

Part 3 of 3: The honest architecture, and who actually owns what
If you've read the first two posts in this series, you already know the problem.
AI fails in telemetry not because the models are bad, but because the access layer is broken. Fragmented data, stale signals, agents integrating directly with a dozen systems and producing slightly different views of reality.
We covered why restriction-based controls don't fix it. And you know why the architecture decision most organizations haven't made yet is the one that will matter most when something goes wrong.
This post is where we get specific on where Cribl fits into all of this.
Most vendor architecture posts follow the same arc: problem, product, solved, call sales.
This post isn't that.
The honest version of any architecture post covers what the vendor does and what it doesn't. This one covers what Cribl does, what it doesn't, and who fills the gaps
If you're building agentic operations, whether that's AI-driven incident response, automated threat hunting, or autonomous observability, you need to consider the full picture of your environment.
Where Cribl Stream fits and why it's foundational for AI
Cribl Stream is the collection, transformation, routing, and governance layer for telemetry across your environment. It handles data from any source to any destination, normalizes schemas, filters noise, enriches with environmental context, and redacts sensitive fields in-flight, before data ever reaches a destination system.
It does all of this vendor-agnostically. It doesn't care what SIEM you're running, what observability platform you're on, or what your cloud provider is. It sits in front of all of it and makes the data better before it lands.
The governance layer is also built into the flow, not bolted on afterward. What gets retained, what gets masked, what gets routed where and at what fidelity, all of that is enforced in the pipeline, not as a downstream afterthought. (Plus, you can even do this directly at the source with Cribl Edge, our highly scalable vendor-agnostic agent).
For AI, this matters because clean, normalized, governed data going into your systems means cleaner, more reliable data coming out when agents go to query it.
The gap Stream wasn't designed to close
Stream gets your data to the platforms that already have AI built in. CrowdStrike, XSIAM, Google SecOps, Datadog, Dynatrace, Elastic, each has its own native AI and detection engine optimized for its own data, and Stream feeds them the clean, normalized telemetry those engines depend on. Within each platform, that works well. Stream makes it work better.
The limitation isn't the platform AI. It's what happens when an agent needs to reason across all of them at once. Pulling context from your SIEM, your object storage, your observability platform, and your data lake in a single investigation, each with different APIs, different schemas, different auth models, and different levels of completeness, without a layer that unifies all of that, the agent has to integrate with each system individually and hope nothing was stale or missing.
That cross-system access layer is what Stream was never designed to provide. Stream solves the pipeline problem by moving and shaping data. Once that data lands in its destination, Stream's job is done.
The problem of reasoning across all of those destinations simultaneously is what Cribl Search closes.
How is Cribl different?
Every other vendor in this space starts with the same asks: send us all your data, transform it to our schema and land it on our platform. Once you've done all of that, then we'll give you something useful.
Once you have done all of that… Only then we'll give you interesting outcomes.
The implicit cost of that model is enormous. You're paying to move data. You're paying to normalize it upfront, whether you ever actually query it or not. And you're locked into one vendor's format before you've even asked a question.
Cribl Search is built on a different premise. You shouldn't have to centralize all your data to get value from it.
It's not another SIEM. It's not another observability platform. It's not asking you to reformat anything before the query runs. It does this through two distinct engines that work together as one unified surface.
The indexed tier (Lakehouse Engine)
For data you know you'll query repeatedly, Search can index it directly, receiving it from Stream or any other source. It automatically detects and assigns data types on ingestion, so you're not spending time formatting or preparing data before you can use it. You get a high performance query layer without the manual overhead of getting data ready for it.
The federated tier (Federated Engine)
Data stays exactly where it lives. Queries travel to the data, not the other way around. No rehydration tax. No pipeline delay. No "we need to ingest this first" blocking an active investigation. Schema normalization happens at query time across OCSF, OTLP, ECS, and custom formats, so you're not paying a preprocessing cost on data you may never actually use
The two engines aren't separate products. They're one unified query surface. You query once. Search figures out whether to hit the index or federate out to where the data lives. The analyst or the AI agent DOESN’T need to know or care which path it took.
