

The inspiration for this blog comes from working with two Cribl customers. Cribl Stream can replay any data from object storage to systems of analysis, without the need for any code. But sometimes it makes more sense to keep the data inside of an object storage platform if the data set will be extremely large to collect and forward.
AWS Athena is a serverless interactive query builder that is designed to run queries across tera/petabytes of data residing in Amazon S3. Because Stream writes data to S3 object storage in JSON format, the AWS Athena service can perform SQL-like queries against the data stored in the bucket. This allows you to retrieve logs from cold storage while keeping your analytics solutions running at high performance by running long lookback searches separately.
This blog explains how to set up the necessary AWS services to query the logs inside an Amazon S3 observability lake using AWS Athena.
Getting Started with an AWS Glue Crawler
Create a new crawler in the AWS Glue service.

Give the Crawler a name. I’ve called mine “Stream Logs” for the purposes of this blog.

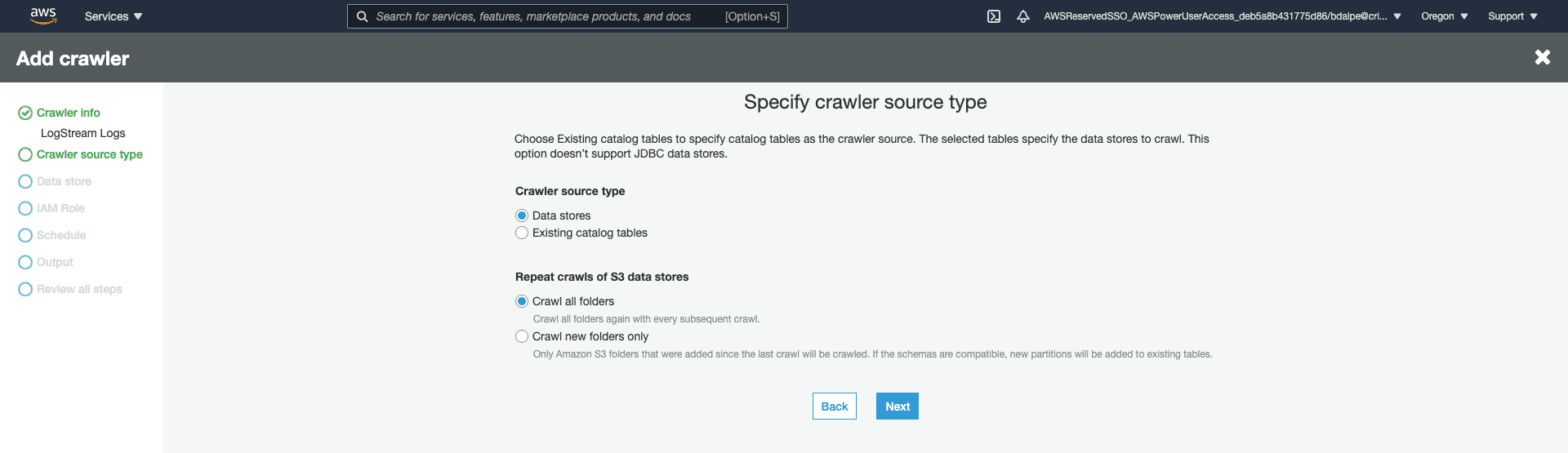
Set the crawler to the appropriate settings. I would recommend using the “Crawl all folders” settings, to find any new fields that may have appeared in a pipeline change.
