

For years, enterprise log management has been a story of unintended consequences. What started as a security tool quietly became the default home for every log in the environment. Security events, app performance data, infrastructure metrics, debug logs — all landing in the same SIEM, billed at the same rate, whether your SOC ever looked at them or not.
If you're a security practitioner managing pipelines today, this pattern probably feels familiar. And if you've already deployed Cribl Stream to get your data under control, you might be closer than you think to solving the rest of the problem.
How we got here
It started simply enough. Early SIEM tools like ArcSight needed custom connectors for every new data source. It was a slow, risky process that left gaps in coverage while teams waited weeks for integrations.
Then came a new generation. Splunk Software, Logstash, and open-source peers that would ingest almost anything. Teams added more sources. More teams started relying on the same platform. ROI expanded beyond security into observability, and suddenly the “security stack” was carrying the full weight of the organization’s logging infrastructure.
The fallout:
Massive platforms that need dedicated headcount just to keep running
Escalating cloud costs as data and use cases explode
Security and observability teams both paying to index the same data
The hidden cost of one big destination
One customer running a large Elastic deployment ended up in a spot that’s more common than most teams admit: years of organic growth had turned their security platform into the default destination for every log. App performance data, infra metrics, debug logs — everything flowed into the same stack, managed by a sprawling fleet of Logstash servers across Azure and AWS.
That created two compounding problems that quietly drove TCO through the roof.
1. Scale
Managing more than 100 Logstash nodes across two cloud providers meant:
Constant tuning and upgrades
Ongoing compute spend
A dedicated team just to keep pipelines alive and stable
2. Duplication
Because application logs, infrastructure metrics, and security events all flowed to the same platform, both security and observability teams were paying to index the same events with their respective vendors. No one planned it. No one was tracking it. It was just an artifact of organic growth and “ship it all to the SIEM.”
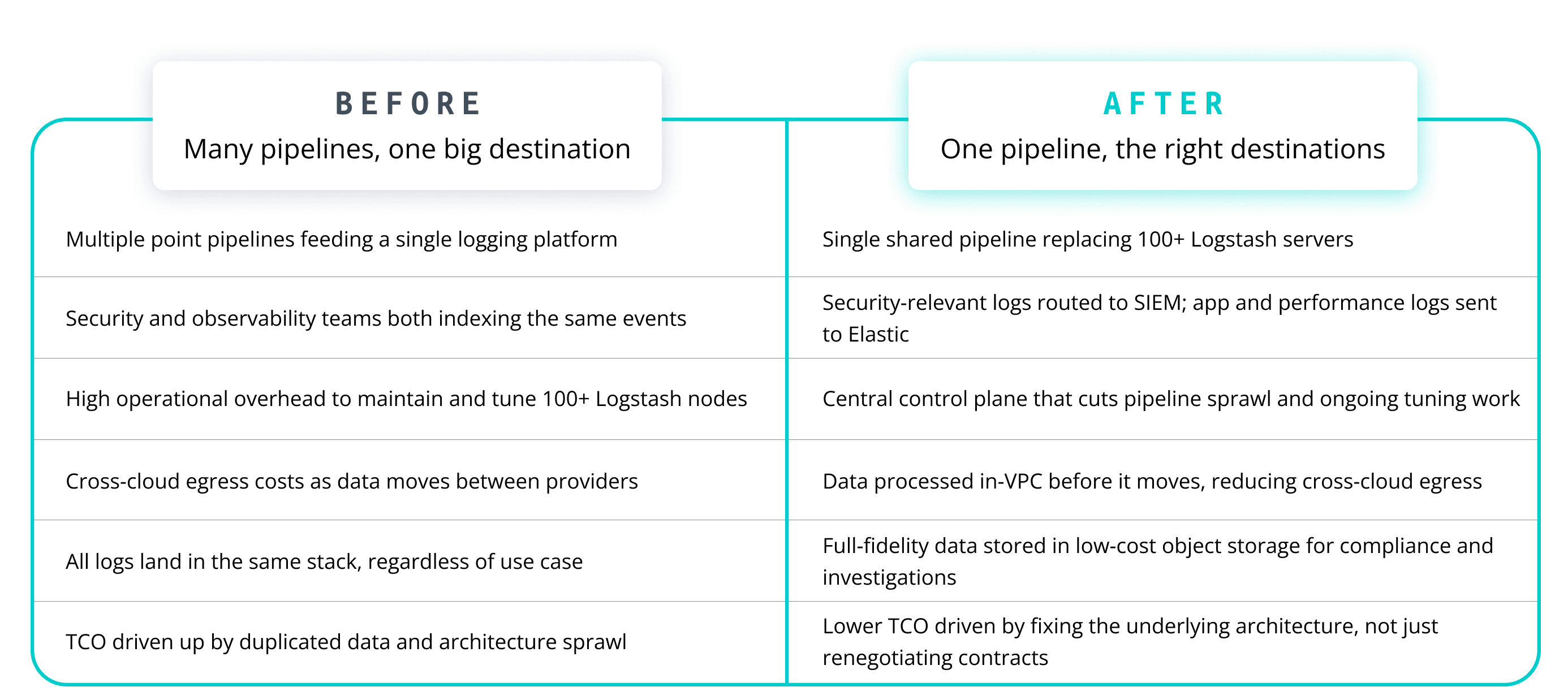
One pipeline, the right destinations
Cribl Stream gave that customer a way out of both problems at once. By replacing their Logstash fleet with a hybrid Cribl deployment across their Azure and AWS VPCs, they were able to:
Eliminate over 100 Logstash servers and reclaim the associated compute costs
Route security-relevant logs to their SIEM while sending app and performance logs to Elastic — from the same pipeline, without extra agents or brittle transforms
Cut cross-cloud egress spend by processing data inside each VPC before it moved
Store full-fidelity, unfiltered data in low-cost blob storage for compliance and investigations
Here’s what changed:
The net result was a significant TCO reduction that didn’t come from squeezing vendors. It came from stopping double-indexing and cleaning up years of architectural drift. Once the team could split the same telemetry stream by destination, they stopped paying two vendors to index the same events.
This is the crux of what Cribl Stream makes possible for security practitioners: collapsing dozens of brittle, single-destination pipelines into one shared control plane that serves your SOC, SRE, and IT teams — all from the same data, without rebuilding your world from scratch.
Extend further with Cribl Search

For teams ready to go further, Cribl Search adds an investigation and analytics layer on top of this architecture.
Instead of pushing every log into an analytics platform “just in case,” you can:
Keep full-fidelity data in low-cost storage
Use Cribl Search to explore, correlate, and retrieve only what matters
Support both security investigations and observability workflows from the same underlying data
You don't need a second pipeline. You need the one you have to work harder.
It should collect once, route smartly, and search what you need, when you need it.
If you want to get there without managing infrastructure, you can run this entire stack in Cribl.Cloud, and process up to 1TB/day for free.






