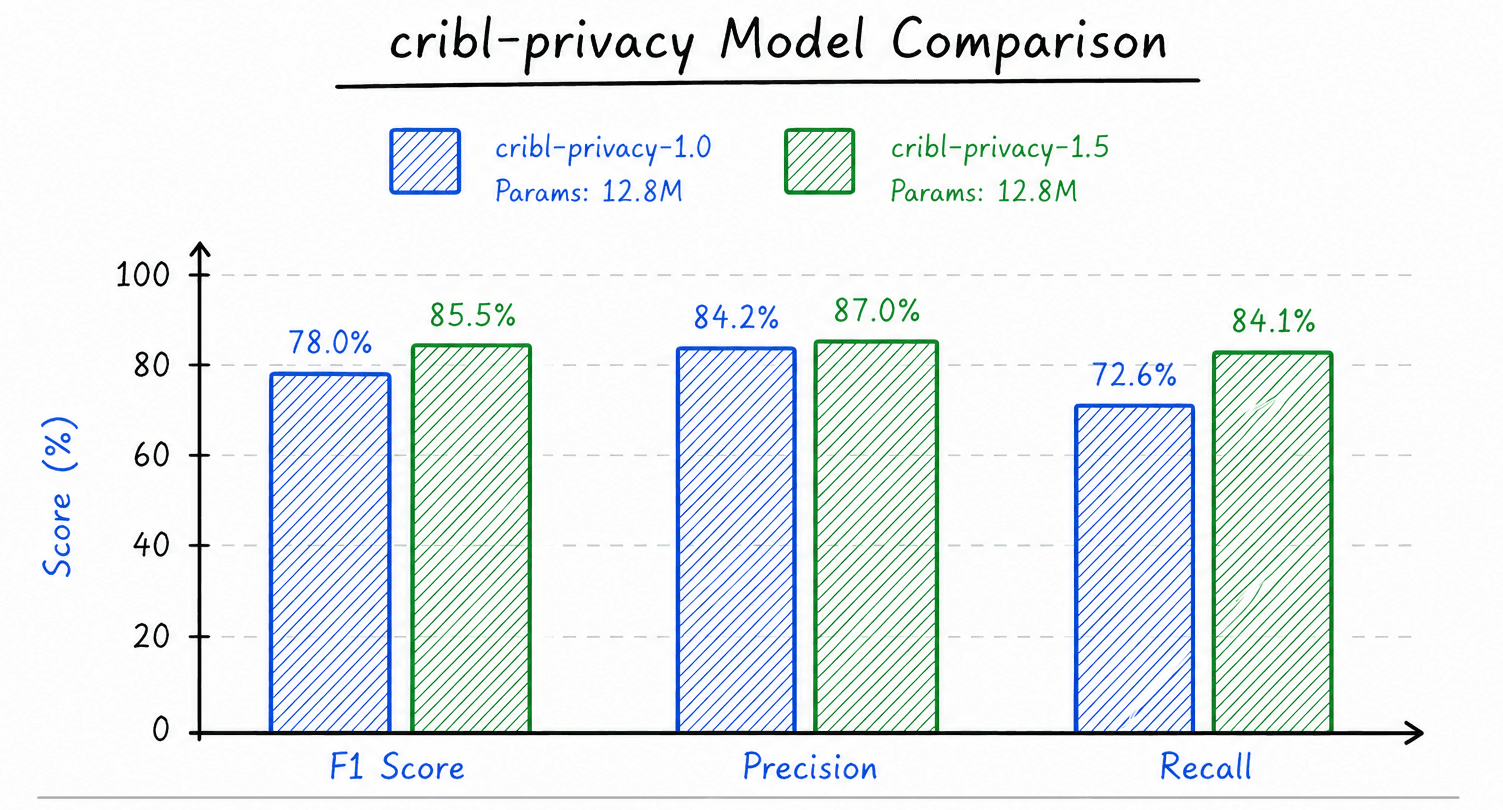
Figure 1: Cribl-Privacy 1.5 vs. Cribl-Privacy 1.0 model comparison across F1 score, precision, and recall.
What changed
We measured v1.5 against our internal benchmark grounded in the real world: a diverse mix of production logs, vendor formats, and machine-generated records. Our upgraded privacy model posts meaningful gains across the board in ways that reflect how customers move data in production:
F1 score: 78.0% → 85.5% (+7.5pp)
Recall: 72.6% → 84.1% (+11.5pp)
Precision: 84.2% → 87.0% (+2.8pp)
False positives: down 7.6%
False negatives: down 41.9%
Prioritizing recall
One obvious weakness of the v1.0 model was its recall, which measures the percentage of positive cases that are false negatives. For our customers, missing a sensitive value such as a token in a serialized payload, an account number in a delimited field, or PII hiding in a vendor-specific format, is more costly than flagging a field that turns out to be benign. False negatives leak data downstream; false positives are recoverable inside a redaction pipeline. And the recall gain didn't come at a noise cost: false positives dropped 7.6%. cribl-privacy-1.5 catches more sensitive data and produces less noise in the operational fields analysts rely on for investigations.
Same footprint, same throughput profile
Our goal wasn't to grow the model, it was to make the existing footprint smarter. cribl-privacy-1.5 is sized to run in-stream, under the throughput requirements of production telemetry pipelines, with the same CPU-conscious inference characteristics as v1.0. For our customers, that means a seamless drop-in upgrade: better accuracy, with no change to compute budget, throughput, or memory footprint.
Available now
cribl-privacy-1.5 ships with Cribl 4.17.1 and is rolling out to Cribl Guard customers now. If you're already running Guard on 4.17.1 or later, the upgrade is automatic. If you're not, this is a good moment to take a look as the gap between general-purpose privacy filters and a model trained specifically on telemetry just got wider.
Conclusion and next steps
cribl-privacy-1.5 delivers higher recall, stronger overall accuracy, and fewer false positives and false negatives, all while preserving the same lean footprint and in-stream performance profile customers rely on today. It’s purpose-built for the messy, high-volume reality of telemetry, not the polished world of natural-language text.
If you’re a Cribl Guard customer, confirm you’re on 4.17.1 or later so you’re already benefiting from cribl-privacy-1.5, then compare your detection and false-positive patterns before and after the upgrade in your own data. If you’re still evaluating Cribl Guard, now is an ideal time to give it a try and see how a telemetry-native privacy model changes what you can safely route downstream.