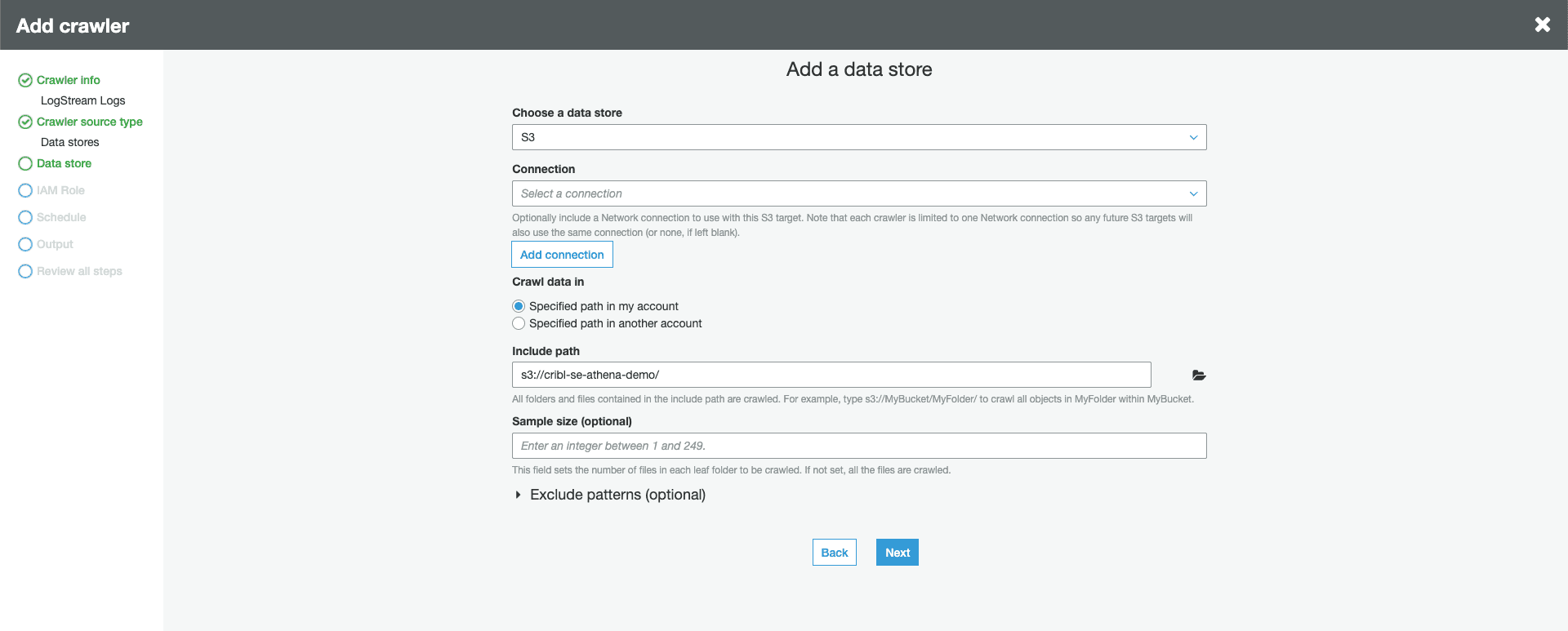
Configure the crawler to look inside the Stream bucket. Optionally, specify a subfolder path. This is important if you only want to query a specific set of logs, depending on your S3 destination partitioning structure.
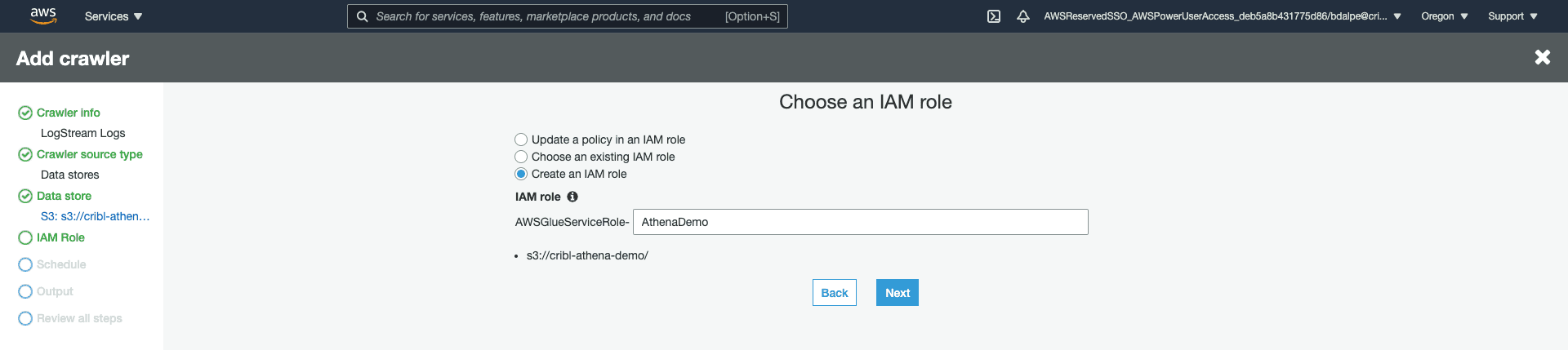
Configure the Crawler to use the appropriate IAM permissions. In this demo, I am creating a new role for the AWS Glue Service to use.
