The newly released Cribl Search 4.2 brings enhancements that ease data management in today’s complex, cloud-centric environments. This update provides comprehensive compatibility with all major cloud providers – Amazon S3, Google Cloud Storage, and Azure Blob Storage. It also ushers in native support for Amazon Security Lake.
In this blog post, we’ll examine how new dataset providers enhance the value that Cribl Search delivers, out of the box. We’ll also walk you through our user-friendly, step-by-step guide to building and executing queries. Let’s begin!
Meet New Dataset Providers
The flexibility and scalability offered by cloud-based services are an absolute game-changer, making them an integral part of any data handling system. With Cribl Search 4.2, you can effortlessly navigate through your flow logs across all your cloud platforms, with queries as simple as:
dataset="aws_s3_flowlogs" earliest=-1h | limit 1000
This query selects from your AWS S3 flow logs dataset, limiting the search to the most recent hour, and to a maximum of 1,000 records.
Substitute “aws_s3_flowlogs” with “azure_blob_flowlogs” or “google_gcs_flowlogs” to fetch data from your Azure Blob Storage or Google Cloud Storage account, respectively. Let’s try each of these:
dataset="azure_blob_flowlogs" earliest=-1h | limit 1000
Or:
dataset="google_gcs_flowlogs" earliest=-1h | limit 1000
Advanced Federated Search Capability
This is great, but what if you want to search across all these datasets at once? Cribl Search takes federated search to a new level, allowing more efficient cross-dataset search and analysis.
By appending “_flowlogs” to the end of each dataset name, you can use a wildcard to search across them all simultaneously:
dataset="*_flowlogs" earliest=-1h | limit 1000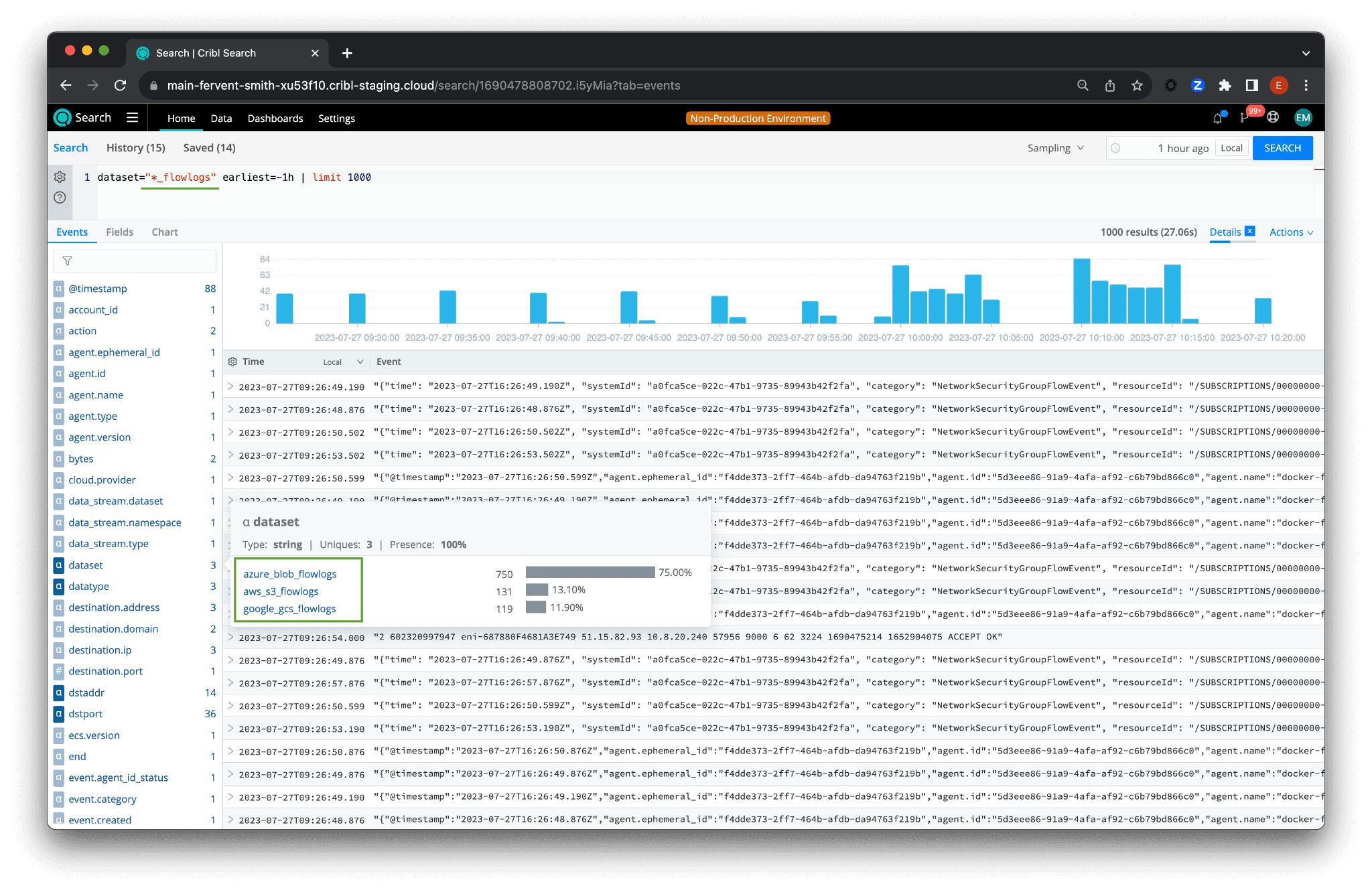
Now, let’s take a real-world scenario. For instance, consider a situation where a network administrator wants to identify traffic patterns across different ports and datasets within the last hour. The following query provides a solution:
dataset="*_flowlogs" | limit 1000 | summarize flowcount=count() by dstport, dataset | extend port_and_source=dstport + ":" + dataset | project port_and_source, flowcount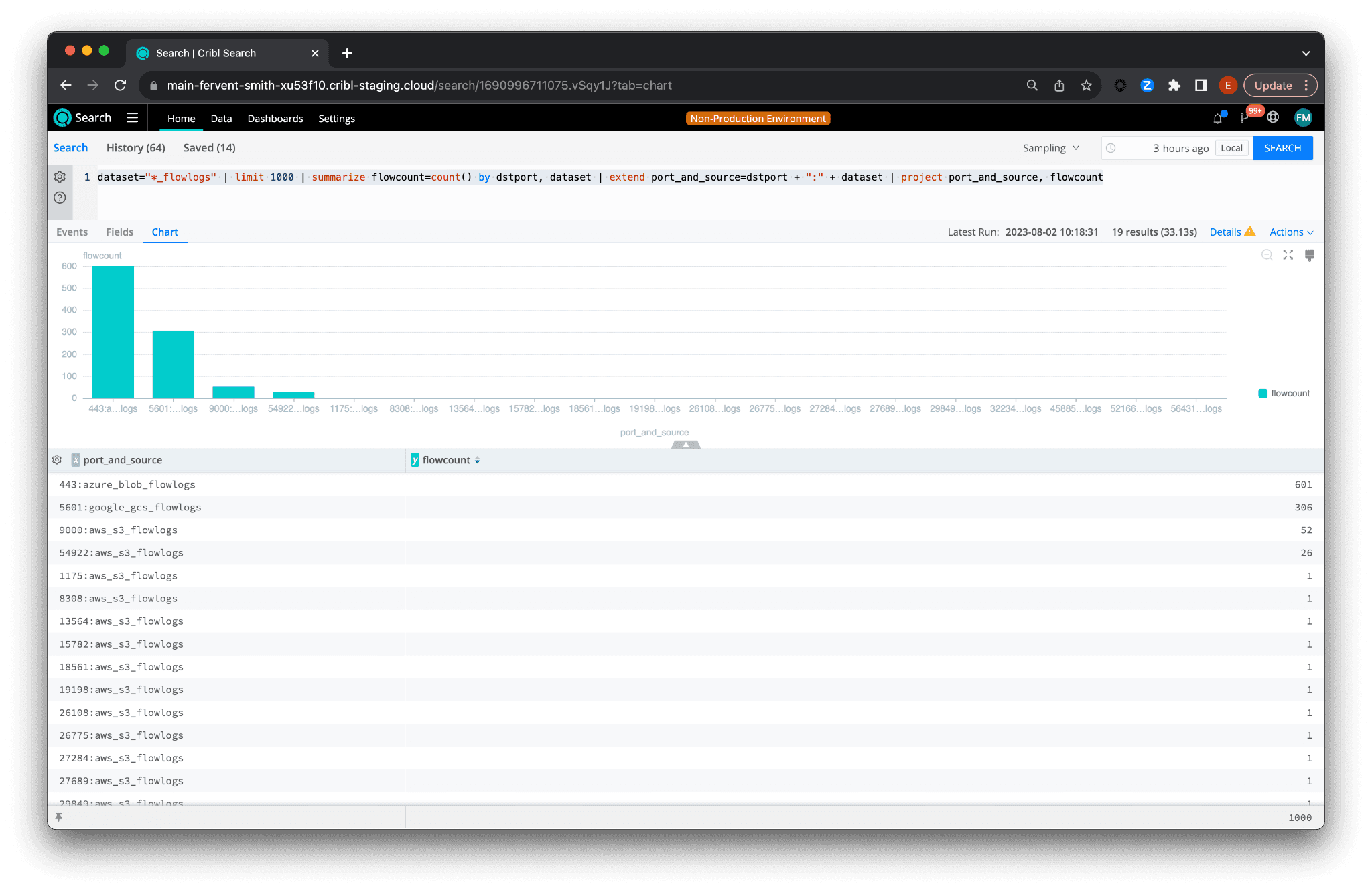
This query operates in the following steps:
dataset="*_flowlogs” – It starts by selecting all datasets ending with “_flowlogs”, allowing the network administrator to analyze traffic across all relevant datasets simultaneously.| limit 1000– The limit operation restricts the data pulled to the most recent 1000 records. It ensures that the system only processes a subset of the data while we are building out the query.| summarize flowcount=count() by dstport, dataset– The traffic across each port (dstport) anddatasetis then counted, providing a clear view of the traffic volume that each port and dataset has been handling.| extend port_and_source=dstport + ":" + dataset– To simplify the analysis, the query then generates a new column –port_and_source– that combines the port and dataset into one easy-to-read string.| project port_and_source, flowcount– Finally, it displays the newly createdport_and_sourceandflowcountcolumns, giving the network administrator a clean, straightforward view of the traffic patterns.
This is just one example of the countless applications of Cribl Search 4.2’s federated search capability, which makes data analysis easier and more efficient.
Native Support for Amazon Security Lake
We’re particularly excited about Cribl Search 4.2’s native support for Amazon’s Security Lake. This powerful integration takes advantage of the open-source Cloud Security Framework (OCSF) and the efficient Parquet data format.
With this functionality, Cribl enables efficient querying, allowing you to filter and manipulate datasets at the source.
