

Aggregation is really powerful with Cribl Stream. It allows you to aggregate the events flowing through Cribl Stream into a small number of aggregate events that allow you to get actionable insight.
This might be to sum the number of bytes of traffic between a source and destination for a firewall dataset or calculate the number of actions or time that a trace took. These might also be turned into metrics for consumption in a tool like Grafana, the limits are endless.
The native aggregation function within Cribl Stream is easy to use and helps with many of the use cases we all want to solve. It works by performing the aggregations at the worker process level within the worker. This can result in several metrics or events being created for the same aggregate dimensions for a given time span. If you want to aggregate many dimensions and/or a long aggregation window, you may drive up your workers' memory usage.
This blog is going to demonstrate an extension of the native aggregation function using another Cribl Stream function, “Redis,” so that you can aggregate across longer timeframes and more dimensions and ultimately end up with a single metric or log event for the aggregation window per set of dimensions.
As you can appreciate, this approach adds some complexity and requires an appropriately sized Redis environment.
Introduction
The approach we cover in this blog will use the native aggregation functionality with small aggregation windows to create regular aggregations, we will then create or update entries in Redis to roll these short aggregations into longer time windows.
If our overall aggregation window has passed, we will close out our event in Redis and flush it to our destination, allowing a new aggregation window to start. We might also have events that happen once and never again with the same set of dimensions, for example a trace, or combinations that occur very infrequently, given the event driven nature of Cribl Stream these might result in orphaned aggregations in Redis, don’t worry we have this covered too.
Using Redis as a central location to share our aggregated values allows us to reduce the number of events significantly while still achieving the insight we need from the data.
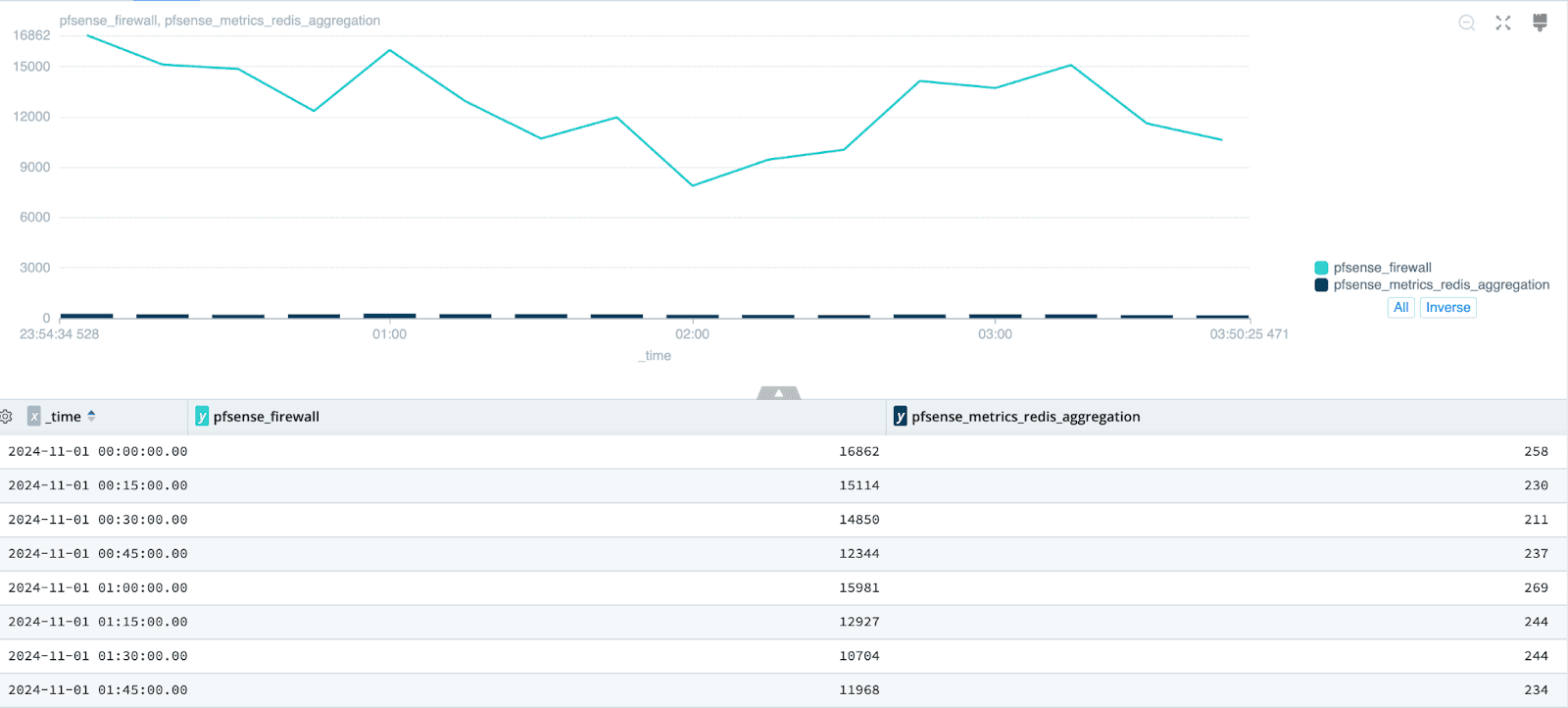
Reducing these firewall events to aggregates gives us a massive volume saving without us losing the ability to get the value we need. If we look across a whole dataset we are reducing the number of events by orders of magnitude as you can see above.