Schedule the frequency to run the Crawler. If fields are not changing frequently, running on-demand is probably sufficient. Otherwise, configure as desired.
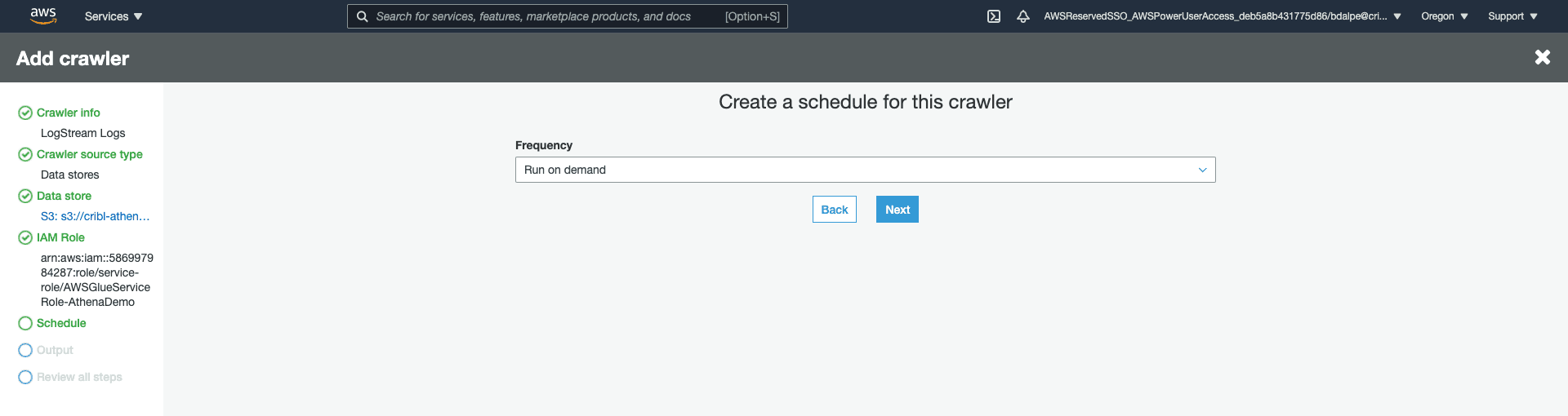
Set up the Crawler to output to a new Database. I’ve named the new database “logstream”. This will be displayed as a new data source inside the Athena console.
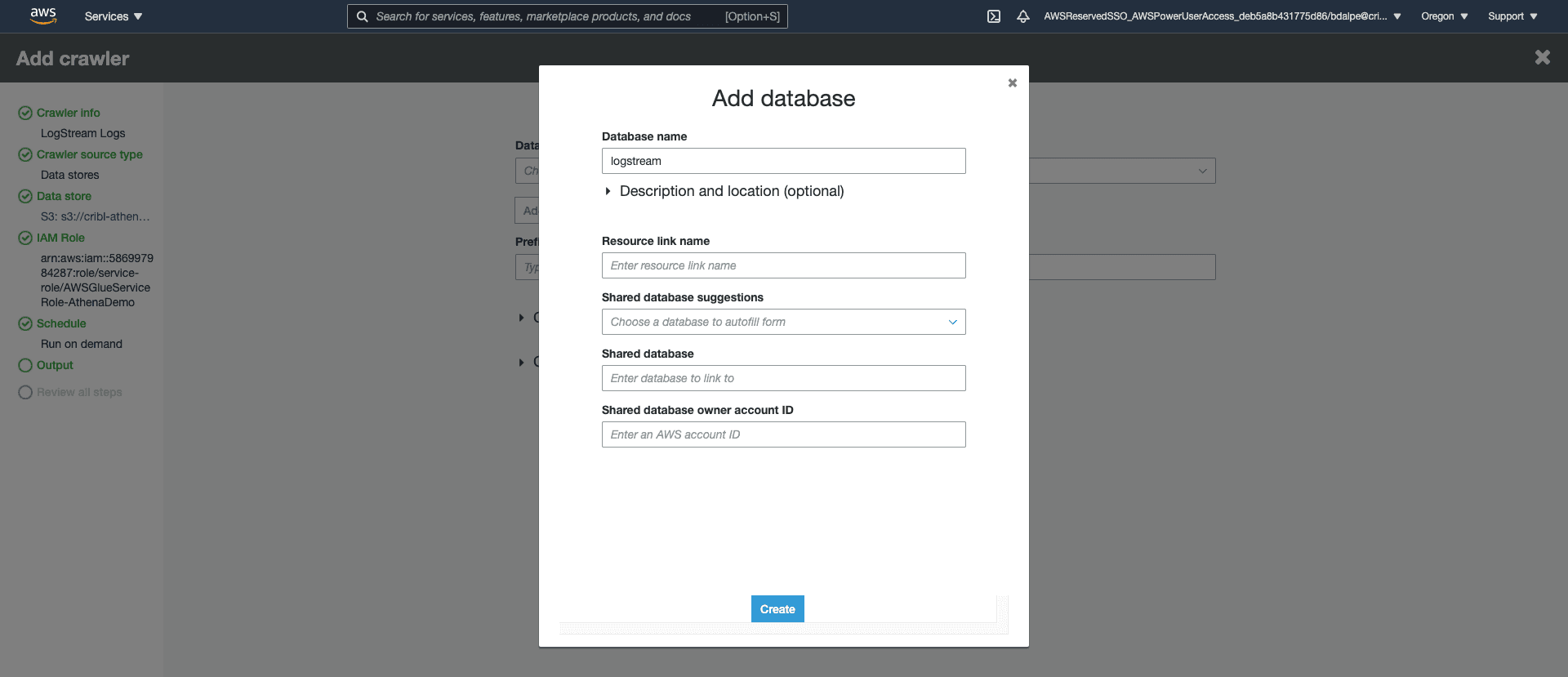
Optionally, specify the table grouping. This is useful if many sources/source types of data are written into the same bucket. They will appear as different tables that you can query against.
