Cribl Stream™
Get the data you need, in the format you want, wherever it needs to go.
Collect, reduce, enrich, and route data in real time, without blowing your budget.


In a nutshell
Cribl Stream is the industry's leading observability pipeline, letting you collect, reduce, enrich, and route telemetry data from any source to any tool, in the right format.
Stream is your go-to solution for handling the variety and volume of telemetry data without blowing up your budget.
Whether you're dealing with megabytes or petabytes, Cribl Stream scales easily and gives you the flexibility and control to handle any data, your way.
Benefits
Cribl Stream gives you the flexibility, control, and efficiency to manage data smarter, cut costs, and get actionable insights—while reducing complexity and improving tool performance.
Connect quickly to 80+ data sources and destinations, or use Cribl Packs for seamless integration. No complex setup required.
Cribl Stream adapts as you grow, handling small volumes and massive enterprise-scale deployments with ease.
Use strong encryption and granular access controls so only authorized people can see sensitive data.
Boost performance and lower costs by stripping out unneeded fields or events, so your team and tools focus on what actually matters.
Easily tailor data with Stream's data processing capabilities, or map, filter, and transform events with our AI-powered Copilot Editor.
Set detailed data policies and standards to keep compliance on track and manage data precisely across its lifecycle.
Customer success
Features
With Cribl Stream, you can adapt quickly to changing telemetry requirements.
Use Copilot Editor to map schemas, transform, and filter data with plain language prompts.
Integrate with 80+ sources and destinations and use portable Packs to move entire pipelines as reusable bundles.
From small deployments to enterprise scale, Stream fits your needs without new infrastructure or agents.
Cribl Stream turns the messy work of collecting, optimizing, and routing telemetry into a streamlined, intuitive process.
Collect, transform, and route data across your ecosystem with portable Packs that cut operational overhead.
Use AI-driven plain language commands to schematize, transform, and filter your pipelines instead of writing complex rules by hand.
Stream’s processing engine lets you shape and refine data for better utility and less manual effort.
Use Cribl Stream to get real control over your data and evolve your data management strategy.
Enforce consistent data policies, standards, and formats across all your tools, and tap into portable Packs and fast lookups for secure, scalable enrichment and compliance.
Maximize the strategic impact of your data with Stream’s routing, storage, and analysis capabilities so every data point adds value.
Highlights
All your logs, none of the hassl.
Cribl as Code gives security, IT, and engineering teams programmatic control to automate, configure, and manage their Cribl environment.
Use REST APIs, Python, Go, and TypeScript SDKs, or Terraform to onboard sources, build and maintain pipelines, and standardize workflows faster, at any scale, with no vendor lock-in.

Cribl Packs are ready-to-use bundles that package data routes, pipelines, and configurations so you can share and deploy them quickly.
Collectors are now fully supported in Cribl Packs, so you can manage and ship data from cloud, databases, and APIs in a single portable solution.

Cribl Guard uses AI to spot sensitive data (like credit cards or social security numbers) as it flows through Cribl Stream.
Human-in-the-loop review lets operators approve or override actions before data is masked or blocked.
Custom rules and seamless pipeline integration help cut false positives, streamline compliance for GDPR, CCPA, HIPAA, PCI, and improve risk visibility and control across your environment.