If we drill into a specific set of dimensions captured using this technique, we’ve reduced the number of events captured from 137 to just 4,1 for each hour in this example dataset. We still know key information and how many times it occurred, we have just removed some fidelity to reduce the number of datapoints to something more manageable.
This solution is not just for observability, though. If we applied it to a voluminous dataset like VPC flow logs or WAF events, then you could get your key indicators into your system of analysis without worrying about your budget with these large datasets.
Also, if we have archived the full-fidelity copies, we can still replay the original events should we need to in the future.
The Redis Approach
The scenario that I am going to use is a firewall log source. We want to capture the number of events for a combination of dimensions, in this case src_ip, dest_ip, dest_port, action, and protocol. Our objective is a single event output for each one-hour time window to our destination.
As we are extending the capability of our pipeline, we do have some additional requirements:
A Redis database, I used Redis Cloud, but you may want to install this within your environments.
Destination: A Cribl Lake destination to store checkpoint data related to an aggregation window. You might choose to use another type of destination here..
Source: The same destination you have configured for point 2 will also need to be configured as a collector source that we can schedule.
Output Router to control which destination is used by our route
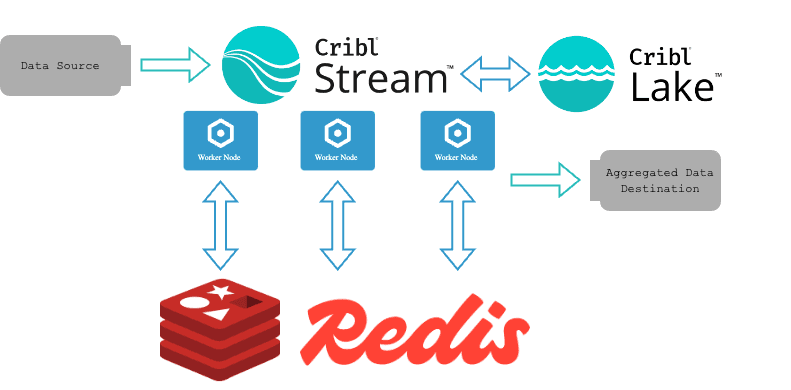
There will be three pieces of information we will be storing in Redis as a hash for this scenario:
key- This will be a string based on our dimensions to create a unique identifier.starttime- This will be thestarttimerecorded by our first aggregation for a given set of dimensions and will allow us to update or close out the Redis event as neededevent_count- This will be the metric that we are aggregating to hour-long aggregations in this example; we will create this at the start of a new aggregation window and then update it during the live cycle of the longer aggregation window.
The Pipelines showcased in this blog are available for review in the new and improved “Redis Knowledge Pack.”