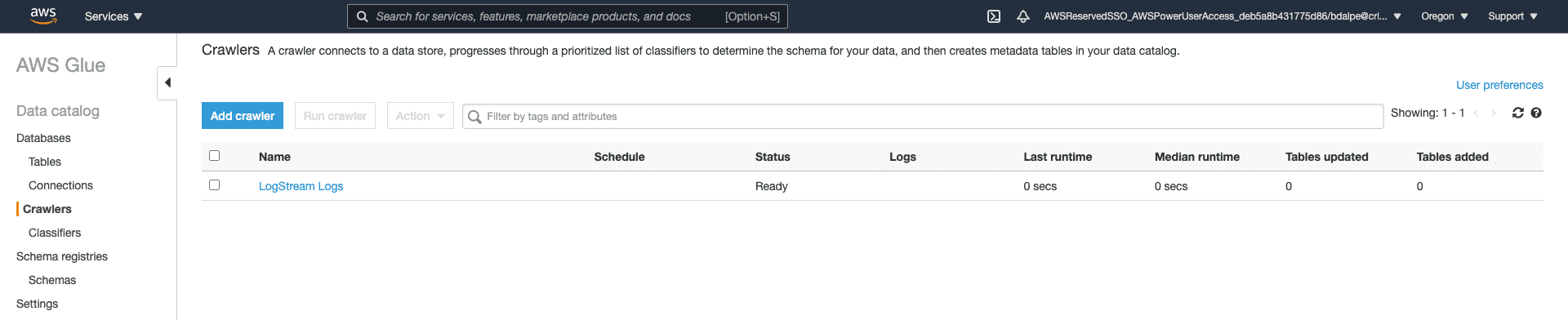
Now that the Crawler has been configured, you can run the job.
Use Athena to Query Logs in the S3 Bucket
In AWS Athena, you should see the new “logstream” database and the newly created table from the Glue crawler job. In the results, we can see the metadata fields from some Palo Alto Networks firewall logs we were receiving.
Before we start writing queries, we need to configure an output S3 bucket for the query results.
