

A couple of years ago, I wrote another blog on how Oracle Cloud Infrastructure (OCI) Object Storage can be used as a data lake since it has an Amazon S3-compliant API. Since then, I’ve also fielded several requests to capture logs from OCI Services and send them through Cribl Stream for optimization and routing to multiple destinations. There are two primary methods to achieve this:
Write the logs to an OCI object storage bucket and leverage a Cribl S3 collector. The bucket should have file paths that include year, month, day, hour, and optionally minute to enable time-based filtering.
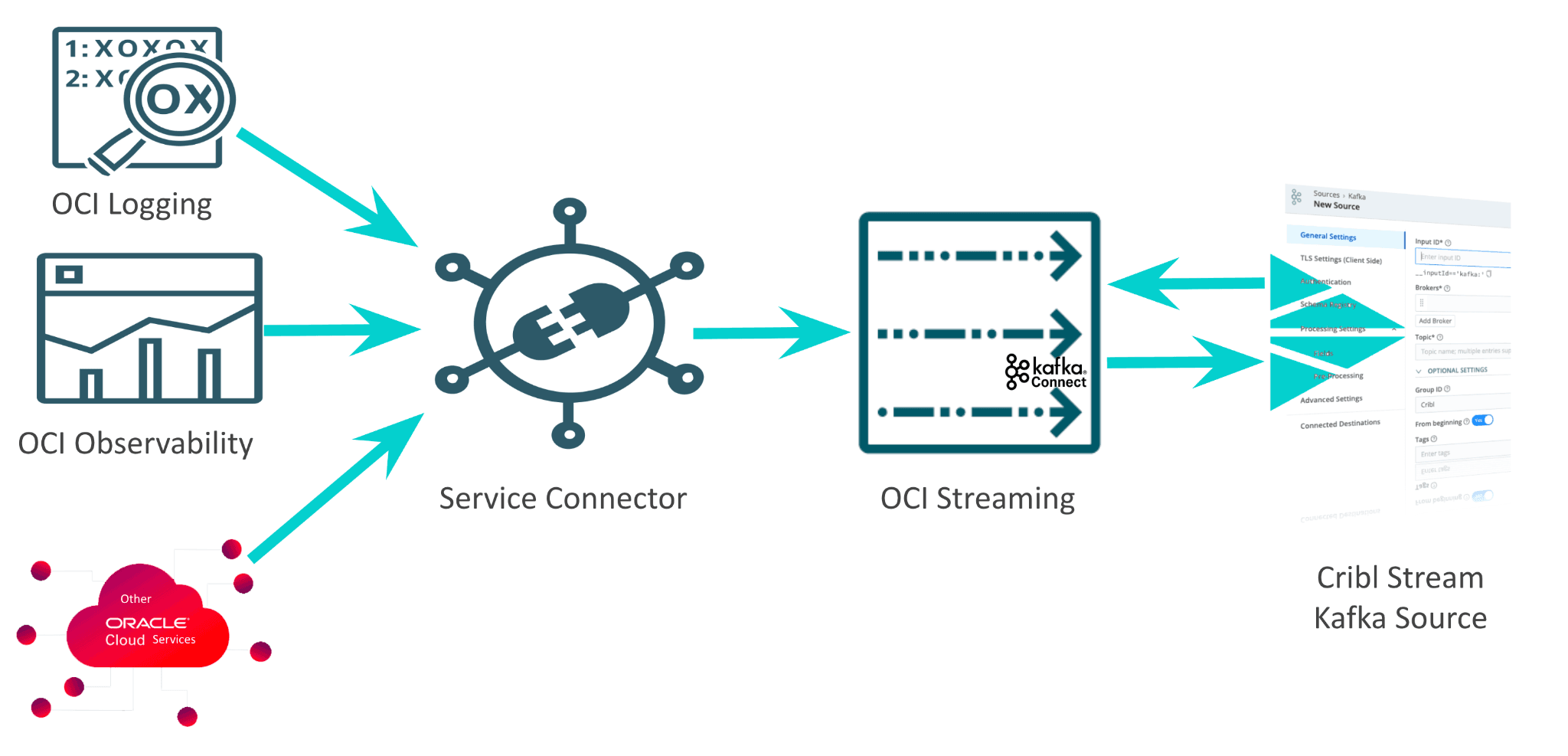
(recommended) Leverage OCI Streaming service, which is a Kafka-based service behind the scenes. Most OCI services can send data to OCI streaming via Connectors.
