

Source-side queueing is a fancy way of saying: You can configure Cribl products to make sure data isn’t lost in the event of downstream backpressure, again. Those familiar with Cribl Stream might be aware of destination queuing or persistent queuing, wherein Stream can write data to the local disk in the event of an issue reaching the destination. Maybe your SIEM is suffering from disk I/O latency. Maybe there is a DNS problem with your load balancer (Hint: It’s always DNS). Maybe the destination actually went down due to a zombie apocalypse. Whatever the reason, Stream (with persistent queuing configured) would sense the destination’s having an issue, and would start writing data to disk as Stream waited for the destination to come back online.
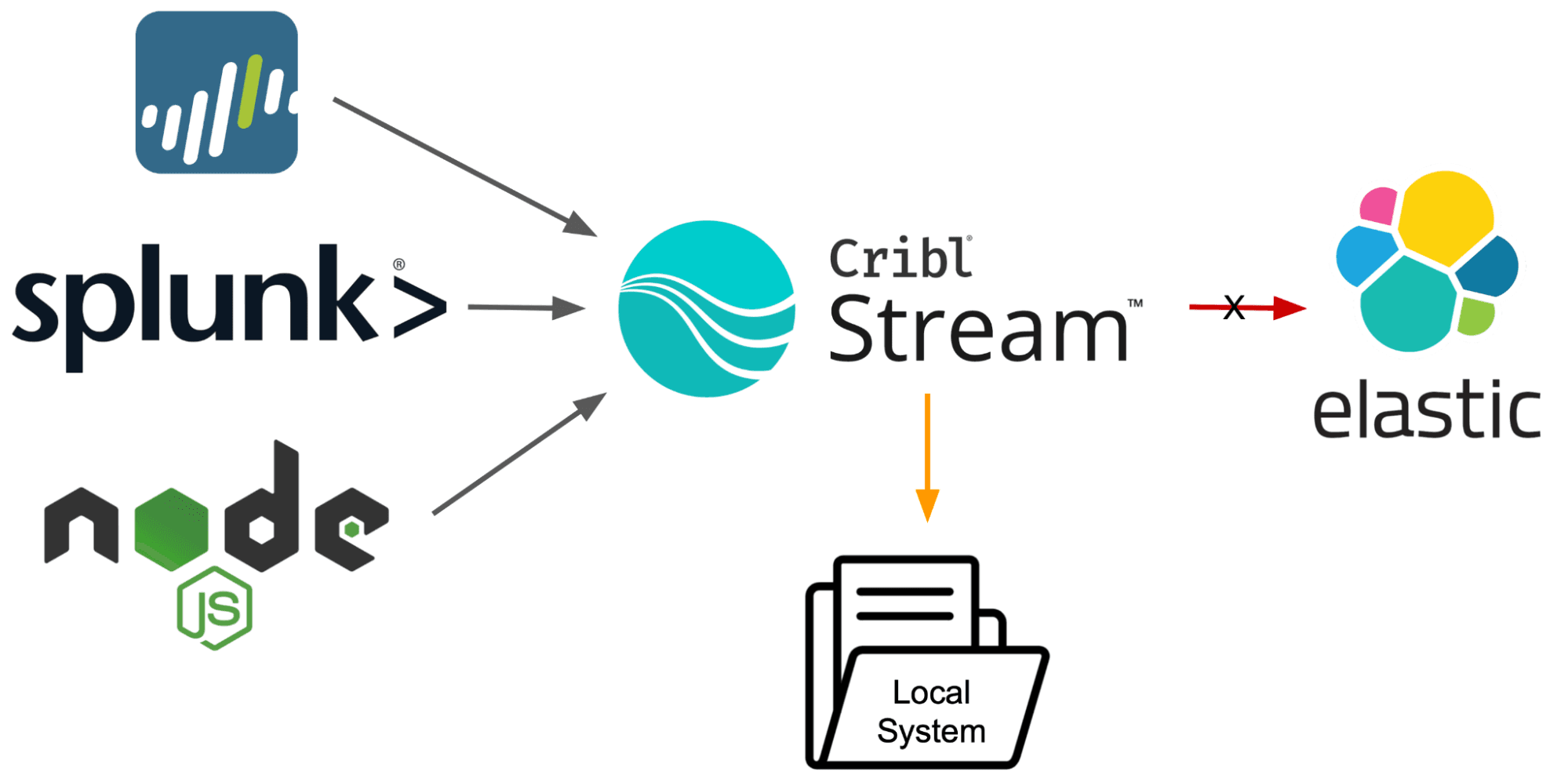
Destination queueing could fill up quickly if myriad sources are configured. To solve this, sources are usually alerted to backpressure and asked to simmer down for a sec while Stream waits for the destination to catch its breath. Unfortunately, alerting sources to backpressure only works when they are TCP sources. UDP sources just yeet their data at Stream and don’t care what happens afterward. We can’t tell a UDP source that we need some data again, what with UDP being connectionless and all. What we need, then, is a way to backpressure sources when we can (on TCP) and to queue data from sources that don’t return our calls (on UDP).
This is where source-side queuing comes in as a new Stream feature that adds to our existing queuing capabilities. Instead of a singular destination queueing option, now administrators can configure Stream to queue in a source as well. Let’s look at how to configure a source-side queue.
Before we continue, a word of warning: All queuing in Stream is written to the local disk, meaning that if disk space runs out, data will be dropped.
We Must Protect This Source!
