

Data governance gets thrown around a lot, but what does it actually mean? Who owns it? And how do you use it to get better visibility into your data? In a world where data is everywhere and moving fast, having a solid handle on what you collect, where it lives, and who can access it isn’t optional.
Let’s start with the basics. What is data governance, and why should you care about it in your observability strategy?
Data governance is the practice of managing the availability, usability, integrity, and security of your data. It means setting the right processes, policies, and standards to make sure your data is well-managed and in line with both internal goals and external regulations. The tricky part is that those standards often vary from one organization to another. And that’s totally expected.
In my day job, I talk to a lot of observability teams. No two have the same governance setup. Observability data is messy, unpredictable, and different everywhere. That makes flexible governance tools even more important.
The good news is that Cribl gives you the building blocks to create the right governance model for your organization. Whether you need to control access, route data based on rules, or just get a clearer picture of what’s flowing through your systems, we can help.
So what’s in it for you? Here’s what strong data governance can unlock:
Enhanced Data Quality
Optimized Data Management
Data Federation & Better Data Accessibility
Higher Trust in Data Fidelity
Accelerated Feasibility of Data Strategies
It just looks and feels better!
Why is Data Governance a Challenge?
A lot of organizations already know about data governance and have programs in place at different levels of maturity. Most of the time, those programs focus on transactional data. However, observability data is a different story.
Observability data is messy. It’s inconsistent. And a lot of the time, it’s custom and depends on how developers are instrumenting their apps. That makes it harder to govern using traditional playbooks.
Now let’s talk about data formats. Imagine you push a new code build and suddenly your data looks different. Maybe PII is now showing up in your logs. Maybe the schema changed and broke a bunch of dashboards or search queries. These are just a few of the things that can go wrong.
The common thread here is increased risk. And when you are managing data at scale, the volume and variability only make things harder. Data sets grow fast and change often. Keeping up takes real effort.
All my data engineers and administrators out there know exactly what I am talking about. You deal with this every day, and we salute you for it.
Elements of Data Governance
Data Governance involves people, processes, and systems (the golden triad of technology). However, the ultimate goal is to give teams control, visibility, and flexibility. We’ll discuss these elements below and then discuss how Cribl can help with each.
Data Quality Management
Your insights are only as good as the quality of your data. After all, garbage in = garbage out, am I right? Quality Management could include things like discarding low value events, schematizing and/or normalizing your data, monitoring for bloated events, and more.Data Integration, Traceability, and Interoperability
Data needs to be federated across an organization. Haven’t you ever had one of those days where you realize you could’ve solved an issue or outage THAT much faster if you had access to a given dataset? Realistically, not everyone in a given organization is using the same tools, platforms, or protocols. With data governance, you need a way to integrate data sources and destinations, trace the original source of the data and essentially interoperate in a very dynamic environment.Data Stewardship
Stewardship of data is an important concept as organizations move to a distributed data ownership model. Realistically, there typically are so many sources of data that there isn’t necessarily one group that owns it all. Ownership and accountability of data is important. A number of trends suggest organizations are moving towards self-service models for data owners in centralized platforms. This allows faster data management velocity combined with accountability/ownership of data residing closer to those who understand the business objectives of the organization.Data Security and Privacy
With the increasing volume of data generated, organizations must implement robust security measures to protect personal and proprietary data, ensuring compliance with regulations like GDPR and HIPAA. Effective data security not only prevents financial and reputational damage but also fosters trust among customers and stakeholders, creating a secure environment for data-driven decision-making. By prioritizing security and privacy, organizations can harness the full potential of their data while minimizing risks and safeguarding their assets.Data Change Management
Data change management is crucial within data platforms as it ensures that any modifications to data are systematically controlled and documented. This process minimizes the risk of errors, data loss, or inconsistency, which can arise from untracked changes. Effective data change management promotes transparency and accountability by allowing teams to understand the impact of changes on data integrity and overall system performance. Additionally, it facilitates compliance with regulatory requirements by maintaining a clear audit trail. Ultimately, a robust data change management strategy enhances the reliability of data platforms, supporting informed decision-making and fostering trust in data-driven initiatives.Data Conformance and Compliance
Data conformance and compliance are vital for ensuring that an organization’s data practices align with established standards, regulations, and internal policies. Conformance involves adhering to predefined data formats, structures, and quality standards, which enhances data consistency and reliability across systems. Data variability can not only cause issues downstream with broken dashboards/searches/etc, but can and may impact reliability.Performance Measurement and Visibility
Lastly, how well can you say you understand where all your data flows are in your organization? This is a challenge among many organizations and one that isn’t easy to solve due to the size, scale and complexity of observability environments today. Having visibility will not help you move faster during any incidents but also help you to complete any strategic initiatives within your organizations a lot faster.