In this blog, I’ll discuss the recommended method of leveraging OCI Streaming. This is arguably the best way to expose OCI data to Cribl Stream, as it’s near real-time. With a Kafka backend, OCI Streaming also acts as a buffer until the events are processed. The Cribl Kafka source will poll OCI Streaming every 5 seconds. Common OCI data include VCN Flow logs, OCI audit logs, Cloud guard logs, application logs, and observability data.
Here’s a list of steps to get data flowing through Cribl Stream, along with a flow diagram:
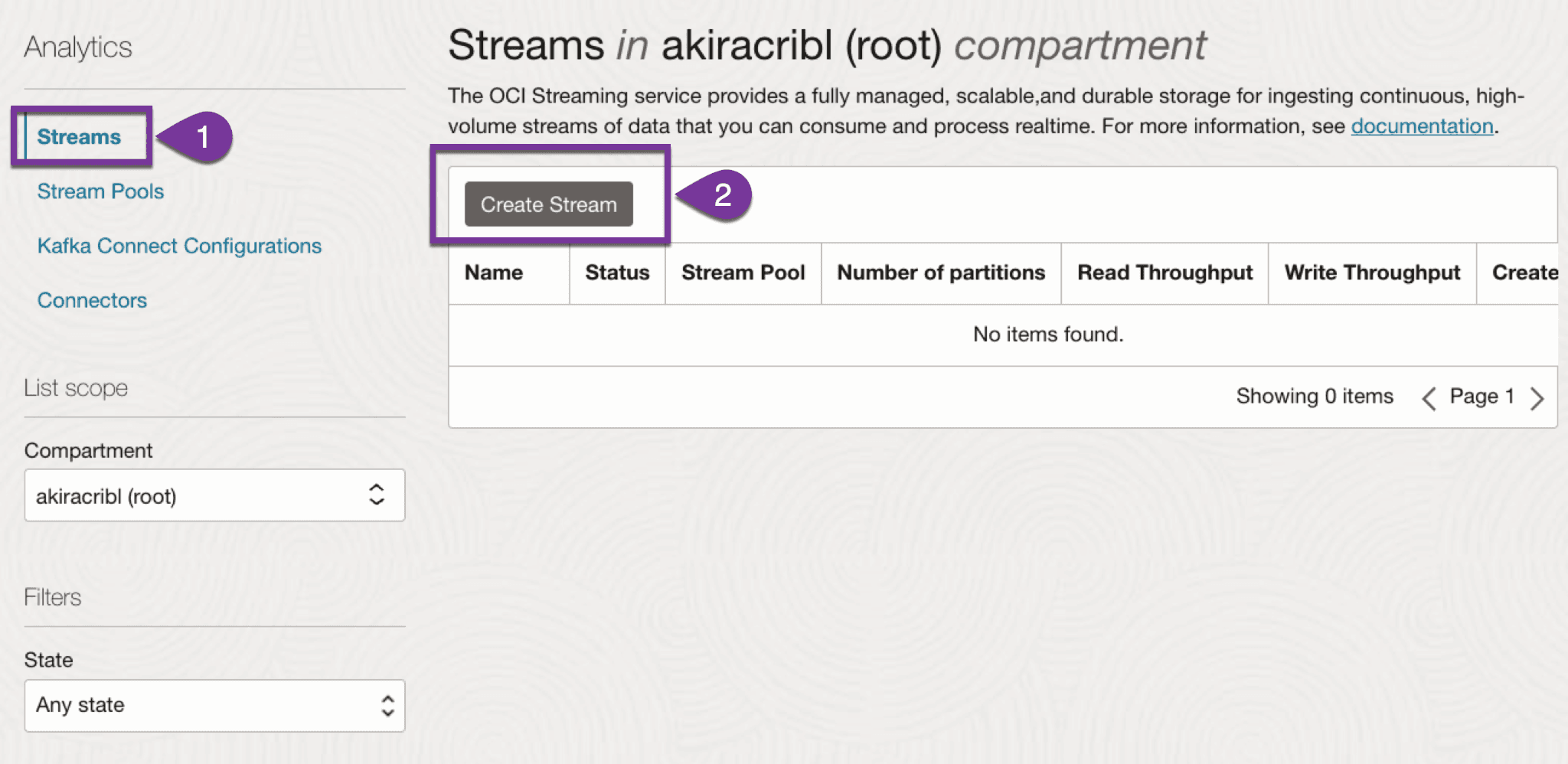
Create a new OCI Stream and Stream Pool
Create a ‘Stream Connector’ to send logs from an existing OCI service to the OCI Stream
Setup a Cribl Kafka source
Creating & Configuring an OCI Stream:
Within the OCI console, search for the stream service and select ‘create stream’ per the screenshot below:
Select to create a new Stream Pool per the below screenshot. Within the Stream Pool section, assign a public endpoint. This ensures access from Cribl workers running outside OCI.