Capabilities
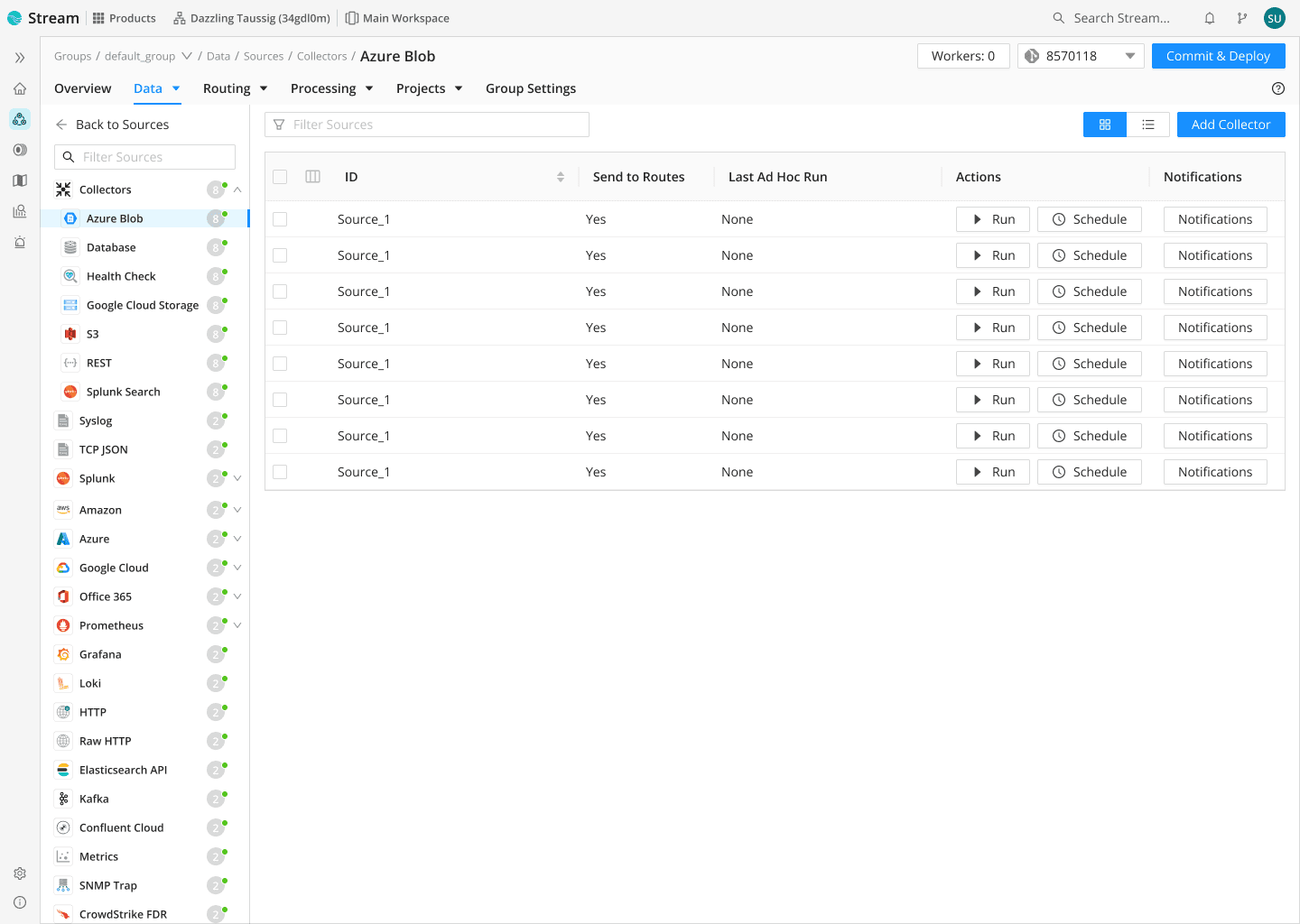
Cribl Stream is your telemetry butler, serving up any format for any of your analytics tools.
Use Stream observability pipelines as your universal receiver to collect from any data source: pull from all your agents and push-based sources, rapidly onboard new data using AI-guided schema mapping, collect telemetry from agents, batch endpoints, and APIs, and recall data from low-cost storage when you need it.
