
What is Schema-on-Read?
Schema-on-read is an approach in data management that emerged as a powerful alternative to the traditional schema-on-write method, providing flexibility for IT and Security professionals. This concept supports accepting data in its unprocessed form, without the need for a predefined schema, allowing data to be stored and processed without extensive upfront data modeling.
How does Schema-on-Read work?
Unlike schema-on-write systems where the schema is determined before data ingestion, schema-on-read systems apply the schema as the data is read or queried. This late binding of schema allows for dynamic adjustments and caters to constantly changing data structures.
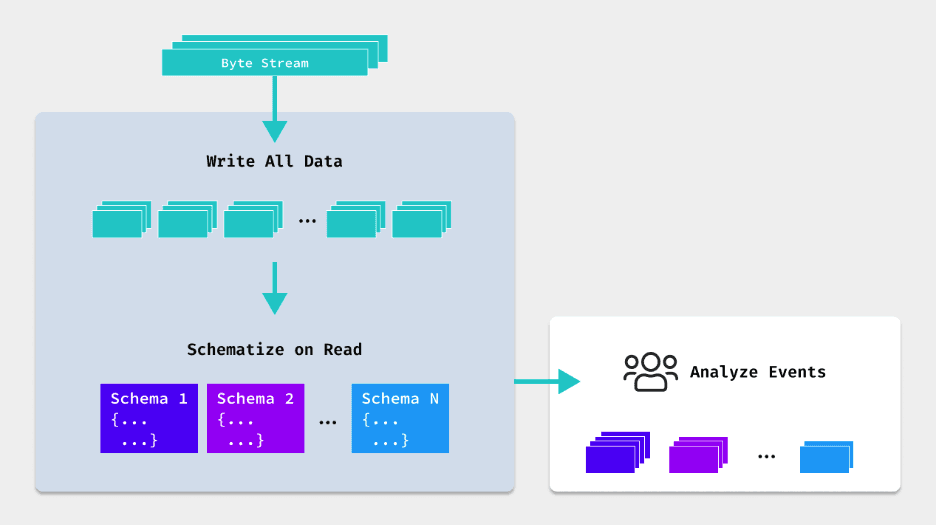
Why is Schema-on-Read important?
Schema-on-read offers a few crucial benefits to businesses.
Flexibility. Schema-on-read systems are pivotal in handling diverse and evolving data sources, and are suitable for use cases like log analysis, and data lakes.
Agility. This system empowers organizations to directly work with raw data, assisting with analysis. This eliminates the need for lengthy ETL processes or upfront schema definition.
Cost-efficiency. With this system, analysts can promptly interact with and explore the data without having to wait for predefined schemas or undergo extensive data transformation. This reduces infrastructure and operational costs.
Schema-on-Read use cases
Organizations can use schema-on-read for various use cases:
Data Integration
Schema-on-read helps with data integration from multiple sources with differing schemas or formats. This eliminates the need for extensive data transformation beforehand, allowing for quicker integration.
Real-Time Data Streaming
In real-time data streams, the data structure can evolve rapidly. Schema-on-read is well-suited for processing and analyzing this data without being hindered by predefined schemas.
Big Data Analysis
Big data often involves analyzing large volumes of unstructured or semi-structured data. Schema-on-read allows you to analyze this data directly without prior schema definition.
Data Exploration
Schema-on-read allows data scientists and analysts to discover insights from different datasets without initial schema design. This flexibility allows for quicker discovery of hidden patterns and trends.
Schema-on-read systems
Schema-on-read systems offer a flexible approach to data storage,This is particularly useful for certain applications: document stores and indexing engines like ElasticSearch and Apache Solr. These systems excel at handling data with diverse structures
Additionally, log management and analytics tools like Sumologic, Splunk Enterprise, ELK Stack, and OpenSearch leverage schema-on-read to analyze unstructured log data efficiently.