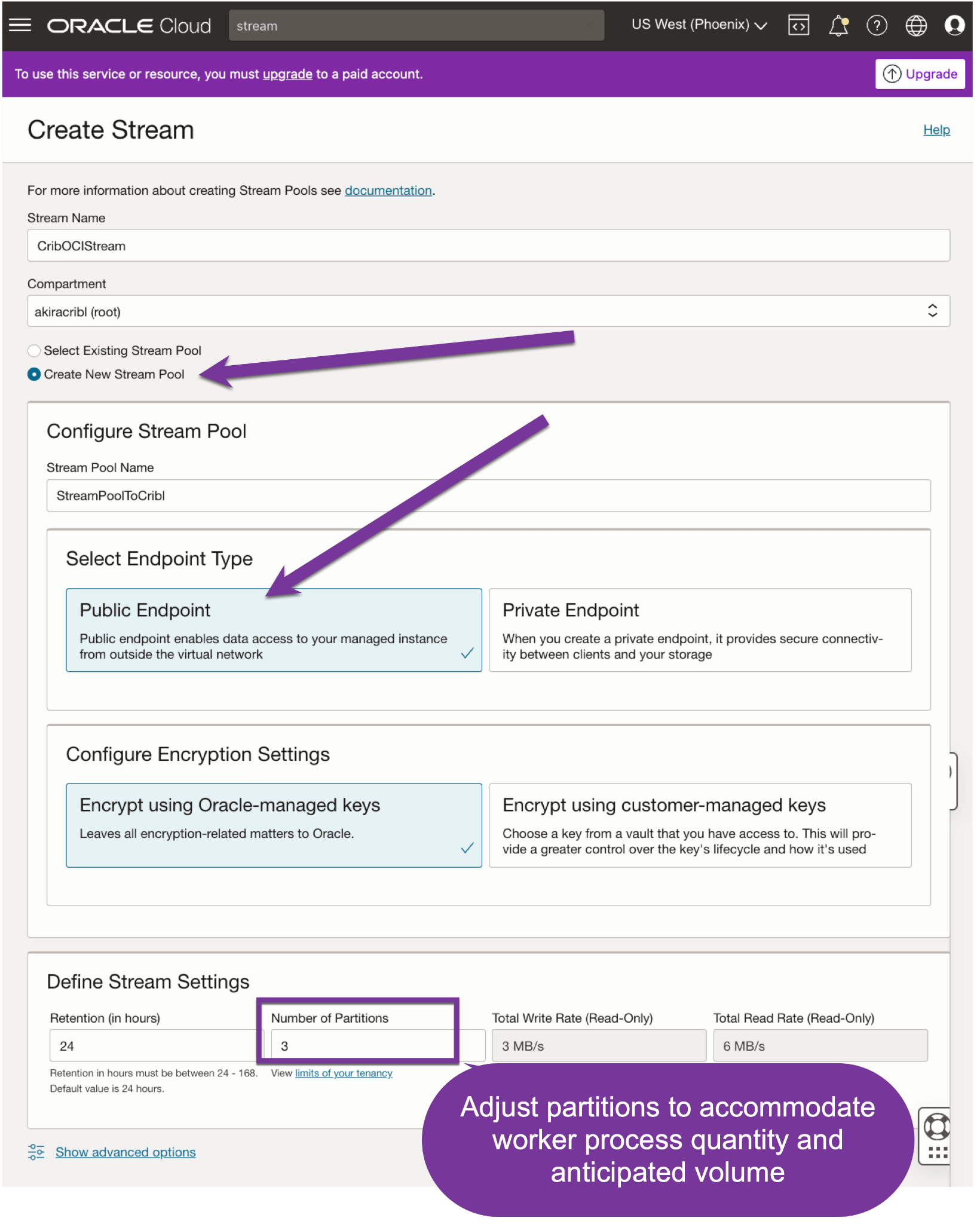
Adjust the partition count to accommodate expected data volume and worker process counts. Per OCI docs, a single partition is limited to a 2 MB per second data read rate and five GET requests per second per consumer group before being throttled. All Cribl workers within a worker group are treated as part of the same Kafka Consumer Group. With a share-nothing architecture, every Cribl worker process will poll OCI Streaming. To minimize throttling, create one partition for every five worker processes in the Cribl worker group.
Let’s take a real-world scenario. Suppose you have a large worker group with 150 worker processes. In that case, it is a better practice to create a smaller worker group with enough worker processes to accommodate the anticipated load from OCI streams to avoid throttling. For example, if we’re expecting 2 TB/day from an OCI stream, and we’re sending the data to 1 destination via