In practice that means two things:
First, a single integration point for every data source in your environment. Any third-party agent connects directly to Cribl's data engine through governed, policy-enforced access layers. The agent queries once and gets back structured, scoped results across every source. That's what makes Search an agentic architecture primitive and not just a search product.
Second, a fused investigation surface. Machine logs, metrics, and traces combined with human context from Jira tickets, ServiceNow incidents, Git commits, and Slack threads. The agent doesn't have to jump between systems. The surface is unified regardless of which engine served the data.
Every other vendor's pitch starts with "send us your data." Cribl's pitch starts with "keep your data wherever you want to keep it”.
That's not a feature distinction. It's a fundamentally different architectural bet on where the industry is going.
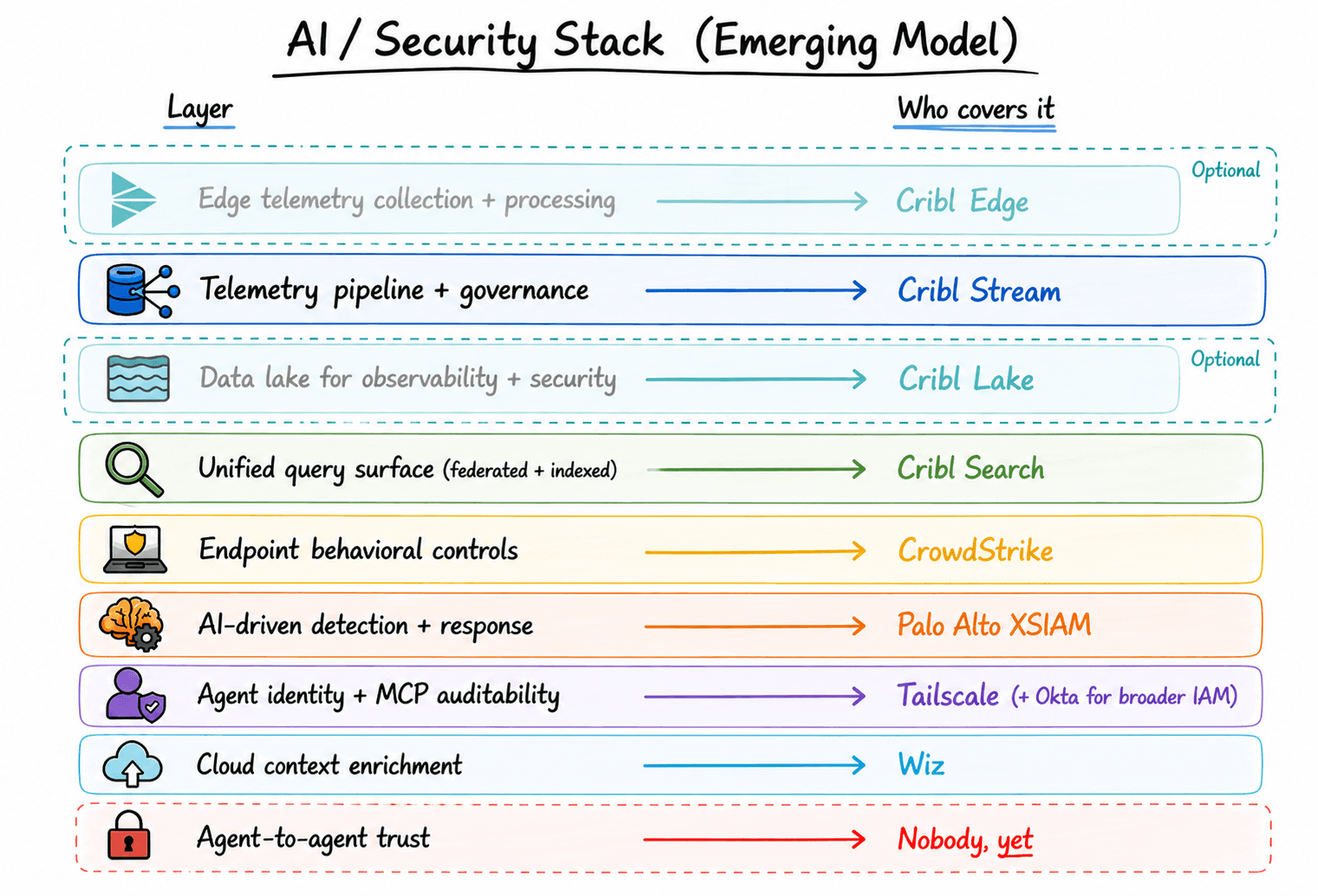
How this comes together
Stream - collects, transforms, routes, and governs telemetry across every source and destination
Optional: Edge extends that processing directly to the source when you need it
Search - provides the unified query surface, federated or indexed, so agents can reach all of it without per-system integrations
Endpoint controls govern what agents can actually do with what they find. This is where the partner ecosystem plugs in (we’ll get to that shortly)
Bonus: Lake - provides a cost-effective storage option for the agents to search archived data
Each layer has a job. None of them try to do the others' job.