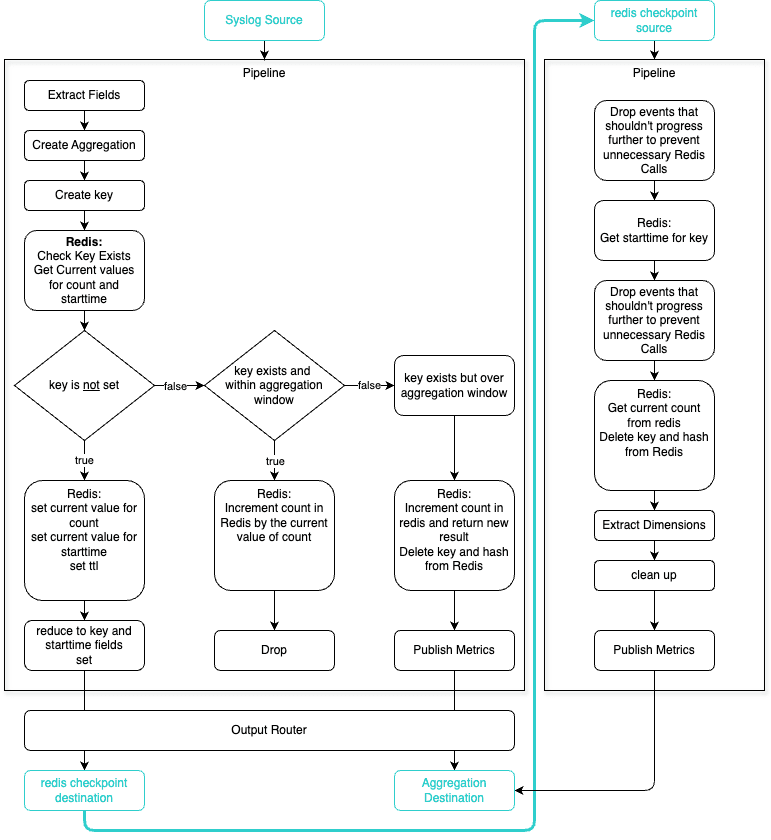
This technique is broken into two pipelines: our general Redis aggregation pipeline and our orphaned aggregates pipeline.
General Redis Aggregation pipeline
This pipeline will handle the data we want to aggregate.
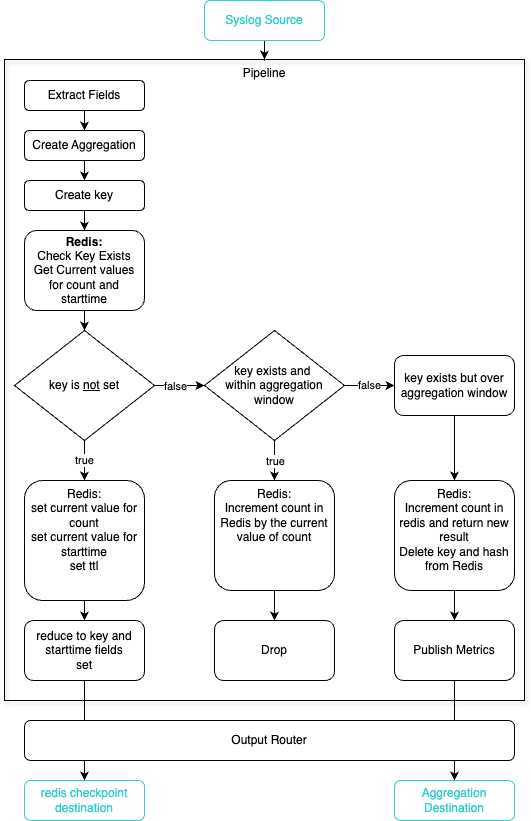
We have extracted any fields we are interested in from the original event and created our aggregation using a relatively small time window.