Implementing Data Governance in the Cribl Platform
Cribl’s four products can help you achieve your Data Governance objectives in various ways. We’ll be touching in more detail below on use cases that Cribl Stream can assist you with. However, we’ll share a few high level use cases on Search and Lake as well. Below, we’ll be touching on use cases that Cribl Stream can assist you with in more detail
Within Cribl Stream/Edge:
Below are several different governance use cases available in both Cribl Stream and Edge.
Schemas
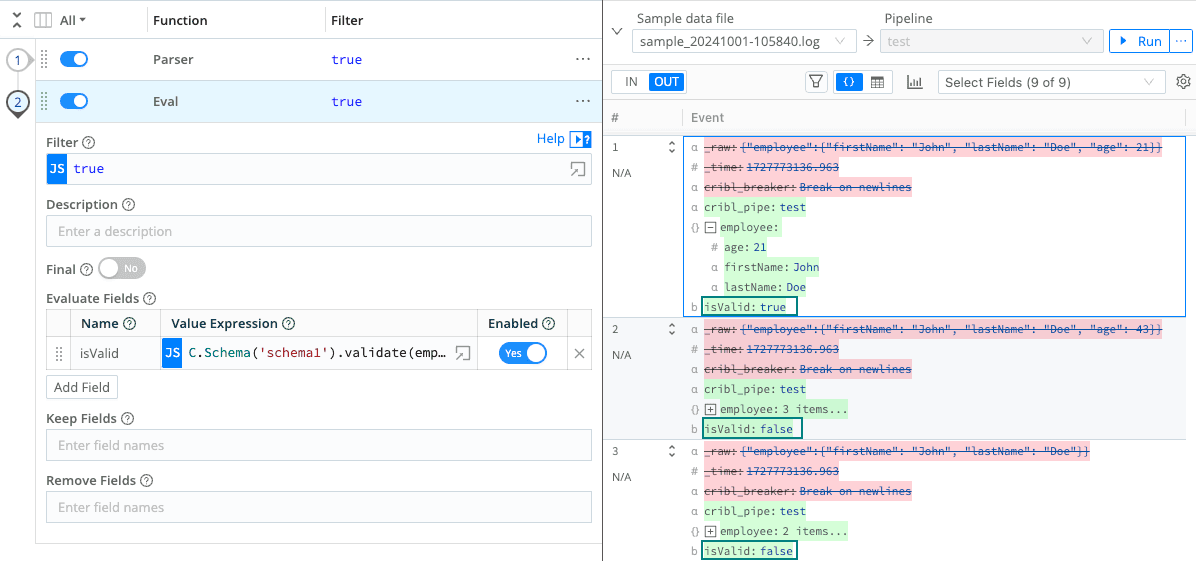
We all know Data Drift is an issue. One second, your data is flowing, and the next, an upstream change has affected your data, causing ingestion issues in your monitoring platform. All your alerts, dashboards, and more were built with the expectation that the data follows a pattern or a schema. With Cribl Stream and Edge, you can detect schema variances while your data is in flight. Building a parquet or JSON schema is the prerequisite to that, but once you have that, a simple function to validate that schema will help you detect data drift and easily be able to flag or tag your invalid data.
