

An oft-forgotten component of robust, production-ready code is testing. The moat protects us from costly service interruptions and fortifies trust in our product with our customers. Simply put, it’s in the critical path of damn good software. However, as we scale a cloud product to serve a rapidly growing user base, our test case scenarios scale correspondingly. As far as testing goes, end-to-end (E2E) testing most closely mirrors the end-user experience. As developers, we aim to emulate product navigation and user flows in sync with any feature’s typical user experience. But this flow can, over time, become cumbersome and slow, particularly in a non-parallel testing environment. In the case of Cribl.Cloud, we encountered the scaling limitations of our Codecept testing platform, witnessing excruciatingly long test execution times and flakey failures. With the transition to Playwright as our E2E testing platform, we not only streamlined our tests for a better development experience but also achieved significant performance gains, reducing our execution time by nearly 85% compared to our previous E2E framework thanks to test parallelization.
What’s the Problem?
To understand why Cribl Cloud needed a new testing platform, we should first take a look at our previous solution and understand some of the reasons why an organization would want to invest in replacing a working (albeit cumbersome) testing platform, Codecept.
1.) Slow Testing Platform
Codecept has advantages that make sense for an engineering organization early in the development life: an abstraction layer that wraps Playwright drivers which makes tests easy to write without needing to implement cumbersome helper functions, readability, making testing writing simpler than many other test platforms, and a strong community for support which is important when developing using 3rd party libraries. Simply put, tests can be written quickly. Choosing Codecept may have been the right decision at the time.
However, as Cribl Cloud matured, these advantages turned into disadvantages largely due to bloated drivers and abstractions in Codecept not needed in our configuration, leading to longer test execution times—a particularly painful occurrence in a CI/CD pipeline where minutes can be crucial for deploying code in critical scenarios like incident response and management. Over seven quarters, as testing scenarios scaled, runtimes increased from around 10 minutes to 50 minutes for a single deployment of end-to-end tests! Couple that with a nearly 50% flaky failure rate and a recently tripled team, and you can start to frame the investment need for a viable alternative to deploy efficiently.
2.) No Shared State Due to Parallelization
Who loves flakey tests and smashing the re-run CI/CD button into oblivion to get a PR over the line? It’s universally understood that developers must accept a threshold of failures that are inherent to any testing platform. However, in the case of our Codecept implementation, we experienced a rate of failures much higher than this threshold and a root cause analysis pointed to the issue:
A single-threaded test runner using a single set of user credentials for a single organization across multiple test execution runs created an inconsistent, non-atomic, and non-idempotent testing environment.
This is quite possibly the most cardinal sin one can commit in testing: tests might influence one another due to shared states or leftover data, causing subsequent tests to not start from a clean slate. This can affect the ability of each test to operate independently without side effects.
How does someone who needs to get a pull request merged bypass this? Just keep smashing the re-run button; eventually, your pull request wins, and you get to merge. However, behind you is a trail of destruction from failed tests of other merge candidates, forcing a long queue for pull requests hoping to be next in line to merge. Repeat this enough times with a bias towards delivering code quickly, and trust in testing erodes, tests are skipped, and quality is compromised.
Remember earlier how we mentioned end-to-end tests sometimes took nearly 50 minutes? We compound this problem as we scale. This was a massive scalability problem. This was an inefficiency problem. This was a costly problem.
3.) Improved Login Experience
You might be wondering why a single set of credentials was used across all tests amongst multiple test runs. Because creating a logged-in user experience in a web application is actually quite complex to implement. In Codecept, leveraging before () hooks ensured that logged-in states were maintained. However, as you scale this solution to more than just a half dozen tests, you start to run into some serious baggage and friction when trying to execute tests due to time overhead. We needed a way to have the testing user login experience be abstracted from the tests and baked into the testing platform itself, not only for testing efficiency but also for creating an easy testing environment for newly onboarded engineers in a quickly scaling team.
Be Careful of False Prophets, Unless It’s Playwright
Admittedly, when we ventured to identify and solve this ambiguous set of problems, we did not know how much better the successor would be, or if it would be a success at all. When deciding between different platforms, there wasn’t a consensus—except for the understanding that our current solution with Codecept needed replacement. Candidates like Selenium and Cypress were considered, but in early runtime benchmarking of testing platforms, one candidate stood out: Playwright by Microsoft.
Why Playwright? Well, it just makes sense. By using Codecept, we were already utilizing an abstracted and heavier version of Playwright, so logically, we knew it couldn’t be slower than our current solution. Coupling that information with the parallelization properties of Playwright and the aforementioned performance benchmarks, and we had a strong candidate. We decided to take an educated gamble on Playwright as our successor to Codecept.
