In May, we announced Direct Access for Splunk DDSS —a way for Splunk Cloud customers to archive data directly into Cribl Lake, bypassing Cribl Stream. Cribl users immediately saw the value: lower storage costs, more robust lifecycle management, and faster access to archived Splunk data through Cribl Search and Replay.
Today, we’re excited to expand on that foundation with Cribl Lake Direct Access (HTTP), giving teams even more ways to send data straight into Cribl Lake.
The Need for More Options
Up until recently, Cribl users had to route data through Cribl Stream before landing it in Cribl Lake. For many, Stream is essential—it transforms, enriches, and routes data at massive scale. But for others, especially those who can’t migrate away from their third-party agents, or who only need to store raw data, Stream can feel like an unnecessary extra step.
When all you want is a fast, low-cost way to stream events into Lake — but without Stream — Direct Access gives more options.
Introducing Direct Access — Easy, Flexible Data Ingestion
Direct Access (HTTP) is a new feature in Cribl Lake that provides a direct ingestion path for JSON-formatted data via HTTP, with specific options to support Splunk HEC and Elasticsearch senders. Whether you’re using FluentBit, Vector, or the OpenTelemetry Collector, you can now point your existing agents directly at Lake and start storing data—no Stream required.
With Direct Access, you can:
Reduce complexity & latency – Eliminate the extra hop through Stream when you don’t need it. Skip the transformations, but still Replay your data when the need arises.
Lower costs – Ingest data efficiently without unnecessary compute overhead.
Optimize for bulk loads – Perfect for one-time migrations or large historical ingests.
Stay flexible – Choose the best ingestion path: Stream/Edge for advanced processing, or Direct Access for simplicity.
Faster time-to-insight – Store data in your data lake — in open formats — and make it easily accessible and queryable to all your users. Spin up a Lakehouse to perform super speedy searches.
How It Works
Getting started takes just a few steps:
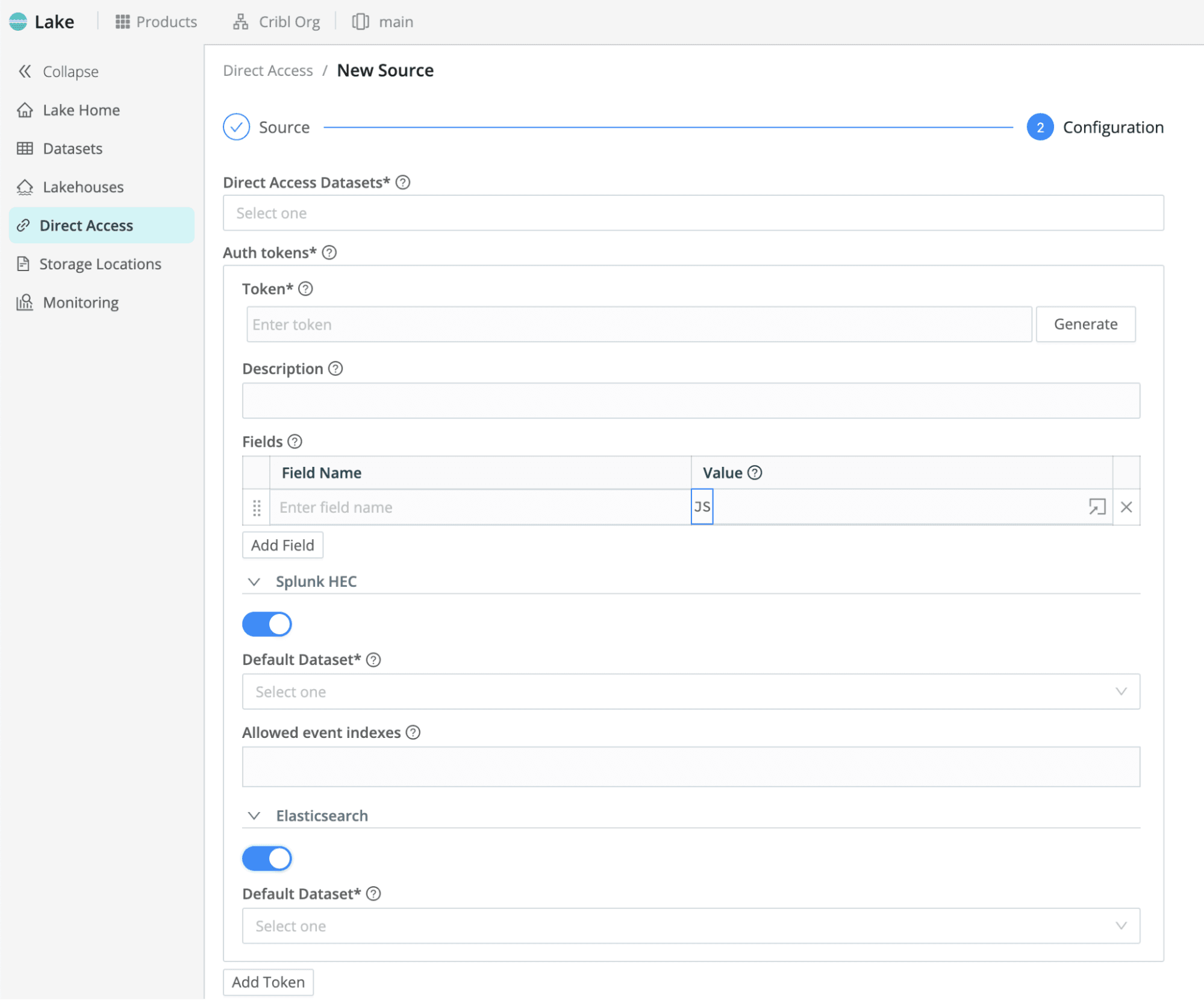
Add a new Direct Access HTTP Source in Cribl Lake.
Configure authentication with tokens. You can add specific options for Splunk HEC and Elasticsearch Bulk API senders.
Point your third-party tools (Vector, FluentBit, OpenTelemetry, etc.) to the Lake ingestion endpoint.
Analyze data instantly in Cribl Search, or replay it to your SIEM or analytics platform with Cribl Stream.
Direct Access data lands immediately in Cribl Lake—ready to govern, query, and replay. No rehydration, no delay.
Pricing
Data ingested through Direct Access is billed at 0.10 credits per GB, with storage billed separately at standard Lake rates. $1 = 1 credit. Click here for more information about Cribl pricing.
When To Use Direct Access vs. Stream
Use Direct Access when:
You want a simple, low-cost way to land JSON data in Cribl Lake.
You’re running bulk migrations from other tools and don’t need to transform or shape your data.
You already use agents like FluentBit or Vector and don’t need Stream’s processing features.
Use Cribl Stream to route to Cribl Lake when:
You need to filter, enrich, or transform data before storing.
You want advanced routing logic across multiple destinations.
You prefer turnkey to route, transform, and reduce data with a central tier that provides choice, flexibility, and control.
The Bottom Line
With DDSS, we gave Splunk Cloud customers a more efficient path into Cribl Lake. With the addition of this Direct Access (HTTP) feature, we’re taking it a step further—enabling any JSON-speaking agent to write directly into Lake.
This means fewer hops, lower costs, and faster time-to-insight—while still giving you the flexibility to choose Stream’s powerful processing when you want it.
Get started today—point your agents at Cribl Lake and unlock the fastest path to data storage, analytics, and replay.