Masking
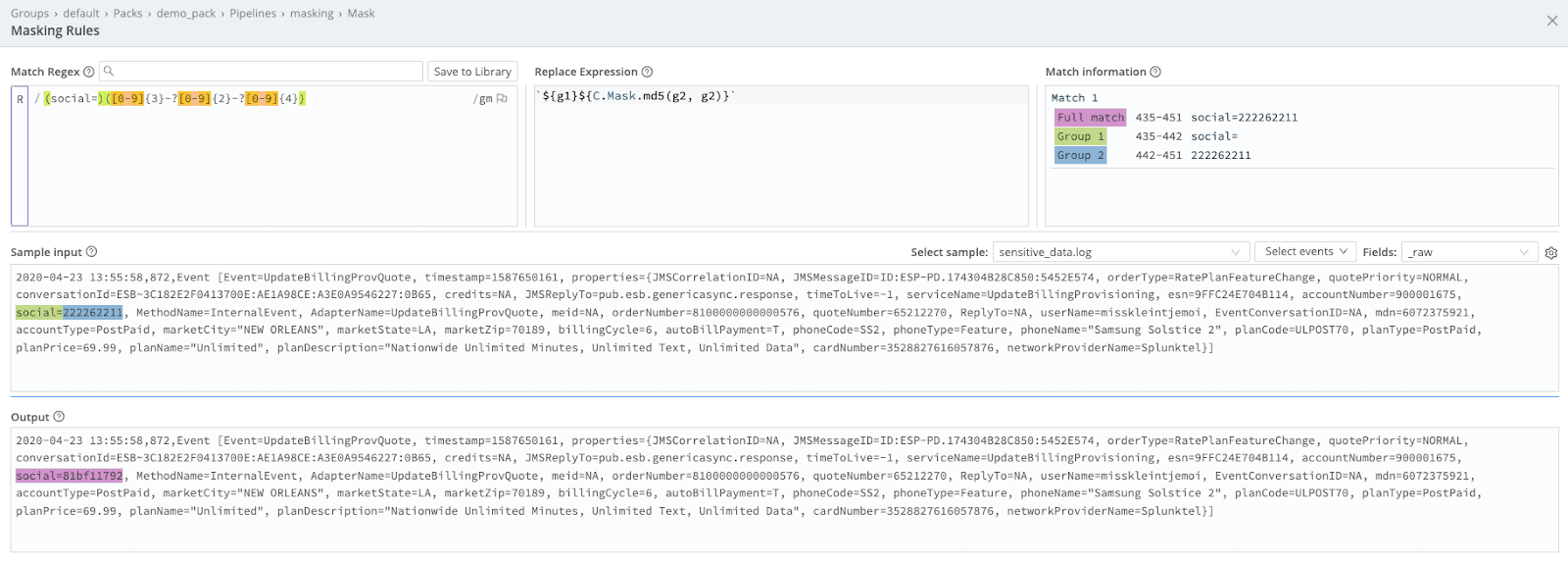
We all know sensitive data is floating out there: PII, PHI, and more. Oftentimes, we want to federate data among our business to give better visibility. However, we can’t always share sensitive data with those unauthorized to view it. By leveraging the mask function, we are better able to hide parts of the data, govern it, leverage checks and schemas, and route it off to a system of analysis for everyone to use. Cribl Stream and Edge make this possible by adding a Mask function in your pipeline. As an added bonus, you can learn more about Cribl Projects at this link as an alternative to democratizing your data.Checking Data “metadata”
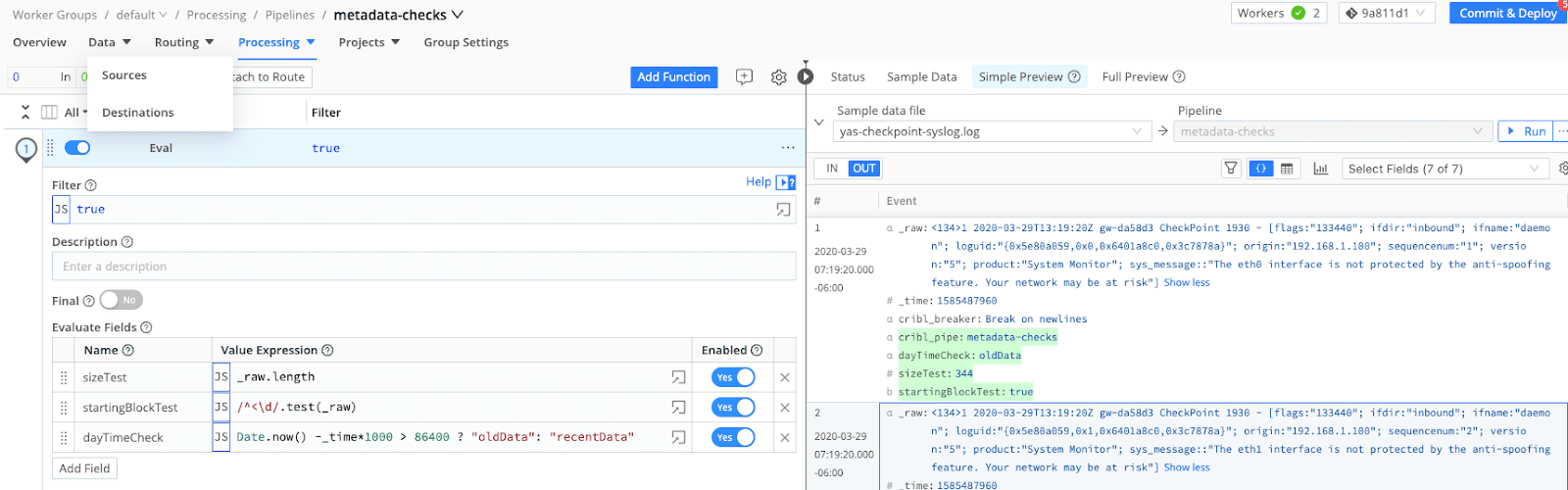
The metadata behind our data can say a lot! Do starting patterns change? Do lengths vary dramatically? Does time drift significantly in our events? All of these and more can be answered by creating functions to validate and check the metadata of our data to better understand and recognize patterns in our data. Leveraging these tags can help us better route our data, looking for data conformance or perhaps over-bloated events that don’t belong in our analysis system.