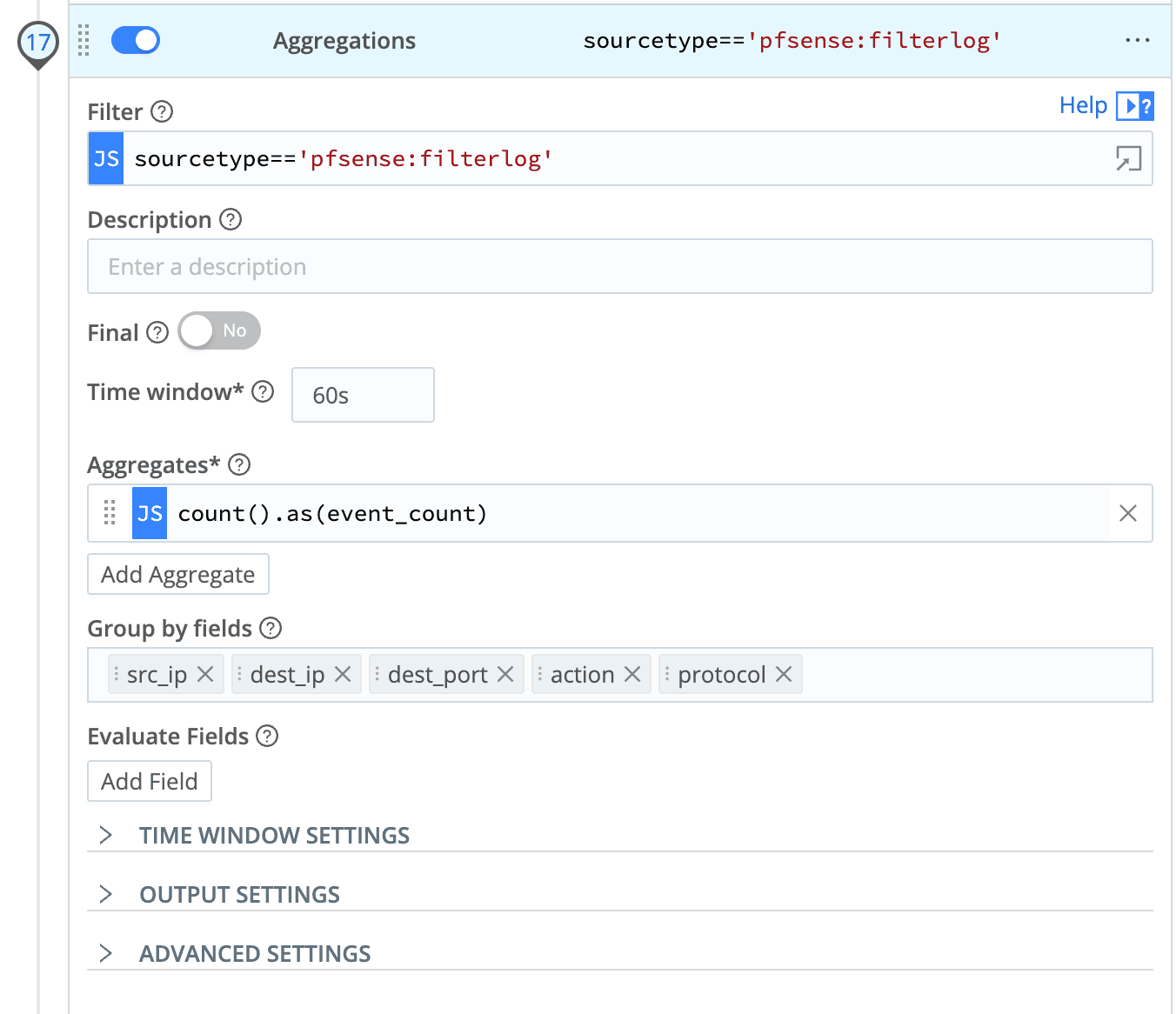
Now that we have our short time period aggregation, our next step is to create a single field for our primary key made up of our dimensions and check if it already exists in our Redis database.