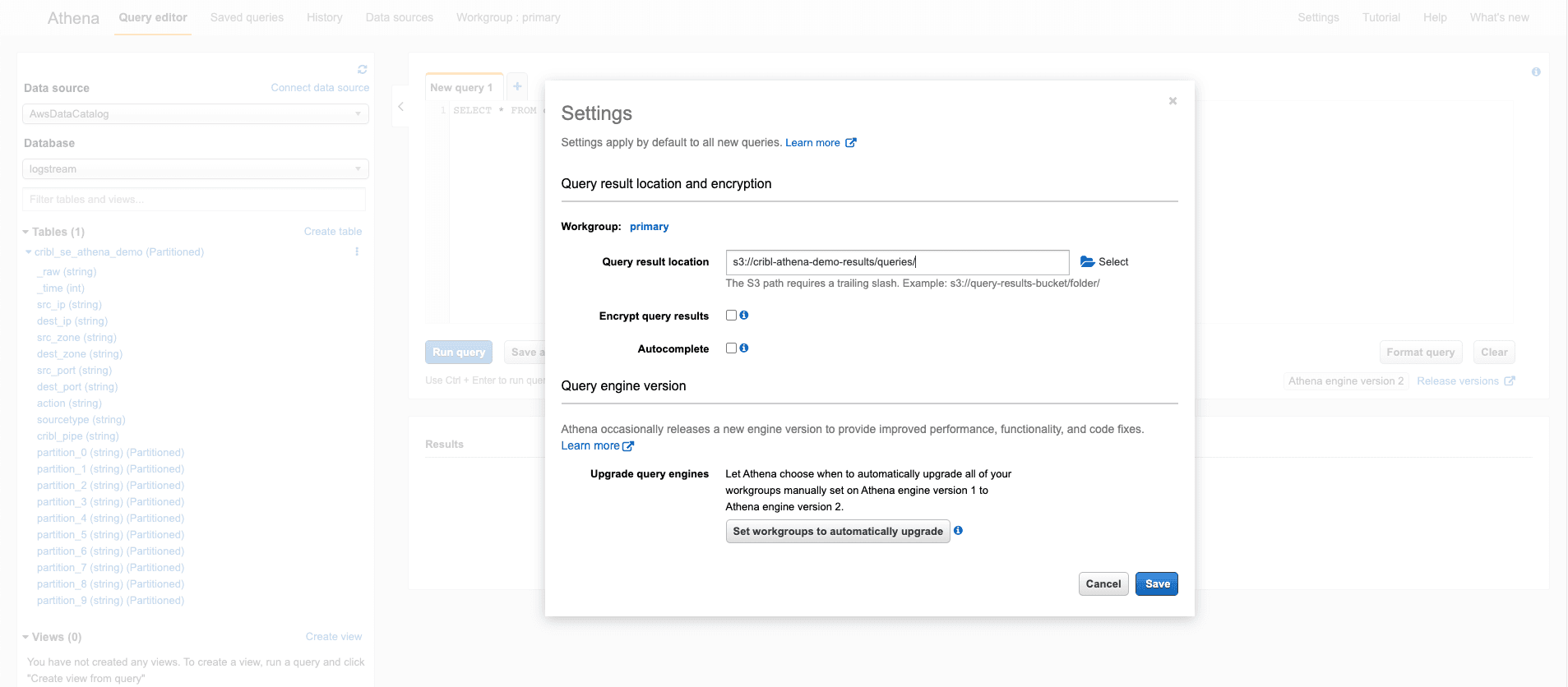
Configure the query result location to write to an S3 bucket. Ideally, you would write to a different bucket than the one used as the Stream S3 destination.
Once you run the query, the results are shown in the preview window below. The full results are written to the S3 query result bucket you configured in the previous step. For example, If I were to look in the logs for a source IP of 10.0.1.4 and destination port of 8088, I could write the following query: SELECT * FROM cribl_se_athena_demo WHERE src_ip='10.0.1.42' AND dest_port='8088'
Clicking the “Run query” button will populate the results.
