

What do you need to achieve observability? Who you ask and the role they hold will influence the answer, but the answer likely follows this pattern: “You only need [metrics|logs|traces] and not [metrics|logs|traces] because [use case] is how you define observability.”
I cannot disagree with this logic. A specific use case may only need a specific type of telemetry. Experience and expertise allow engineers to quickly answer questions about a system without expanding into adjacent data types. While the answers may seem obvious to experts, building teams of similarly skilled engineers to solve novel issues and challenges is difficult to scale. My problems are not the same as your problems, and my outcomes are not your outcomes, so why do we believe that there is a one-size-fits-all solution for observability?
These answers become more nefarious when we let a technical bias become a poor excuse for excluding one type of signaling over another. Worse yet, insisting that a specific view of the world is the only view that matters is a terrible approach to solving complex problems. In this blog, we will explore the origins and future of observability and how making decisions in the context of observability can be framed beyond the pedantic arguments of tabs vs. spaces, vim vs. vi, or Linux vs. Windows vs. MacOS.
To put observability in context, we must step back and ask ourselves, “Why do we need to understand the state of our systems?” The answer is always some version of “I need to understand the state of a system so that I know how to respond to a situation.” To learn how we decide the proper response in a situation, we will explore observability and the Cynefin framework (pronounced kuh-NEV-in) for decision-making and the unique approaches when system states are Simple/Clear, Complicated, Complex, or Chaos.
Observability should focus on system states that are Complicated, Complex, Simple, and Chaotic – in that order – even when it feels like most of our time is spent in Complex and Chaos!
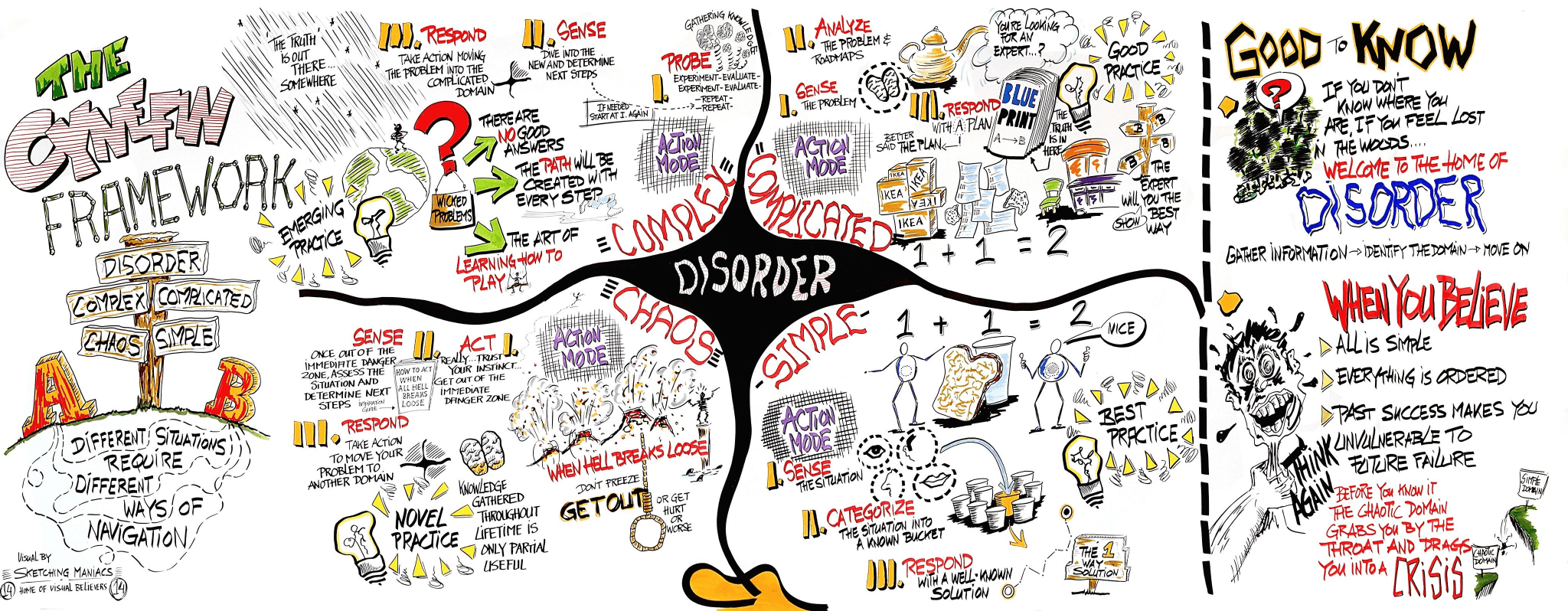
A sketch, by Edwin Stoop of Sketching Maniacs, of the Cynefin framework, a decision-making tool used in management consultancy
Innovation lives in the Complex state and we may have a bias toward systems that exist in this state without understanding that observability requires transitioning clockwise through the framework. While exploring complex decisions can be exciting, one cannot survive on complexity alone. Creating a path and discovering good answers to be tested by those with the required expertise is essential for sustainability.