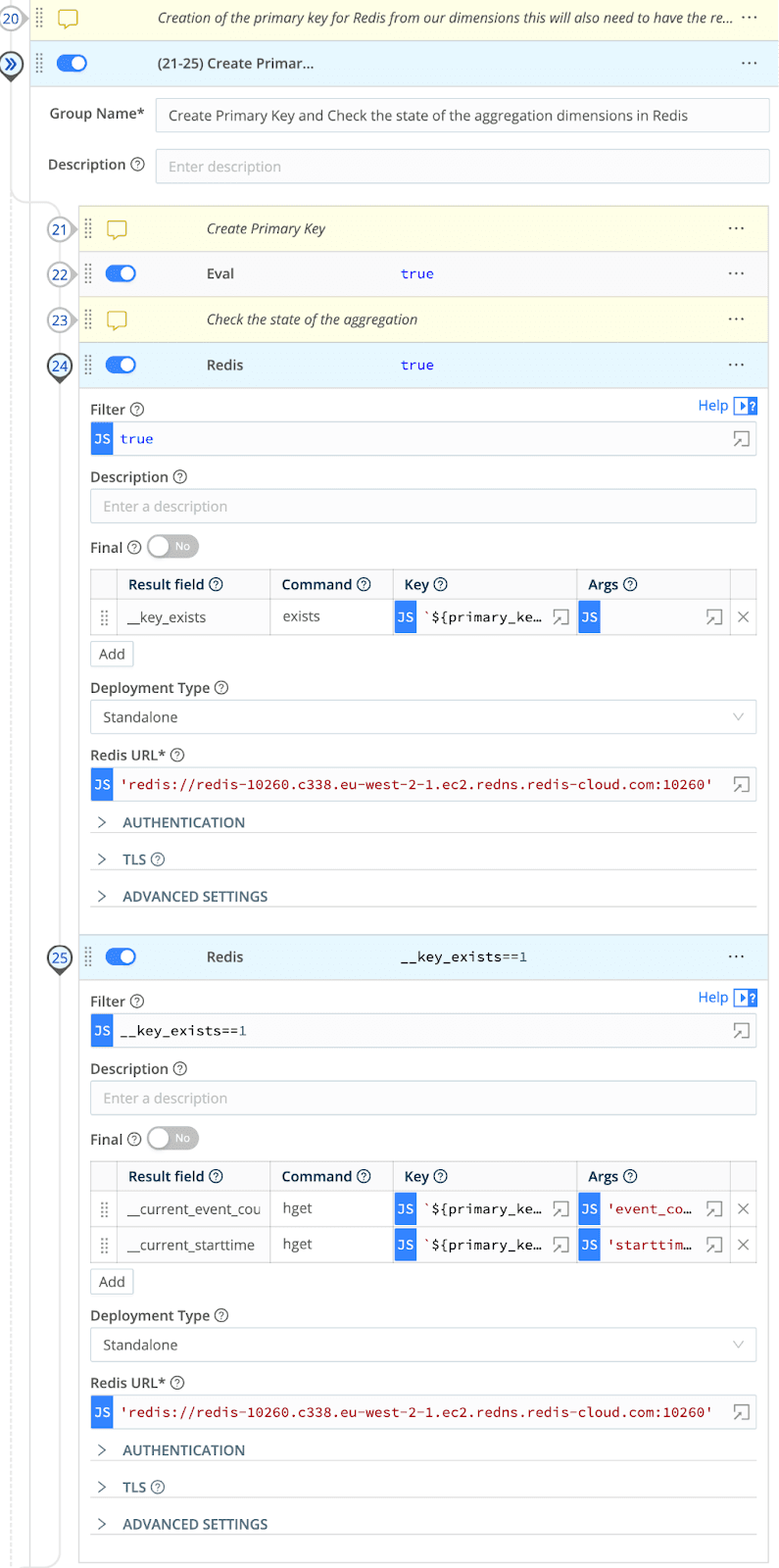
Now, the aggregate event we have created will take one of three paths
Path 1: The primary key does not exist in Redis
In this section of the pipeline, we simply create a new entry in Redis for that primary key and populate our metric and the starttime of the aggregation we created, which will be used to determine whether subsequent events use path two or path three. We also set an expiry so that events don’t linger in Redis forever as a good housekeeping activity.