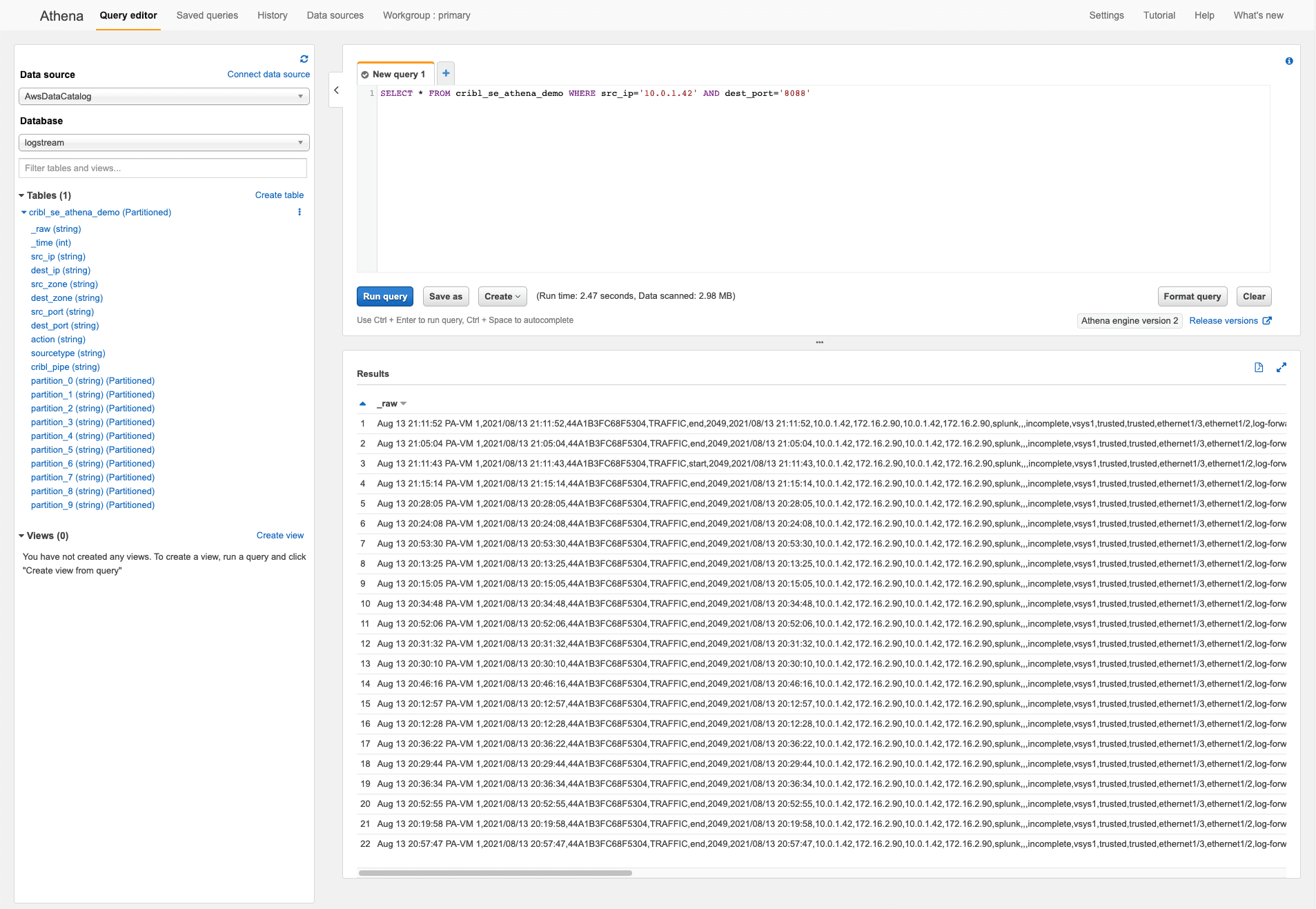
And scrolling to the right in the results window shows all of the other extracted fields in the events. We can use these in subsequent queries to further refine the data we are looking to locate.