So, how did we achieve this? Well, we knew that we needed to migrate our existing tests onto the new platform without losing coverage and set out to achieve this by devising a plan to phase transition: install and set up Playwright, migrate and refactor any missing helpers/functions to execute tests, test and benchmark our tests in CI/CD, staging, and production environment. After this transition, we deprecated and removed codecept and all pipelines associated with it.
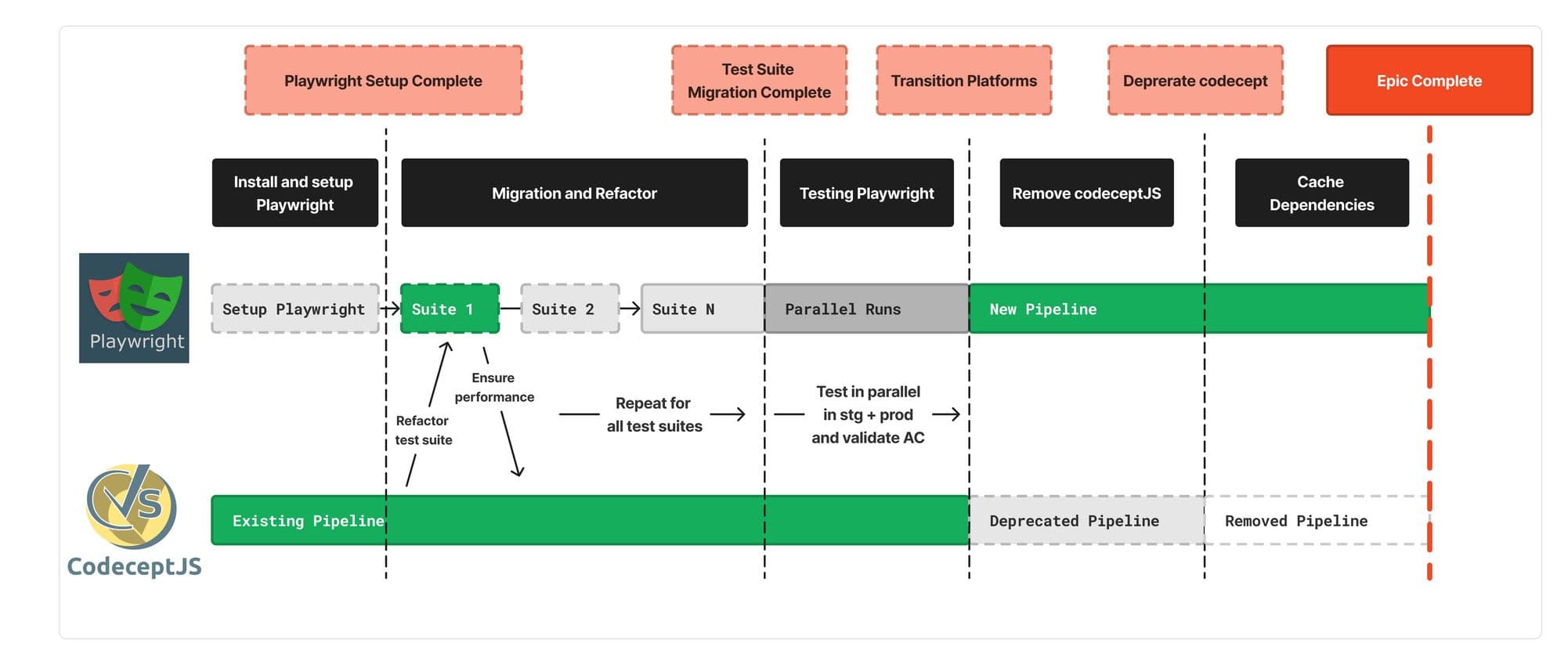
Okay So You Have the “Successor” – Get to the Good Part
In a perfect world, engineering challenges are implemented with no friction and are able to be delivered to all stakeholders on a silver platter. However, in the stochastic and unpredictable real world unforeseen challenges can rear their heads at many different points of the project lifecycle. The range of challenges we faced included package management issues, compute cost issues, and resource sanitation (another cost issue), amongst others.
Addressing the Slow Testing Platform through Parallelization
We significantly enhanced our testing process by transitioning to Playwright and harnessing its parallelization capabilities. Playwright’s fixtures and built-in support for parallel test execution allowed us to run multiple tests concurrently without a shared state, greatly reducing the overhead and bottlenecks associated with serial test execution. The adoption of parallel testing effectively addressed the scalability and efficiency issues that had challenged our previous framework, allowing us to scale our testing operations.