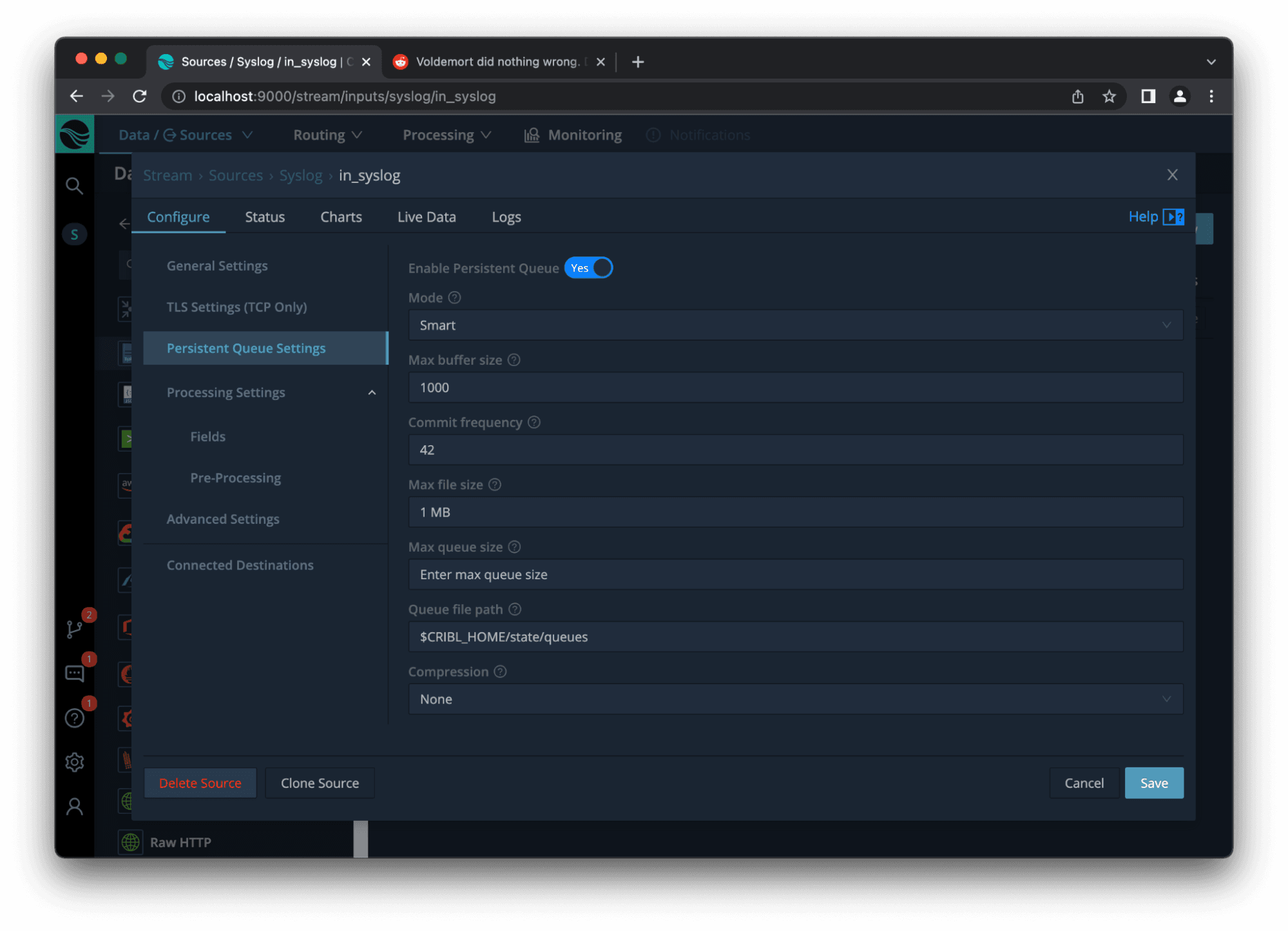
Now that we’ve dispensed with the small talk, let’s look at the actual UX for source-side queuing in Stream.
First off, we’ve set the Mode to Smart. This means that Stream uses heuristics to determine when the destinations associated with this source are actually down, meaning that we need to stop writing to memory and start writing to disk (read: queuing). The other option on this drop-down is Always On, meaning that all events are buffered to disk – but remember the warning earlier about filling up the disk, and use this at your own risk.
Next to cover are two new settings added for source-side queuing: Max buffer size and Commit frequency. (These, and other settings in the screenshot above, are covered in the docs page linked earlier.)
Max buffer size refers to how many events Stream will hold in memory for this source, before they start spilling over to disk (due to destination backpressure).
Commit frequency refers to how often Stream creates checkpoints (or markers to remember where it was) when reading from queue files. By default, this is set to 42 events, meaning that Stream puts a bookmark in the queue file every time it flushes 42 events. If Stream were to go down for some reason while emptying the queue, it could then go back and start at the last bookmark / checkpoint. Note: Decreasing the frequency will improve performance (since we aren’t writing checkpoints as often), yet it increases the possibility of duplicate events downstream in the event of a downed Stream.
So, yeah – the Cribl suite now includes source-side queuing for all your data integrity needs. If anyone asks, “You down with UDP?” you can now sleep soundly, knowing that you can reply, “Yeah! You know me!”
The fastest way to get started with Cribl Stream and Cribl Edge is to try the Free Cloud Sandboxes.






