


OpenAI’s new Privacy Filter is a meaningful release because it offers teams an open-weight model for finding and redacting sensitive content, reflecting real progress in privacy tooling for AI systems. As AI enables the creation of increasingly sophisticated phishing attacks, putting people and their companies at risk of breaches, protecting personal information has become crucial. Furthermore, OpenAI activity is now becoming an integral part of the telemetry pipeline, which means that privacy filtering in this context differs from filtering in documents or standard business text. Since prompts, responses, metadata, logs, and machine-generated records all move through the same operational path, detection must work inside the telemetry itself, not outside of it.
OpenAI has moved the space forward
OpenAI’s Privacy Filter moves privacy tooling forward in a practical way by giving builders an open model they can run in their own environments, apply to sensitive workflows, and adapt to their own controls.
For many text-heavy use cases, that kind of model is a strong fit. It can help teams review content, reduce exposure, and build stronger privacy guardrails around AI applications.
Operational pipelines present a different workload.
Telemetry is different from plain text
At Cribl, we specialize in telemetry data composed of system logs and machine data. Telemetry is full of semi-structured content, nested fields, abbreviated values, vendor-specific formats, and machine-generated syntax. Sensitive values rarely appear as neat natural-language spans. Instead, they often sit inside keys, delimiters, serialized payloads, query fragments, or protocol-specific structures.
When it comes to security and observability, detection of sensitive data has to work correctly inside the shape of real telemetry and at the speed production systems require.
Security and compliance teams need visibility into how AI is being used, by whom, and with what content. They need to monitor for possible IP leakage, identify policy violations, maintain an audit trail for regulated workloads, and feed AI activity into the same detection and reporting workflows they already use across their environments.
Once prompts, responses, and metadata are part of that pipeline, privacy filtering has to perform well on telemetry, not only on polished text samples.

Cribl Guard is stronger where telemetry is the workload
Cribl Guard is built for scanning and redacting sensitive data from logs and telemetry data.