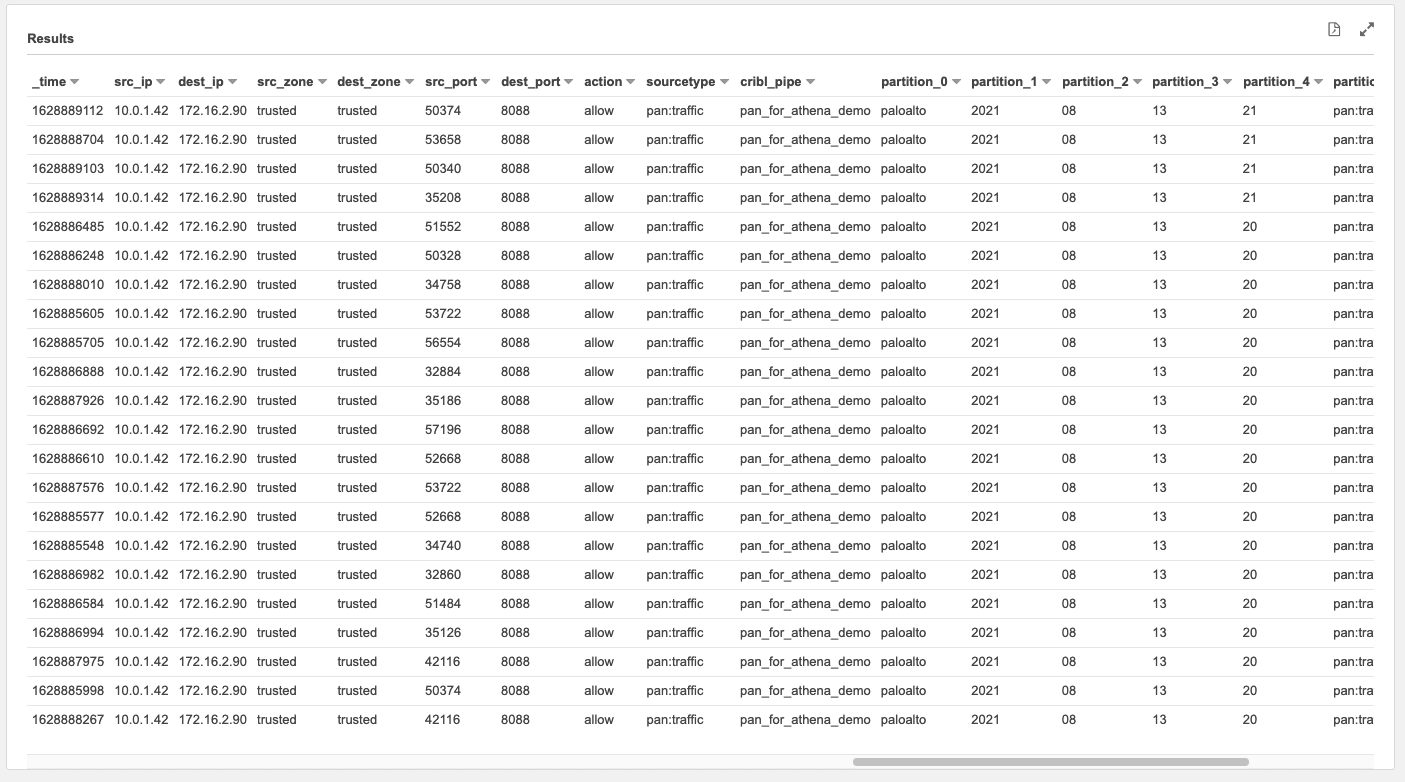
You can further refine your query by using the partition values to limit the amount of data being accessed, because each partition relates to the S3 partition (folder) structure. This partition is configured in the Stream S3 destination.
Notes on Cost
There are three places AWS will charge you for data in this example:
S3 Storage ($0.023/GB at standard storage tier)
Glue crawler jobs ($0.044 per DPU-Hour with a 10-minute minimum per crawler run).
Athena data access ($5 per TB of data scanned). Compressing the data in the S3 bucket results in a savings, because Athena has to scan less data. Low-cardinality data compresses well, and will save you money when scanning with Athena.
Conclusion
In this blog, we examined how to set up a simple AWS Glue crawler and Athena query to search logs written to S3 object storage from a Stream deployment. Maybe Stream replay doesn’t fit the use case for sending data back to your analytics tools? With AWS Athena, you can quickly query the data right inside S3, without the need to collect and forward to your analytics platforms.
Want to learn more about Cribl Stream? Play in our Sandboxes, Sign up for a Cribl.cloud account, and connect with us on our Community Slack.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.




