

Adding new data to your log events via an external data store is nothing new. Splunk, at least, has been doing it since the mid-2000s. So the utility is immediately apparent to anyone who’s made use of lookups. Stream takes this to the next level, though. Using some keys in the original log event, we reference an external source to decorate the log with new information associated with that key, ready to be added to filters, reports and become pretty eye candy for the corner office.
Fast & Fresh vs. Old & Slow
Most often being run at search time, lookups suffer two shortcomings: They slow down searches, and the extra data could be out of date by the time you run it.
Picture log events that have internal IP addresses in them. The report you’re putting together needs to show who was accessing the top-secret Bazooka File Blaster 5000™ based on this IP. If you hit the DHCP server API (or its logs) for IP to username mapping at search time, the mappings could be outdated. If you’re searching a month later, there’s a good chance you’ll get back invalid info re: the IP. And will slow down your search as each result will need to be interrogated on every run.
Enter Cribl Stream: an observability pipeline that sits between your log producers and your log destination. The destination could be archival storage or your log analysis platform of choice, or both. Think of it as just another hop on the network, but this hop gives you magic powers. As your IP-laden logs pass through Stream, you can filter, transform, reduce, route, and enhance those logs with lookups. When they land in your log analysis tool, the extra decoration will be ready to use, and most importantly, will accurately reflect the state of things when they were produced. The extra data can be added to your events’ raw text, or as metadata (aka, index time fields) ready for performant searching and accelerated data models. And if you use the logs 2 years from now to research an incident, you’ll have accurate info ready to roll.
As with search time lookups, the key in your lookup data could be more abstract. If you’re looking up IP addresses, maybe your lookup table has CIDR blocks as the keys. You’re not looking for an exact value, but if your IP falls in a particular subnet range. For example, 10.0.0.8 would land in the goat_herd network in the below lookup:

Going further, you could list regex patterns as the key. Imagine matching part of a URI in access logs to find which part of the app is in use. The lookup doesn’t know the entire string, but you can use regex to qualify:

Whether you’re matching on exact strings, numbers, regex, or IPs, this isn’t news. What is different is that the new data is looked up exactly once and added as the event is traveling to your log storage or analysis tiers. That timing allows it to be more accurate and will make your searches feel jet-powered.
What if the Value Returned Was a Regex?
What would happen if the value returned by the lookup was itself a regex? How could we make use of this? What if the returned value was the required regex for field extractions?
With Stream, we’re in luck. Javascript expressions are 1st class citizens in Stream pipelines. We can quite easily apply the returned value from the lookup as a regex, unlocking a new way to manage long lists of field extractions’ patterns.
Consider the following log event from Cisco’s ASA gear:
%ASA-6-305011: Built dynamic TCP translation from outside:10.123.3.42/4952 to outside:192.0.2.130/12834
We can easily extract the ASA numeric code from each log because they all start with %ASA-#-. The rest of the message is tougher because the logs are not consistently presented. Each ASA code could potentially have different positional data. What we need is a way to apply regex to extract the required data based on which ASA code is present. A lookup table of ASA code -> regex patterns:
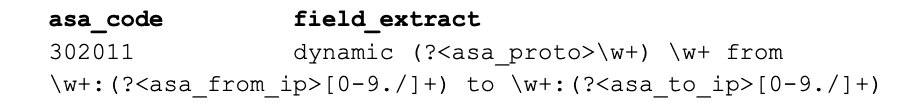
How to Implement in Stream
Extract the ASA code from the log (Eval function):

Using that extraction, find the code (302015) in the lookup file (see above), retrieving the regex as field name
__regex(using Lookup function)
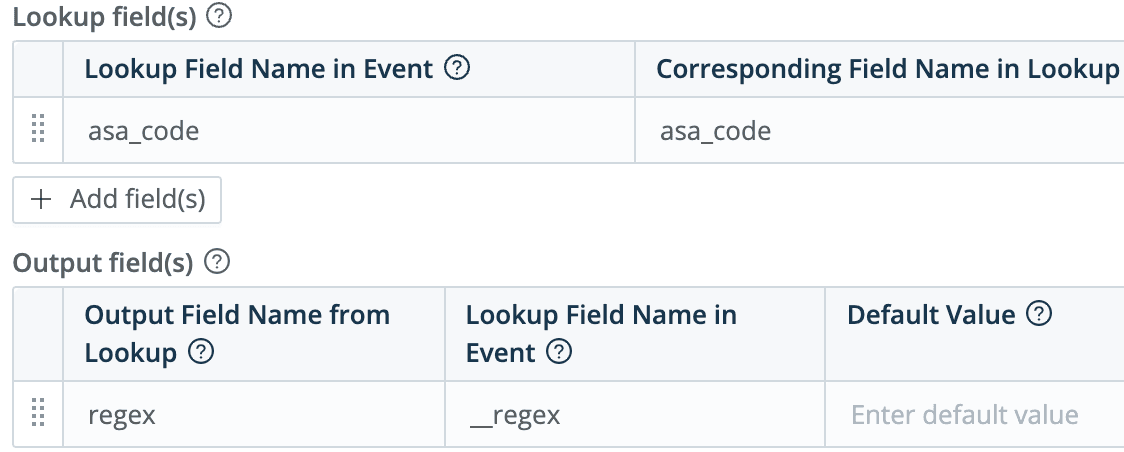
Apply the the returned regex extraction to the event (using Eval function)
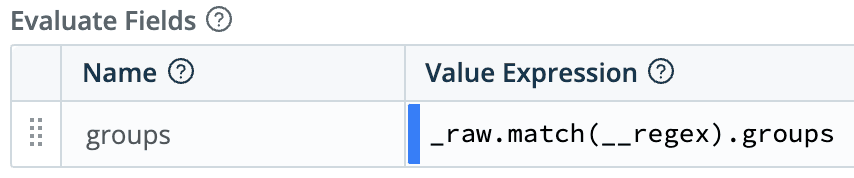
After which, we flatten the newly created groups object (Flatten function), and then rename all the nested objects inside it (Rename function)

With this newly extracted data, we can leave them as index time fields in the event envelope or rewrite the raw data to include field identifiers. Remember, this is happening before the event reaches the destination. And with a relatively easy configuration to maintain, instead of messy transforms.conf or props.conf files.
Summary
Working on your data in-flight means you get more accurate data and faster searches. And that’s great! But it’s not just about doing the same old things in a more performant way. Sometimes building blocks can be assembled in surprising new ways. Stream’s framework allows more freedom in how you handle your data. Get out of your vendor lock-in, free your data, and do amazing things with it.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.