Our in-house transformer-based models are trained specifically for semi-structured machine data. They are designed to read local context, handle machine-generated formats, and identify sensitive values in the records security and observability teams work with every day.
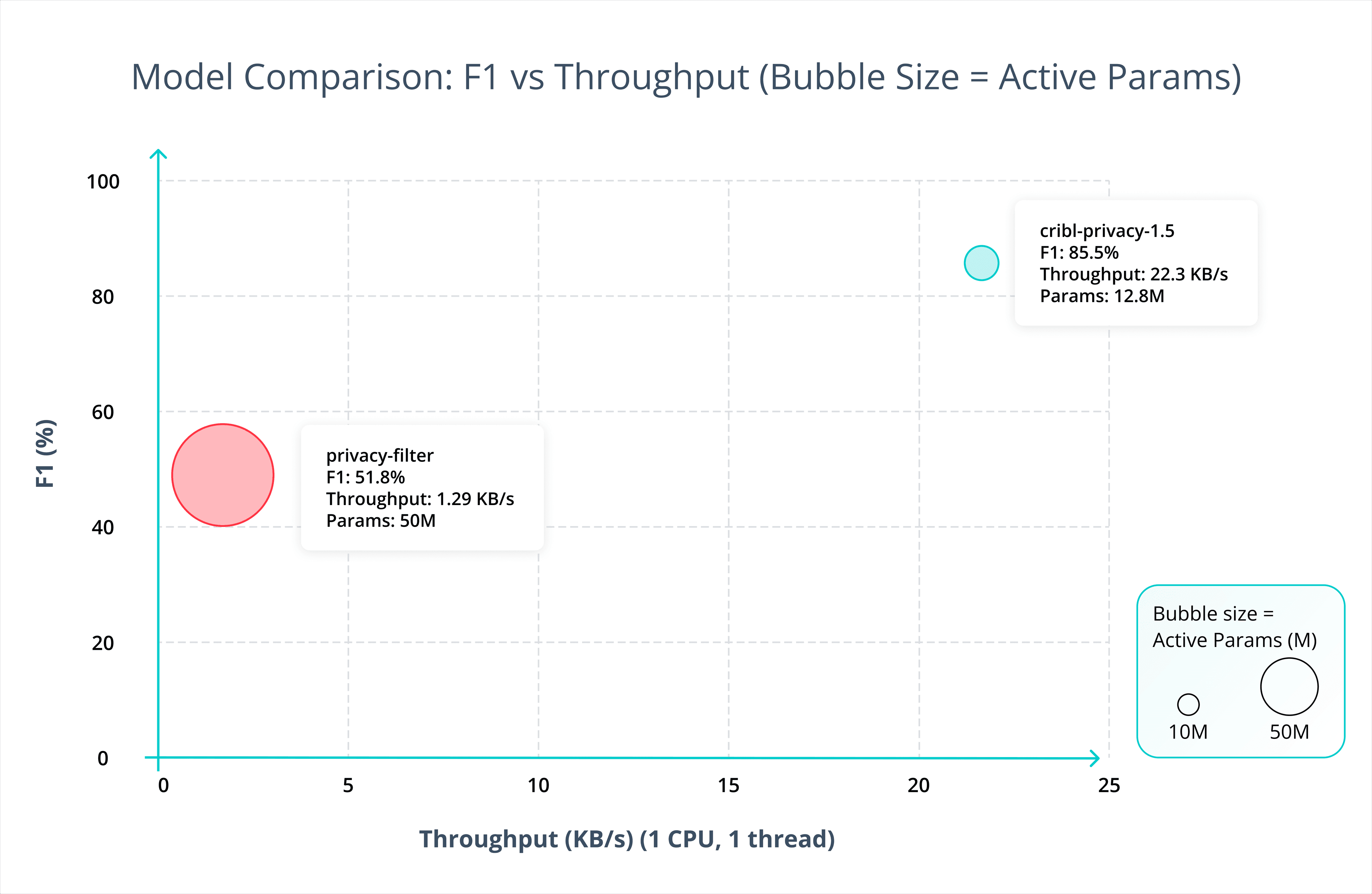
That specialization shows up in the results, on real-world telemetry. In our internal testing, our models catch more sensitive data than off-the-shelf alternatives on log-focused benchmarks, including OpenAI’s released model.
The benefit is not only higher recall (the percentage of sensitive data successfully found). It also means fewer unnecessary hits in the places analysts depend on for investigations, debugging, and response, improving precision (the percentage of sensitive data that is actually relevant). False positives inside telemetry can strip away useful context, make operational data less usable, and increase alert fatigue.
OpenAI shipped a solid general-purpose privacy filter, but telemetry calls for something more specialized.
Built for throughput as well as accuracy
Production telemetry pipelines operate under high-throughput requirements.
A privacy model that performs well in an isolated evaluation but slows down a live stream creates a different operational problem. Teams need detection that is accurate enough to trust and efficient enough to keep up.
Cribl Guard was developed with that balance in mind. Our models were selected along an F1-throughput balance rather than by accuracy alone. The focus is deployment under real event volumes, sustained workloads, and CPU-conscious inference.
The result is a set of models that are strong on telemetry accuracy and practical to run in-stream. That becomes especially useful when AI prompts and responses are being ingested alongside the rest of the environment’s machine data. Privacy protection needs to run in the same flow without turning that flow into a bottleneck.
The right fit for the job
Cribl Guard is focused on protecting sensitive data in real-world telemetry.
For security and compliance teams bringing OpenAI activity into Stream, that distinction is important. They do not just need a model that performs well on general text. They need one that works on logs, metadata, prompts, responses, and machine-generated records moving through the same operational pipeline.
That is where our in-house models stand out: stronger detection on telemetry, fewer false positives in operational data, and the throughput needed to keep privacy controls aligned with production scale.