a passthru pipeline, it’s better to have a worker group with 20 vCPUs rather than one large worker group with 150 worker processes to poll the OCI Stream.
After saving the OCI Stream and Stream pool configuration, the Stream should show an ‘active’ status after several minutes, similar to the screenshot below.

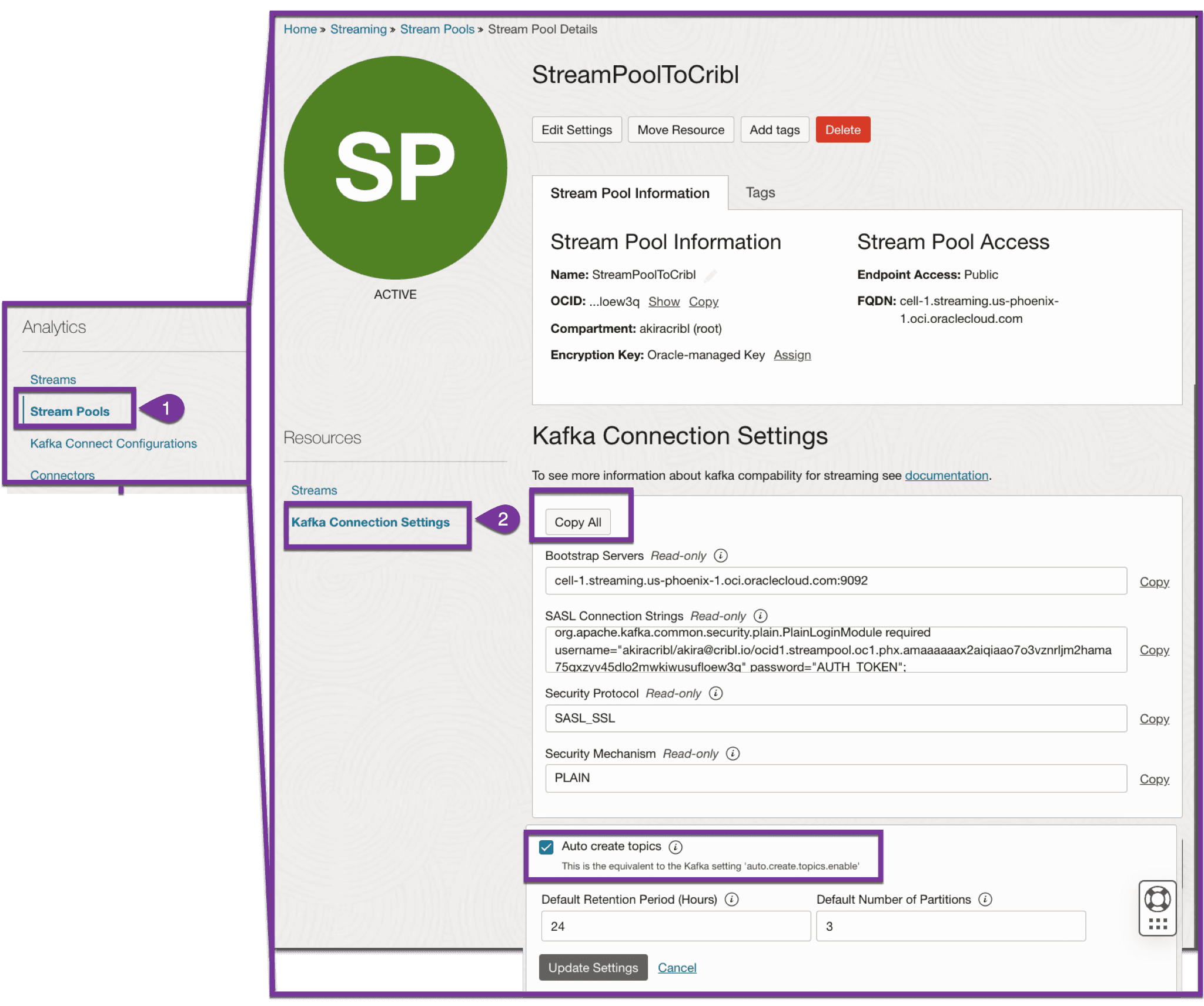
After the Stream and Stream pool are created, follow the directions within the Oracle documentation to create an auth token. This will involve accessing the stream pool Kafka connection settings, copying the SASL username from the connection settings, and then navigating to Profile | User Settings | Resources | Auth tokens.
Once the auth token has been established, access the Stream Pool configuration once per the screenshot below. Select ‘Kafka Connection Settings,’ and ensure ‘create a topic is selected’, and the partition quantity matches that defined previously. Also, copy all the credentials, as they’ll be needed when configuring Cribl Stream. Also, note the OCI Stream name and the OCI Stream pool name.