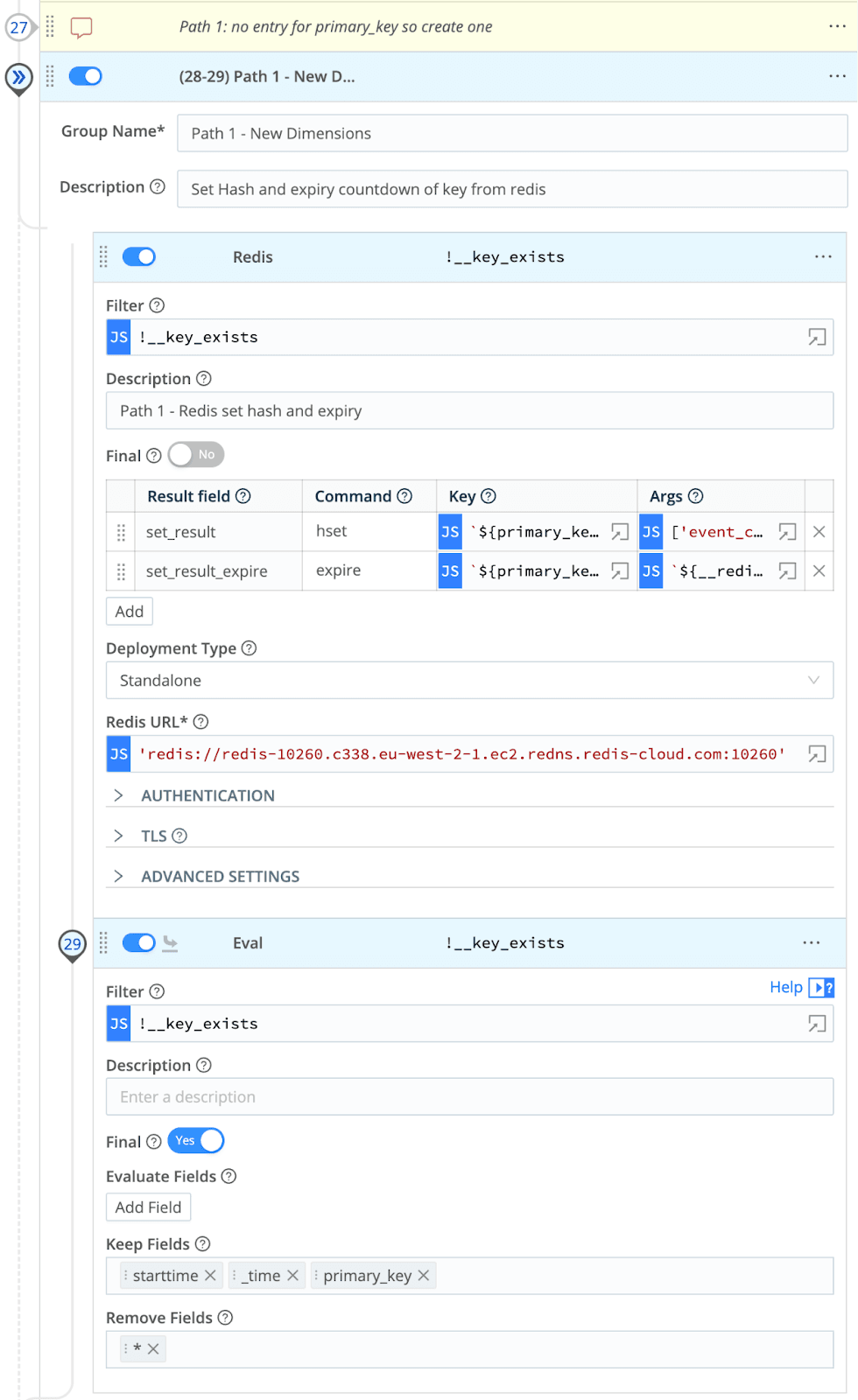
This event will now finalize where the output router will pop into our checkpoint destination, in this scenario, Cribl Lake, for use by our orphaned aggregations pipeline later.
Path 2: The Primary Key Does Exist in Redis, and We Are Currently Within the Aggregation Window for That Key
This section of the pipeline will increment the existing value we already have in Redis with our current aggregate event value and then drop the aggregate event, as we don’t have to pass it anywhere.