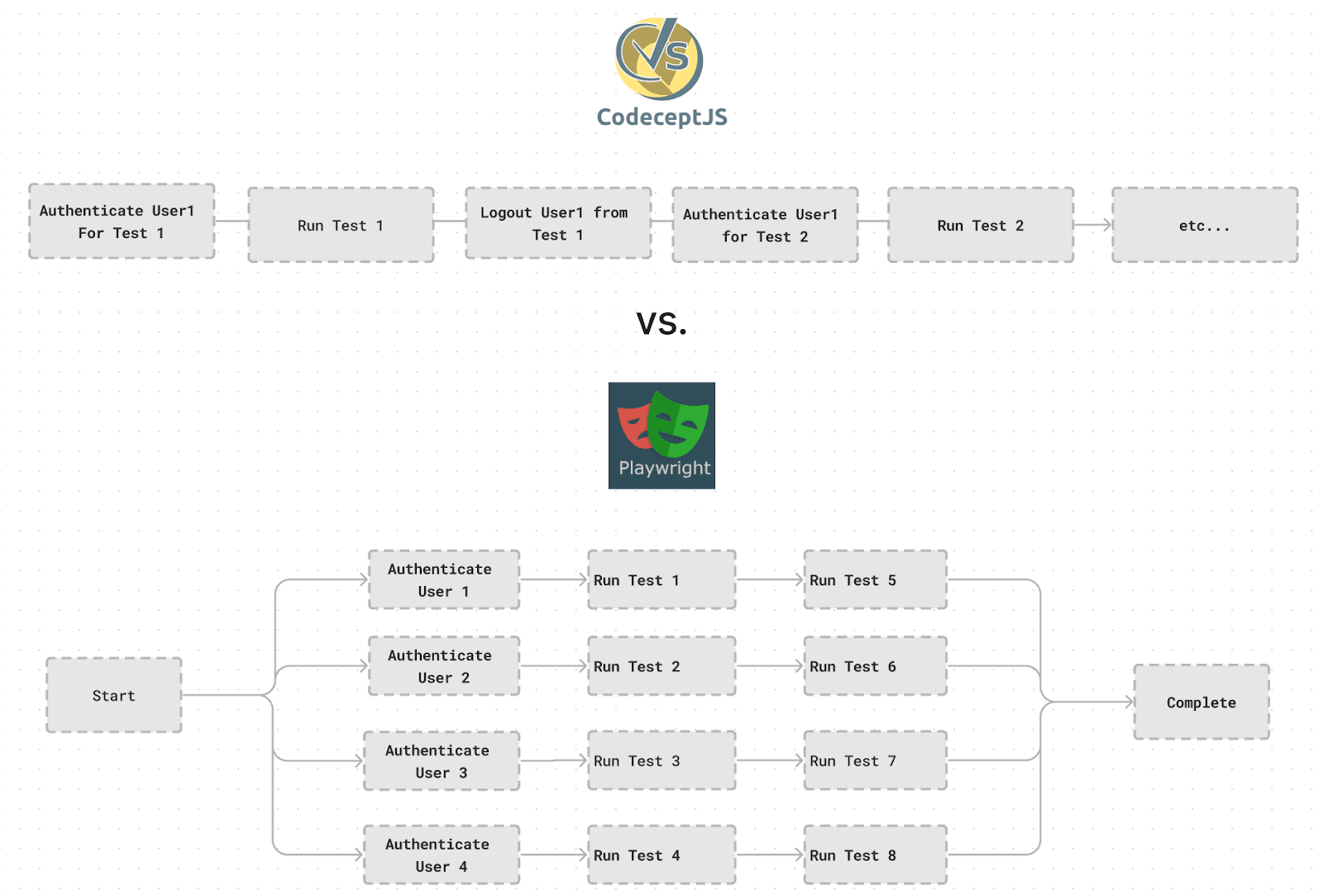
Enhancing Test Reliability Through Parallelization
Playwright’s adoption marked a shift to a parallelized testing approach, enabling multiple tests to run concurrently without sharing state due to ephemeral organizations dedicated to each test runner. This change effectively eliminated the flakiness and inconsistencies previously experienced due to shared state, ensuring that each test could operate independently and reliably. Playwright’s robust parallelization capabilities greatly enhanced the efficiency and reliability of our testing process, supporting our rapidly scaling needs.
Streamlining the Login Experience with Integrated Fixtures
Playwright’s fixtures provided an innovative solution, allowing us to abstract and automate the login process across tests. This setup ensured that each test started with a clean state, with ephemeral users automatically authenticated and initialized at the beginning of each test. This approach not only simplified the testing process but also reduced the setup time for each test, making the testing environment more conducive to rapid development and easier for new engineers to integrate into the team. This includes creating ephemeral users and initializing them to a standard landing page, drastically reducing the setup complexity and time previously encountered with Codecept.