Mapping OCI logs & metrics to the OCI Stream
Now that the OCI Stream is live, OCI data can be published to the Stream. This is generally done through Service Connectors. Reference OCI documentation on how to publish logs to OCI Streaming and create a connector with a monitoring source. Below are screenshots of configuring a connector to pull events from the _Audit log group and publish them to an OCI Stream.
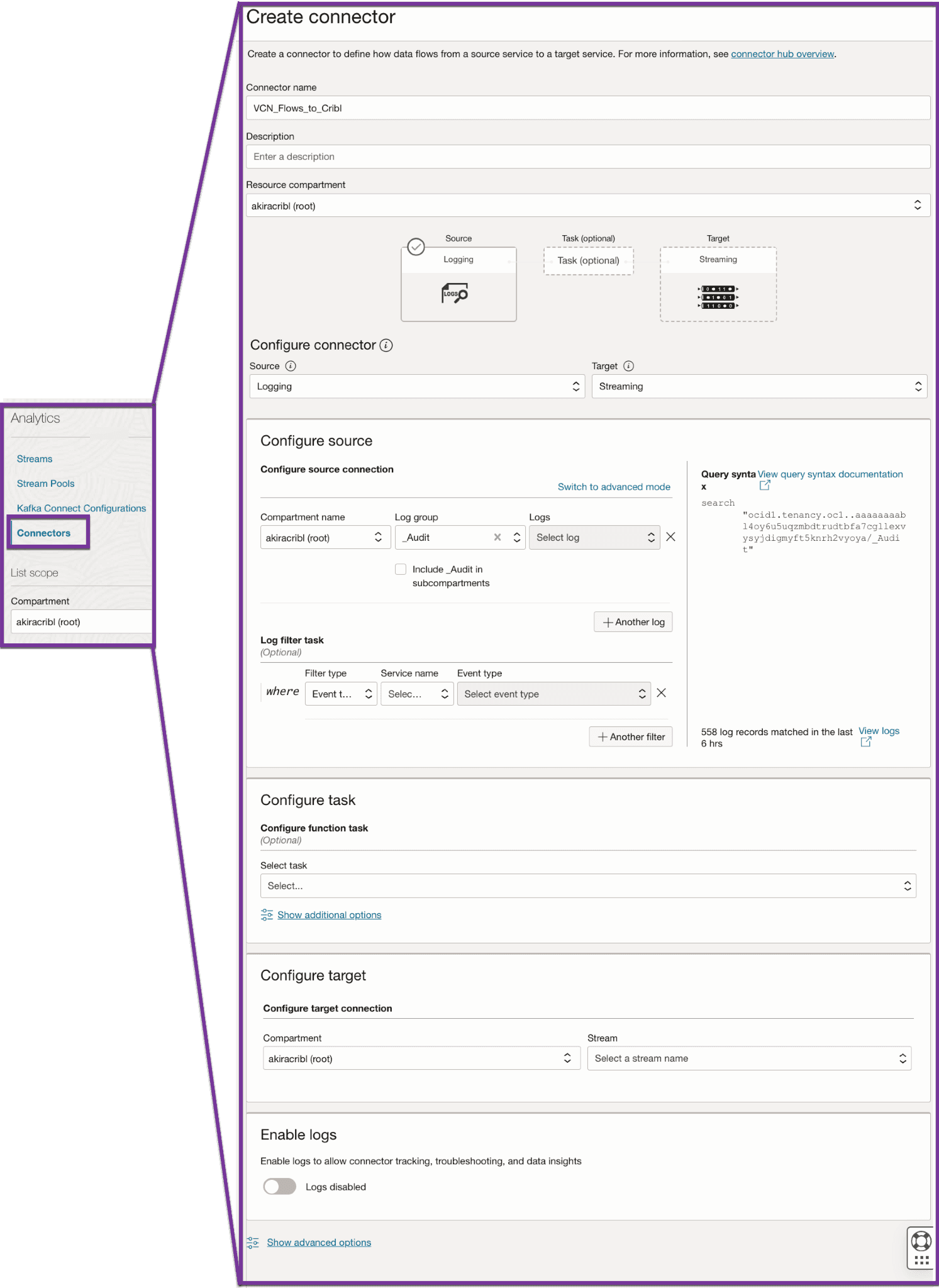
Configuring Cribl Stream
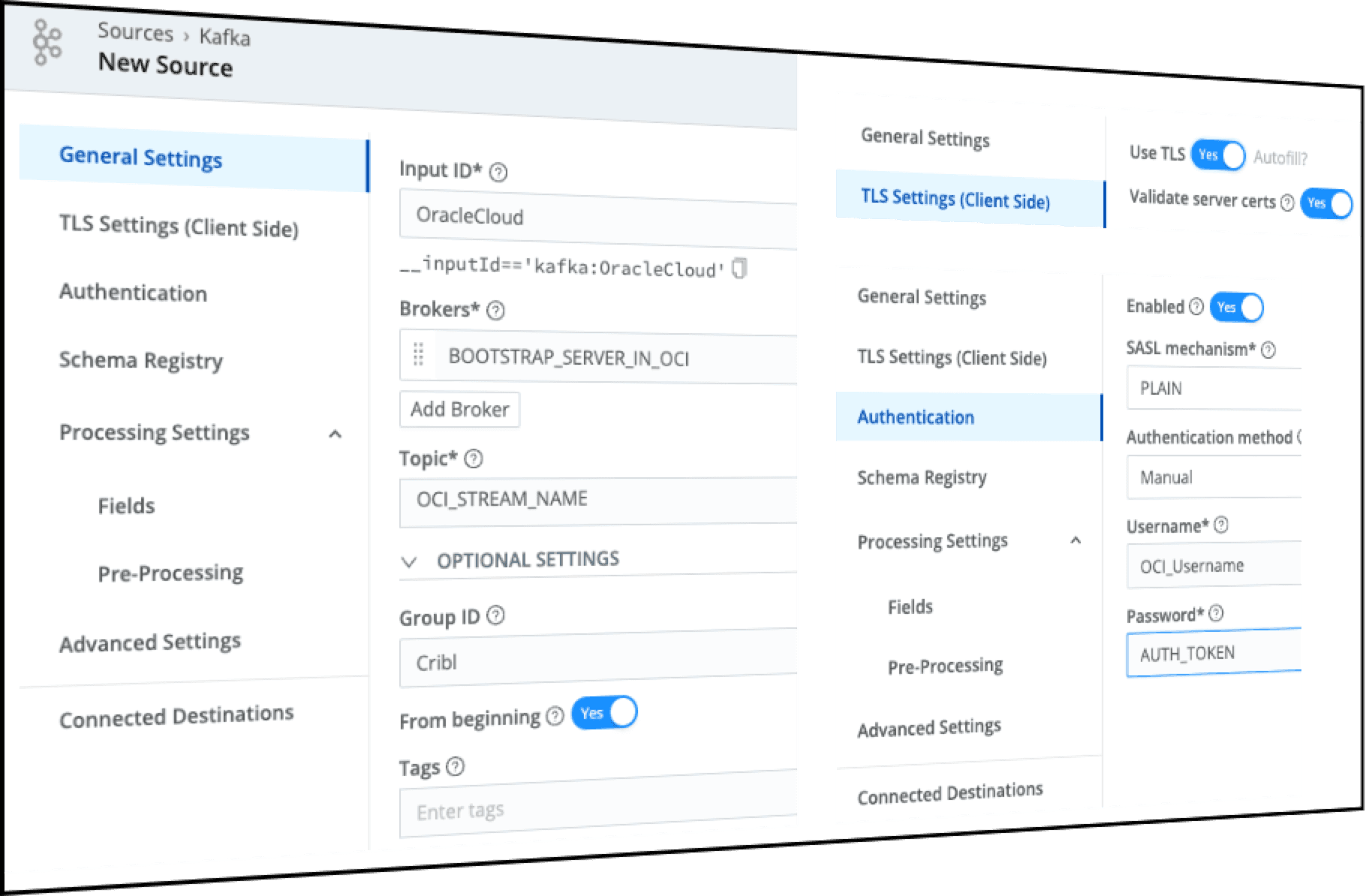
To configure Cribl Stream, you’ll need the following fields copied earlier from the OCI Kafka Connection settings:
Bootstrap server field
OCI Stream name (not stream ID)
Username string within the SASL connection string field
AUTH Token string within the SASL connection string field