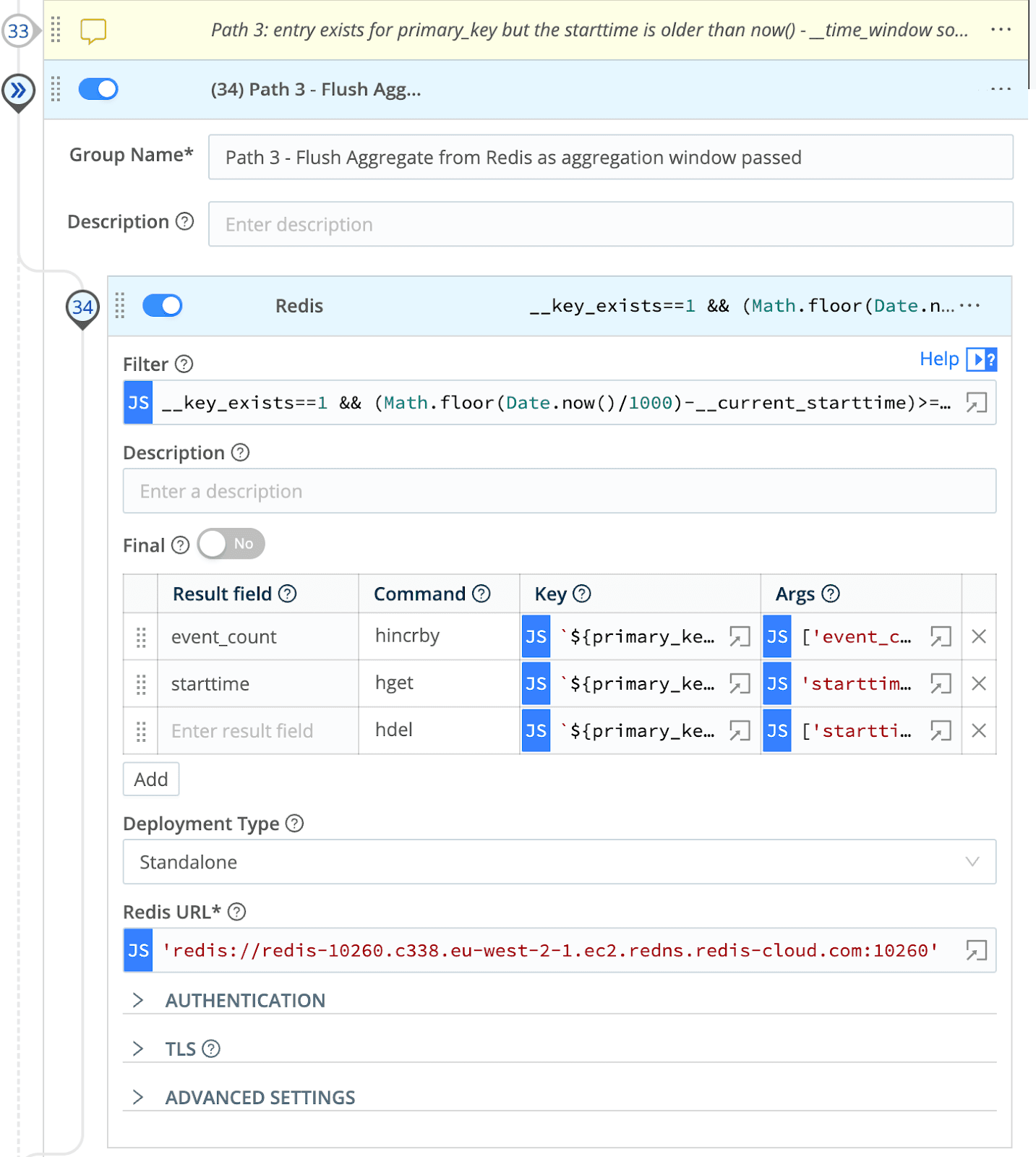
Path 3: The Primary Key Does Exist in Redis. However, We Are Over the Aggregation Window for That Key
Our final path is triggered when we are over our aggregation window, so we must collect the current state from Redis and flush it to our destination as a metric. In addition to getting the current state, we also deleted the key from Redis to allow a new aggregation window to commence elsewhere within the worker group.
To make this choose your own adventure pipeline easier to visualize this is a simple flow of what is happening.