…However Perfect Parallelization Doesn’t Exist
Going back to this perfect world where we have unlimited resources and compute to execute what we want without any consequences all things can run perfectly in parallel. We run our tests suites as fast as our slowest test. We naively tried to do this, and we found that we took the 50-minute runtime mentioned earlier to as low as 2 minutes! However what worked locally turned out to be costly as we used ephemeral organizations that, if not cleaned properly, incurred significant AWS cloud compute costs both operationally and financially. We definitely FAFO’d…
Testing with AWS Organizations Can Cost A Lot Operationally
Because we are a cloud team that used real users that are assigned real AWS organizations in staging and production environments, we saw a problem that didn’t see when running tests locally against LocalStack.
1.) Organizations are free in LocalStack, as it’s an AWS emulator. When running in staging and production environments it costs money, like real money.
When developing against local, we had a lot of fun with how many orgs we wanted to run in parallel by adjusting the Playwright config file. Initially we tried running every test at once, which took us to that 2 minute runtime number. However, we found a constraint very early on: our test run times were quicker than the terraform provisioning lifecycle for our organizations. Why does this matter? When your organization’s provision lifecycle is roughly 10 minutes, and you are running tests that take 50 minutes, you don’t have a risk of needing organizations faster than they can be provisioned. Take that number to under 5 minutes, and you will start to see how this can become an issue.
2.) Using more AWS organizations to test than are available can create issues with availability for actual users trying to sign up and provision an org in staging and production environments
Since we were deploying and destroying so many orgs at once, we started to see that users couldn’t use pre provisioned organizations and this created availability issues for our platform. We ran into our first resourcing issue, and we had to protect our resources by implementing checks to prevent our available organizations from depleting beyond critical levels to maintain our availability.
Failing to Cleanup AWS Organizations Can Cost A Lot Financially
After deploying Playwright in staging and production, we noticed a troubling trend: our daily AWS cloud spend was escalating each day. A quick investigation revealed that over 750 AWS cloud organizations had been spun up in the last 48 hours in staging and production. Normally, such rapid growth would be cause for celebration, perhaps suggesting significant expansion. However, we discovered that these organizations were associated with the Cribl test automation user. After shutting down the tests, a root cause analysis revealed that in the CI environment, Ubuntu Bitbucket runners’ child cleanup processes, spawned by the Playwright parent process could not read the organizations provisioned by the parent on the data volume in memory we were storing that information on. Playwright deploy and cleanup was triggered by parent process, and the runners were forked child processes. As a consequence, the teardown process (a parent process) lacked the necessary context for making cleanup API calls to tear down AWS Organizations since these were written to isolated memory by the child process, and all attempted cleanups failed— for 3 days. This issue was eventually resolved by writing organizations and users to an external temporary volume on the runner. This allowed the parent processes to perform cleanup independently of the subprocess spawn hierarchy on CI, saving the day—and a significant amount of money.
The Happy Parallelization Medium
What we discovered was that perfect parallelization unfortunately doesn’t exist. Mathematically, there’s an asymptotic upper limit to performance with parallelization, and the optimum balance between performance and resource cost lies somewhere between both extremes. By using only three to four test runners in parallel, we achieved an 85 percent performance boost, reducing our test times from 50 minutes to under 5 minutes. The diminishing returns relative to the operational costs proved to be a satisfactory trade-off for our use case.
In Closing
The transition to Playwright at Cribl.Cloud marked a significant evolution in our approach to software testing, dramatically enhancing our processes’ efficiency and reliability. By implementing Playwright’s parallelization capabilities and integrated fixtures, we mitigated the scalability and efficiency challenges posed by our previous framework and revolutionized how we manage and execute tests. This strategic upgrade reduced our test execution times from 50 minutes to as low as 2 minutes, underscoring our ability to adapt and innovate rapidly.
However, this transition also brought to light new challenges, particularly in the management and financial implications of using AWS Organizations extensively for testing. The issues of resource depletion and high operational costs were significant but were addressed through innovative solutions like external volume storage for cleanup processes, ensuring the sustainability and cost-effectiveness of our testing environment.
As we refine our testing strategies and infrastructure, the lessons learned from deploying Playwright reinforce the importance of continuous evaluation and adaptation in technology choices. They also highlight our commitment to maintaining a robust, efficient, and economically feasible testing framework that supports our growth and the reliability of our products.