Where the gaps are, and who fills them
Here's where most vendor posts stop. We're not stopping here.
According to Akto's 2025 State of Agentic AI Security & Gravitee State of AI Agent Security 2026 reports, only 21% of enterprises have full visibility into agent actions, tool invocations, and data access. Most are running autonomous systems they can't actually see, with no consistent credential governance and no audit trail for what those agents are doing or why
Now that we know the gaps, who can fill them?
As a vendor-agnostic platform, you can use the tool of your choice but we most commonly see:
CrowdStrike
Covers endpoint identity and behavioral controls: what agents are authorized to do at the execution layer. Cribl routes the telemetry; CrowdStrike governs the action. Clean handoff, minimal overlap.
Palo Alto Networks (Cortex XSIAM)
The AI-driven SOC automation layer. XSIAM applies detection and response logic on top of your telemetry, and the quality of that logic is only as good as the data underneath it. Cribl Stream handles the normalization and governance before data ever reaches XSIAM, so it's working from a clean, consistent foundation. If you're running XSIAM without that, you're running expensive AI on noisy inputs
Tailscale + Okta
Handles identity-linked policy controls and auditability for AI agents operating over MCP connections, directly addressing who called what, with what data, and when. It's the closest thing the industry currently has to a practical answer to the agent identity problem. Not complete, but a meaningful step.
Wiz
Connects cloud posture to operational data so agents aren't reasoning about security signals in isolation from the environment they live in. Cribl routes Wiz's prioritized cloud security alerts with full telemetry context, so agents and analysts get the signal and the environment in the same surface.
These are just some of the vendors we see most frequently but have countless integrations so you can choose the best fit control tools for your environment.
How the different pieces fit together
The gap nobody has solved yet
When one agent's output becomes another agent's input, and that output has been poisoned, hallucinated, or simply wrong, the downstream agent doesn't know. It treats that output with the same confidence it would give a clean, verified source.
Cascading failures in multi-agent pipelines propagate faster than human response times. By the time someone notices, the chain of confidently wrong decisions is already four steps deep.
Sandboxing doesn't catch this. Endpoint controls don't catch this. Identity controls don't catch this, because every agent in the chain was legitimately authorized.
The only real mitigation is ensuring every agent queries from the same consistent, governed retrieval layer, so all agents are working from the same version of reality and a poisoned signal can't get laundered through the system as if it were clean. That's what Cribl Search is built to provide.
But agent-to-agent trust is bigger than any single product, and the industry hasn't fully confronted it yet. The organizations that will be ready when it becomes a problem are the ones building the architecture intentionally now: Stream for the pipeline, Search for AI access, and the right partners closing the identity and governance gaps.
Not bolted together after an incident. Built before one.
This is the final post in a three-part series on AI access failures in security and observability. If you haven’t read them already, start with Part 1: AI doesn't fail because it's not smart enough and then read Part 2: Telemetry is the hardest case of the AI data access problem.