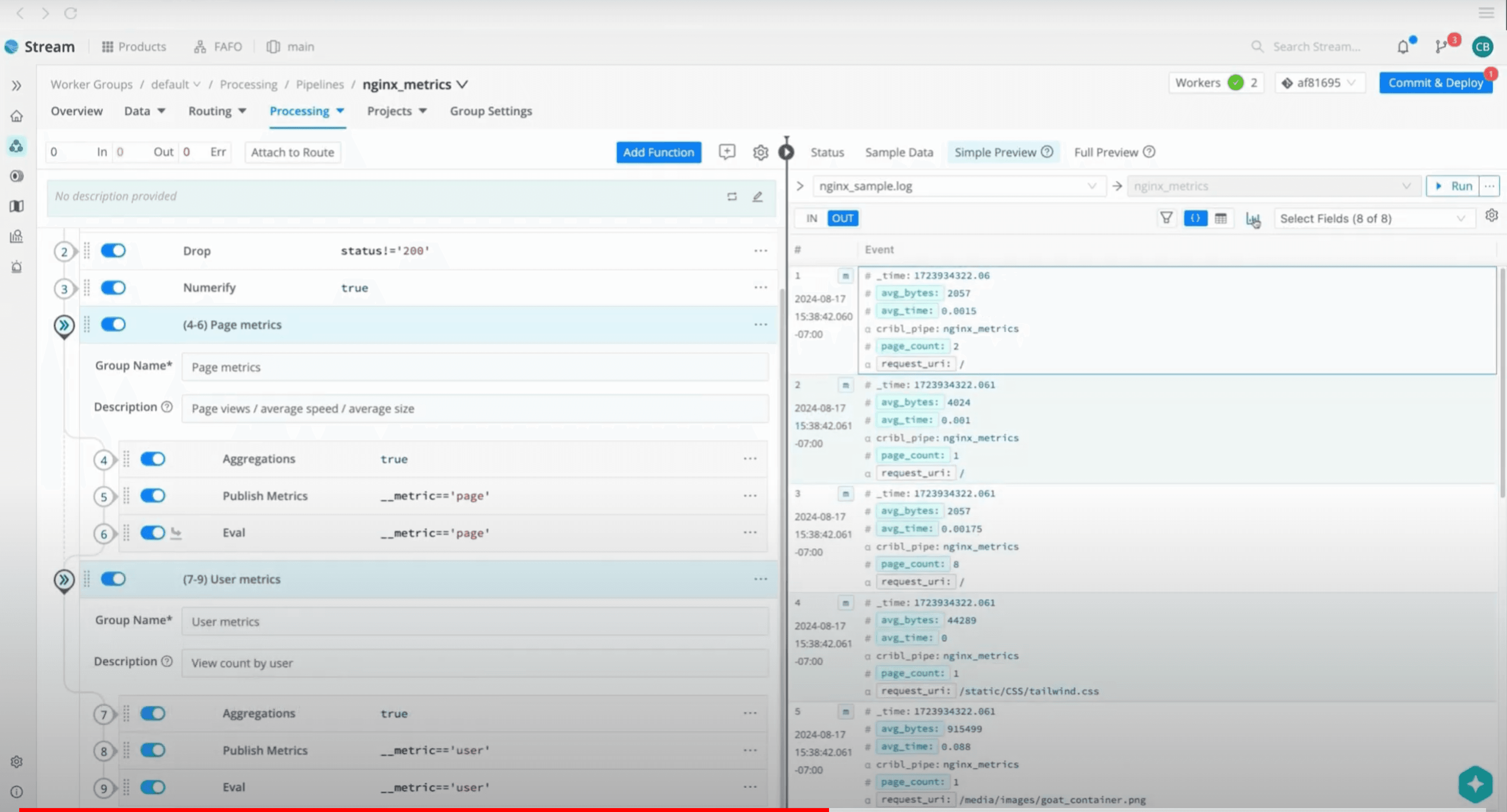
Control costs, improve performance, and optimize licenses by reducing log volume.
Filter out irrelevant events and fields using plain language, apply generic transformations, and auto-map schemas for analytics-ready data.
Use dynamic sampling to filter events or roll up logs into metrics to cut volume.
Keep a full-fidelity copy in low-cost storage or your data lake, and replay it when you need it.
