
In the world of IT and security data, traditional approaches like schema-on-write and schema-on-read have long been used to structure and extract insights from data. However, these approaches have their limitations, with schema-on-write requiring substantial upfront effort and schema-on-read sometimes lacking performance optimization.
As data volumes continue to explode and how we manage and work with data continues to evolve, a new approach emerges. Schema-on-need is a new concept that balances these two paradigms and offers a significantly more flexible, efficient, and cost-effective solution for IT and security teams to work with their data.
What is Schema-on-Need?
Schema-on-need means the structure (or schema) of data only needs to be defined when it’s actually needed. This means the schema doesn’t need to be defined prior to being stored in a storage solution. This is particularly useful for handling unstructured or semi-structured data, which doesn’t have a fixed format.
How does Schema-on-Need work?
As data is ingested into a storage solution, it is kept in its original format which significantly simplifies data onboarding. This involves using file formats and data structures that are freely available for anyone (with the right permissions) to use, implement, and modify. These open formats are designed to ensure broad compatibility, interoperability, and accessibility across different software and systems.
By storing data as is, teams can flexibly transform and/or enrich their data to a particular schema when they need to. No proprietary format to restrict the use of data, and no vendor lock-in.
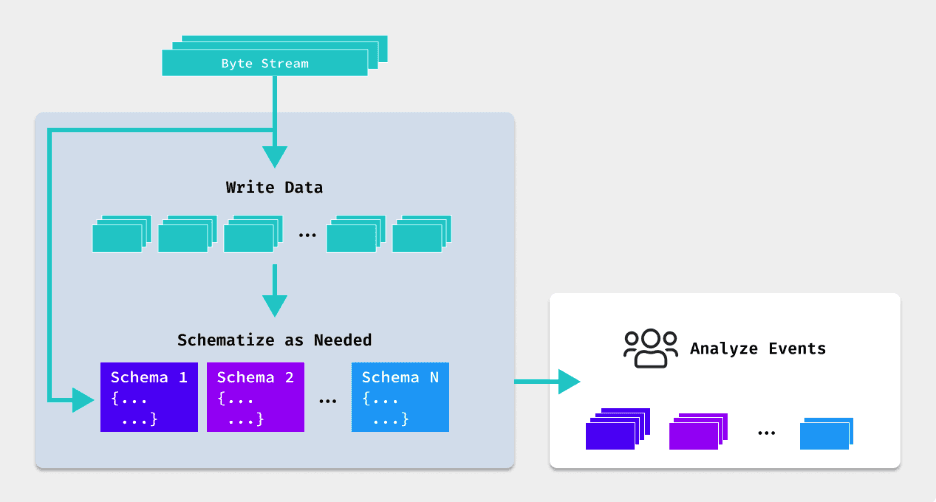
The Power of Schema-on-Need
Schema-on-need is a purpose-built approach that gives you the flexibility of schema-on-read with the performance benefits of schema-on-write – but only when you need it. With schema-on-need, you can:
Handle structured, semi-structured and unstructured IT and security data of all shapes and sizes
Create schemas only for frequently accessed data to optimize query performance
Avoid the overhead of creating schemas for all data upfront
Adapt easily to new data sources and use cases without extensive data modeling
Query in-place at the edge or API endpoints
Reduce storage and compute costs
Why is Schema-on-Need important?
Cribl Search’s schema-on-need represents a new paradigm in IT and Security data insights that balances the trade-offs of schema-on-write and schema-on-read. It offers flexibility, cost-efficiency, and performance optimization, making it well-suited for modern data challenges. With schema-on-need, organizations can unlock the full potential of their data while minimizing storage and compute overhead.
Conclusion
As IT and security data grows in volume and complexity, a new approach is needed to extract timely insights and maximize data value. Schema-on-need provides the flexibility to handle any data type, the efficiency to apply schemas only when needed, and the performance to power your analytics – all in one unified solution. By adopting schema-on-need with Cribl Search, your organization can adapt rapidly to change, reduce data management overhead, and enable a wide range of real-time use cases – from threat hunting, to monitoring, to troubleshooting. The future of IT and security data lifecycle management is schema-on-need.