The query below accesses the Amazon Security Lake stage, limiting the search to the 100 most recent records:
dataset="amazon_security_lake_stage" | limit 100
And for an added layer of depth, use Projection & Predicate Pushdown to categorize and summarize data by disposition:
dataset="amazon_security_lake_stage" category_name="Network Activity" | summarize count() by disposition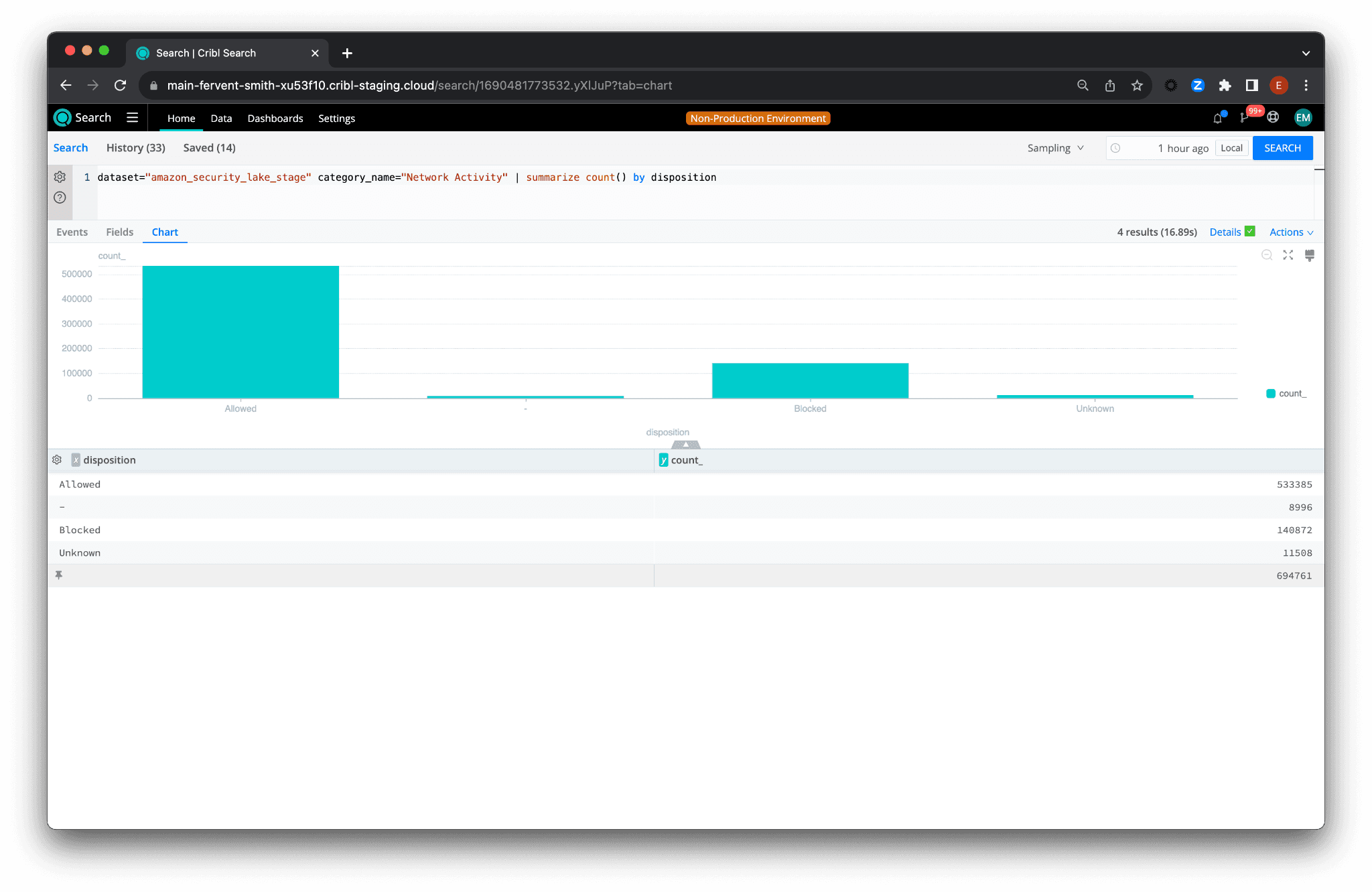
To sum up: With Cribl Search 4.2, extracting meaningful insights from vast data lakes has never been easier. This latest release underscores our commitment to creating a flexible, user-friendly data exploration environment – irrespective of your chosen cloud platform or security solution. We can’t wait to see how you leverage these powerful tools to unlock new insights from your data.
Happy searching!