Expertise thrives in the Complicated state, distilling the discoveries from the Complex realm into actions. This is where most IT and security teams live, testing, iterating, and applying good practices for repeatable, though not always certain, results.
Operational excellence is achieved when we reach the realm of Simple (now called Clear in the updated framework), where an action has a high probability of success, perhaps even certainty, within a given situation. While it may seem that distilling everything from Complex to Simple is the goal, that thinking is not only impossible but dangerous too. To assume that everything can be defined by prescribed inputs and outputs ultimately leads to Disorder and Chaos when the unexpected occurs.
Observability should enable an orderly transition from Complex through Complicated with a goal of Simplicity. Unfortunately, Chaos is a reality and observability requires the ability to quickly move from a state of chaos to complexity where innovation unlocks the path to the stability of merely complicated. Tools built for living in a chaotic state are not observability tools, they are monitoring tools masquerading as something else. Remember, “different situations require different ways of navigat[ing]” and it is the responsibility of observability to power that navigational experience.
Within the Cynefin framework, consider the actions in Complex vs. Complicated. Complexity requires Probe, Sense, and Respond – a series of steps rooted in curiosity where the “unknown unknowns” are tested and evaluated until a pathway out of complexity is discovered. In a Complicated state, we Sense, Analyze, and Respond with a foundation of expertise and knowledge and a series of dynamic but known states that will help us establish Simple/Clear operations.
Intrigued by the Cynefin framework and its applicability to observability? Read on!
Think about the definition of observability from the source of the idea, the 1953 paper entitled “On the General Theory of Control Systems,” which says:
“The state of a dynamic system is the smallest collection of numbers which must be specified at time … in order to be able to predict the behavior of the system for any [future] time . In other words, the state is the minimal ‘record’ of the past history needed to predict the future behavior.”
What is a dynamic system? Any system that changes through an interaction with an external system. In practical terms, a system can be a server, application, network device, or service. It is also a group of any of those individual system elements that deliver an outcome. Think about an application cluster with multiple instances of an application connected by a network, running on multiple instances of an operating system. That is a dynamic system.
That definition makes the observability of a dynamic system the outcome of instrumentation and monitoring, and an exercise in finding the optimal number of data points to predict the future state of that system, not an argument over signal types. In the context of the Cynefin framework, observability begins in the Complex, lives in the Complicated, and enables the Simple (now Clear) while avoiding Chaos whenever possible.
Now contrast that with the definitions of observability as captured on Wikipedia for Observability (software). Read through the quotes and determine which of those statements resonate with you. Did you find one? Good.
In an exercise of empathy, reach out to another team in your company that does not do the same work as you and ask them to identify the quote that resonates for them. If you ask 10 different people, you will likely get 11 different answers! That is because context matters when answering the question, “What is the current and future state of a dynamic system?”
Consider the challenge presented to any modern enterprise — complex systems with different points of instrumentation and measurement that require context to differentiate the impact of one complex system on another. Network latency on an ETL job may have a wide tolerance, whereas the same latency in a fintech trading platform would be considered a catastrophic failure. Complex systems are unsustainable at scale and must transition operations to Complicated and Simple, or Clear, to survive.
Both the Complicated and Simple realms of the Cynefin model have Sense as the first action, as establishing context before asking questions or deciding how to respond is critical. The transition through the states of the Cynefin framework requires that we deliver the right signal types to the right place at the right time, and with the right granularity. For observability within IT and security, you need a data engine for logs, metrics, and traces, an engine that must allow IT and security teams, often responsible for the collection, transformation, routing, and storage of the monitored signals, to deliver the telemetry needed to answer questions about complex systems to a diverse set of teams.
Remember, observability isn’t a trophy for collecting the most data points but a quest for understanding, the rigorous pursuit of curiosity, connecting dots across disparate data types to unveil the story beneath the surface. Raw data may power innovation in the Complex realm, but the actions of Complicated demand a more curated approach and Simple/Clear systems cannot be achieved without it.
Observability is not telemetry alone, nor is it a particular visualization or query environment. Observability is enabling teams to answer questions about their systems with the tools and telemetry that matter to them. Observability is powered by a data engine for IT and security, whether logs, metrics, or traces fuel that data engine and, to quote Wesley, the hero of The Princess Bride, “Anyone who says differently is selling something.”