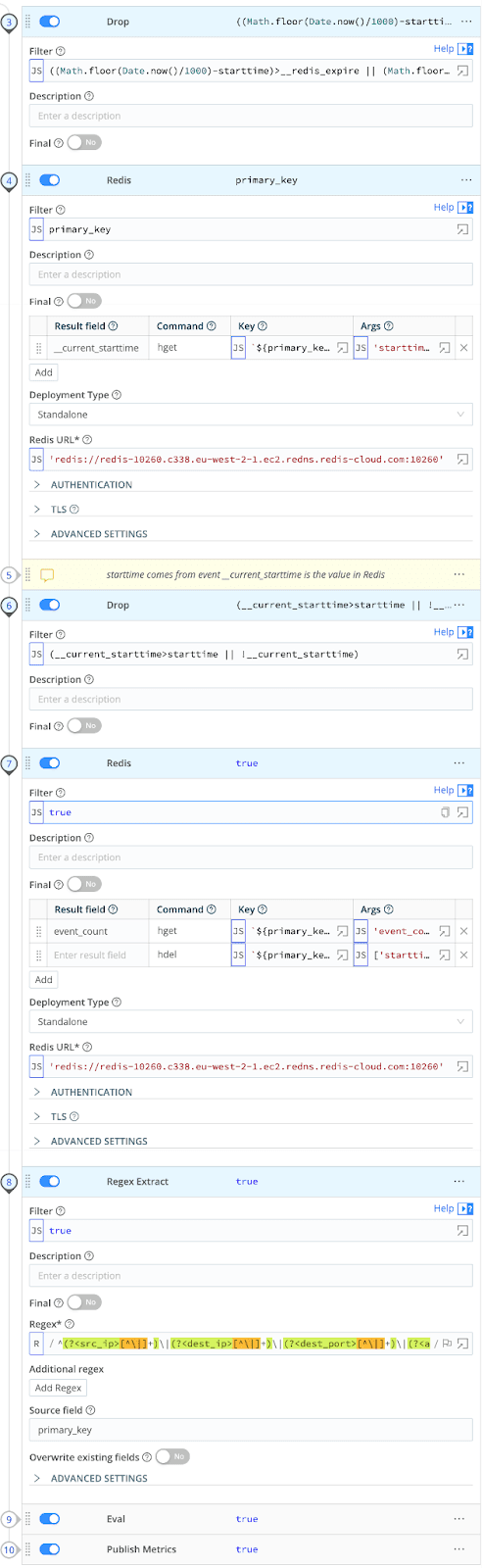
Orphaned Aggregates pipeline
The general Redis aggregation pipeline above will handle many of the scenarios where you might use this technique. It is great when you have a steady stream of events with the same dimensions. Given Cribl Stream's event-driven nature, it does require an event after the aggregation window has closed to complete path 3.
But what happens if that set of dimensions never occurs again? For example, a trace_id or, in this worked example, a firewall connection occurred once and then never happened again.
This is where our second pipeline comes into play.
In path 1 of our general Redis aggregation pipeline above, we created our entry in Redis and then sent an event with our key and start time to Cribl Lake, and this is the key to handling those orphaned aggregations.
We can schedule a collector to collect the events from Cribl Lake periodically. These can then be used to flush the events using our orphaned aggregates pipeline. In this pipeline, we can check to see if the aggregate is still in Redis after it was expected to have been closed out and then cleanly close it out and remove it from Redis.
If the key is still in Redis, we can perform similar functions to Path 3, where we collect the current state of the aggregation and then flush it out as a metric to our metrics destination. We will also remove the key from Redis at this point.
Here is the workflow of what both pipelines look like together.
Wrap Up
This technique will allow you to end up with a single aggregate event or metric for a given aggregation window, but it is more complex to achieve. It is an approach that will support you when you need to distill a large number of events into a small number of powerful data points to meet your business goals
This technique also demonstrates the powerful capability of Cribl Stream, the ability to integrate with Redis. Integrating with Redis unlocks the power of having events impact subsequent events, unlocking even more use cases for Cribl Stream.
I recommend reviewing this, and other Redis use cases within the Cribl Redis Knowledge Pack for more ideas on leveraging Redis within your Observability and Security objectives using Cribl Stream.