Within the Cribl Kafka source, populate the following fields with the corresponding field from OCI Kafka settings:
Brokers field: specify the ‘bootstrap server’ from OCI
Topic field: specify the OCI stream name (NOT Stream ID)
GroupID: Specify a unique ID (i.e. CriblGroup)
TLS tab in Cribl: Select the ‘enable TLS’ ratio button. There is no need to specify any certifications, as we’d connect and validate OCI’s certifications. We can override TLS cert validation if necessary.
Authentication tab: Select ‘plain’ authentication, with username as referenced in the SASL connection string. The password would be the
AUTH_TOKEN
Here’s a screenshot with the various settings:
With this, you should pull Oracle Cloud data into Cribl Stream, optimize it, and then forward it to observability, security, and data lake destinations.
Wrap up
Leveraging Oracle Cloud Infrastructure (OCI) Streaming for log management and integration with Cribl Stream offers a highly efficient, real-time solution for handling diverse OCI data, including VCN Flow logs, audit logs, Cloud guard logs, application logs, and observability data. This blog detailed a practical approach to using OCI Streaming, backed by a Kafka infrastructure, for seamless data integration and management.
The key steps include setting up an OCI Stream and Stream Pool, configuring Stream Connectors for log routing, and correctly setting up a Cribl Kafka source for optimal data flow. Adjusting the partition count according to the anticipated data volume and worker process count is crucial to avoid throttling and ensure smooth operations. With these configurations, OCI data can be effectively channeled through Cribl Stream, allowing for enhanced optimization and routing to various destinations such as observability platforms, security tools, and data lakes. This approach simplifies the management of OCI logs and maximizes the potential of cloud data utilization.