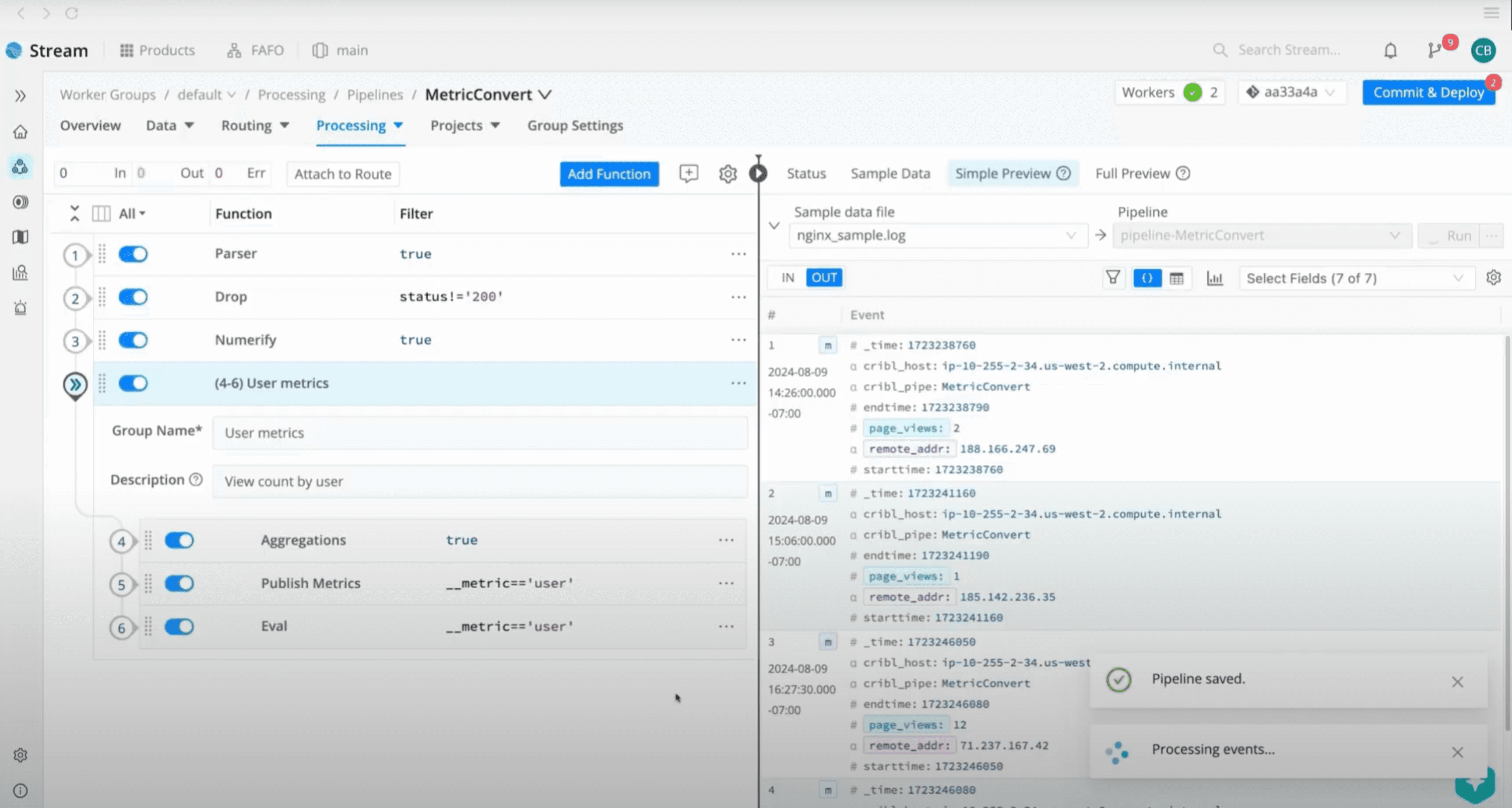
Turn your data into decision-ready information.
Translate and transform data from all of your sources into the formats your tools expect.
Enrich logs with third-party data for a more complete picture.
Stream collects from all of your sources and shapes it into actionable logs and metrics for analysis.
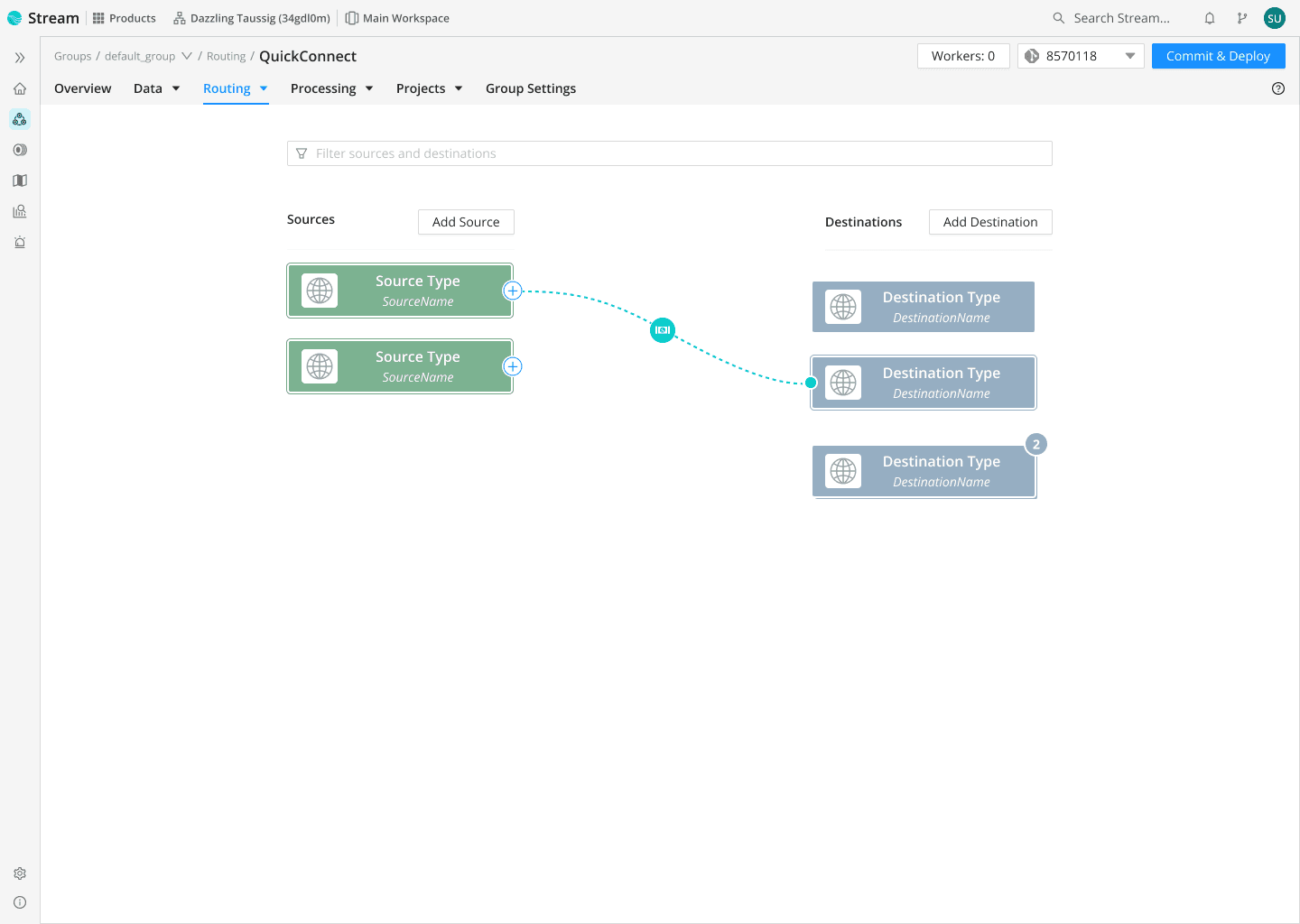
Send your data where it works best: Splunk Software, Elastic, New Relic, DataDog, or offload to Cribl Lake for long-term retention.
Route data to the right tools by translating it into the required formats, or use Packs to slash onboarding time.
Let teams pick their analytics environments without deploying new agents or forwarders.
Replay data on demand from Cribl Lake, S3, or your favorite low-cost lake.
Store data affordably and pull it back only when needed for security audits, incident investigations, operational recovery, or just peace of mind.
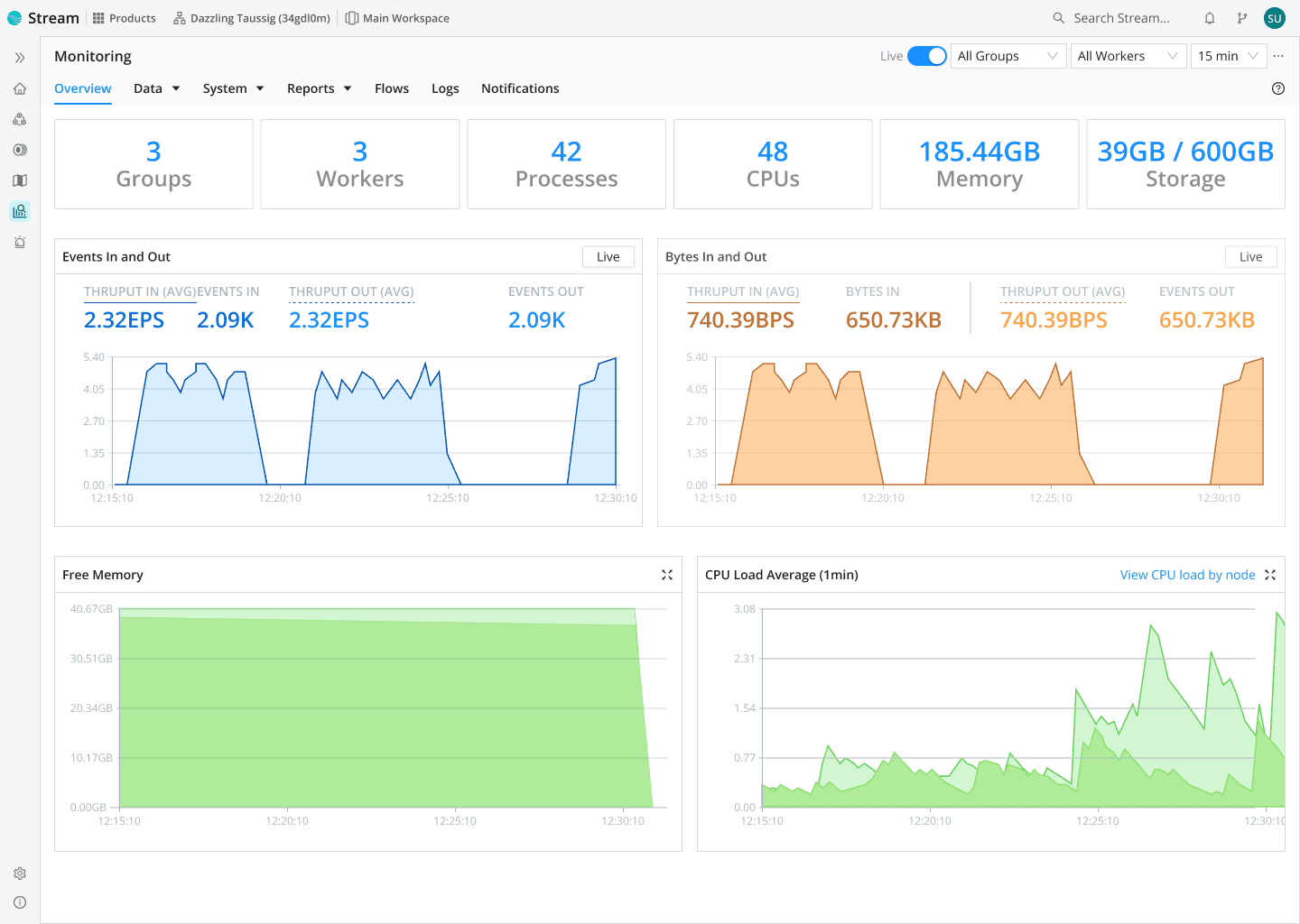
Consolidate data flows into a central tier for collection, processing, and routing.
Simplify data management and ease the load on your teams while keeping full control of your data.
Differentiators
Ingest, transform, and route data without lock-in
Collect telemetry from any source, transform it as needed, and deliver it to any destination with confidence.
Onboard new tools without rolling out more agents or collectors.
Built for IT and Security data scale
Stream is purpose-built for the volume, velocity, and variety of logs, metrics, and traces in modern IT and security environments.
Engineered for petabyte-scale throughput
Process billions of events per second with sub-millisecond latency and massive scalability on-prem, in the cloud, or hybrid.
Fits any architecture, any workflow
Deploy Stream on its own or as part of a unified data engine that slots cleanly into your ecosystem.
Flexibly route, enrich, and reduce data to meet the needs of every team and tool.
Trusted by leading enterprises to deliver results
Cribl Stream is battle-tested in complex, global environments, reducing petabytes of daily data, cutting ingest and storage costs, and scaling from initial pilots to mission-critical deployments without re-architecture.
Customers rely on Stream to meet strict performance, compliance, and resiliency requirements while keeping optionality across their SIEM, observability, and data lake stacks.
FAQ
Integrations

Boost search performance and data processing efficiency by using Cribl Stream with Cribl Search.
Gain real-time data retrieval and deeper, more actionable insights, and streamline operations across your security landscape.

Using Cribl Edge? Add Cribl Stream to further filter, process, and forward data so only high-value data reaches your analytics tools.
Handle massive datasets more efficiently while cutting bandwidth and storage costs.

Connect Cribl Stream with Cribl Lake for a unified data management experience that covers both real-time streams and your deepest data lakes.
Enhance storage and retrieval for stronger analysis and better decisions.
Resources

get started
Cribl Stream transforms how you handle data. Easily ingest, process, and route it to where it needs to go.
Start using Stream today to unleash the power of your data!