Visibility views of data flows and data lineage
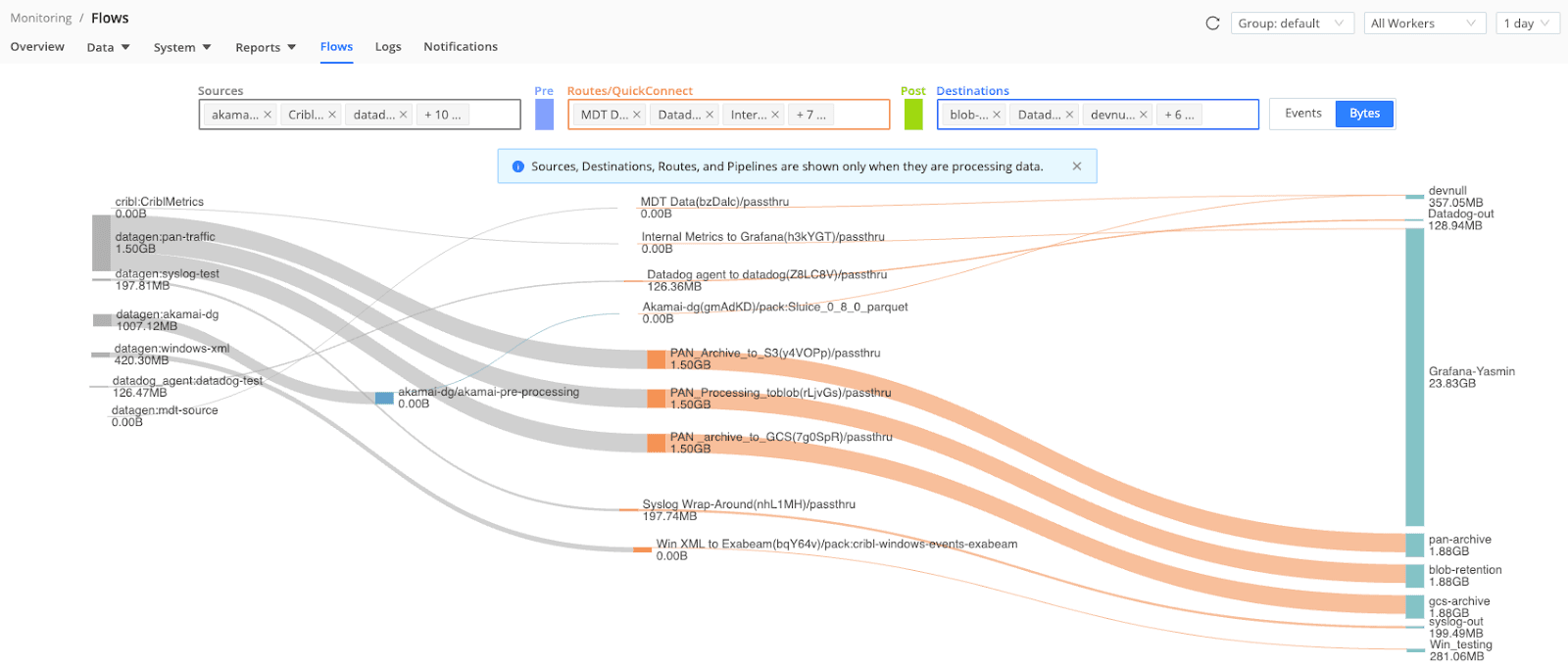
Ever wish you had a map of all the data flows in your organization to show you where data originated and where data was ultimately going to? That’s easy in Cribl Stream. Navigate to the Monitoring > Flows tab and you can get a view of your Worker Group data flows by Events or Bytes. Having this visibility can give you better governance to ensure your data flows are expected, have the expected volume and path, as well as help you to ensure you a bifurcating data where needed.Enrichment and tagging
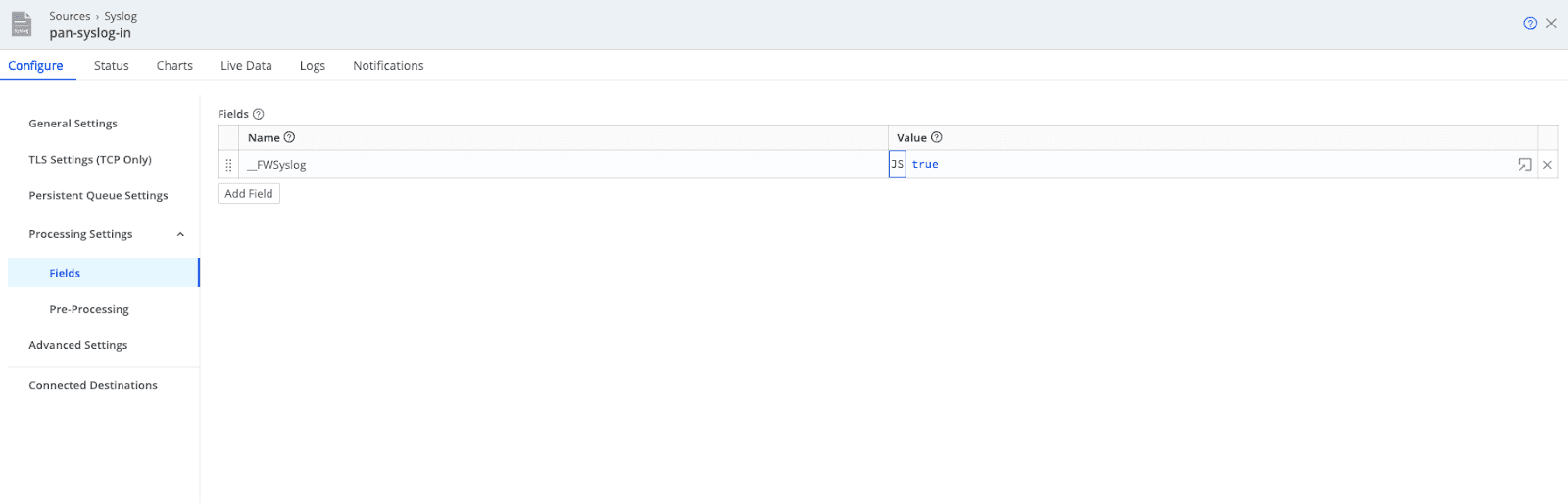
Data enrichment and tagging is a core use case for Cribl Stream, but it is also a pillar of data governance. Classifying events gives you better insights, tighter access control through RBAC, and faster search performance in downstream tools by adding context that helps narrow the scope. There are several ways to apply enrichment depending on where you are in the pipeline. One of the easiest places to start is at the source. In the image below, you’ll see a double-underscore field tag added to events right as they enter Cribl Stream. You can also enrich at the destination using post-processing pipelines, or directly within your pipelines if you need more fine-grained tagging. Check out this link to see how one customer put this into practice.
Restructuring/Data format changes (OTLP Logs example)
We all know there are about a billion and one data formats. Various platforms will require different structures for ingestion and parsing depending on their back ends. For example, we use the OTLP (OpenTelemetry Protocol) format in OpenTelemetry because it provides a standardized, efficient, and vendor-neutral way to transmit telemetry data such as traces, metrics, and logs. OTLP is optimized for performance, supports multiple transport protocols (e.g., gRPC, HTTP/JSON), and ensures compatibility across diverse systems, enabling seamless observability in distributed applications. However, we may NOT always be collecting data from OTel sources such as the OTel Collector. The question is, how do we get our data into the correct OTLP format? Cribl Stream can accomplish this. For Metrics, it’s easy; the OTLP Metrics function quickly and easily converts dimensional metrics into the OTLP metrics format. Below is an example of converting a syslog based raw event into OTLP log format. Cribl can accomplish any to any transformation of data needed making it flexible enough to support any collection tier to any destination. In terms of governance, this helps to centralize all your data sources regardless of type or format since you are now able to control each of the data formats in your data flexibly flows.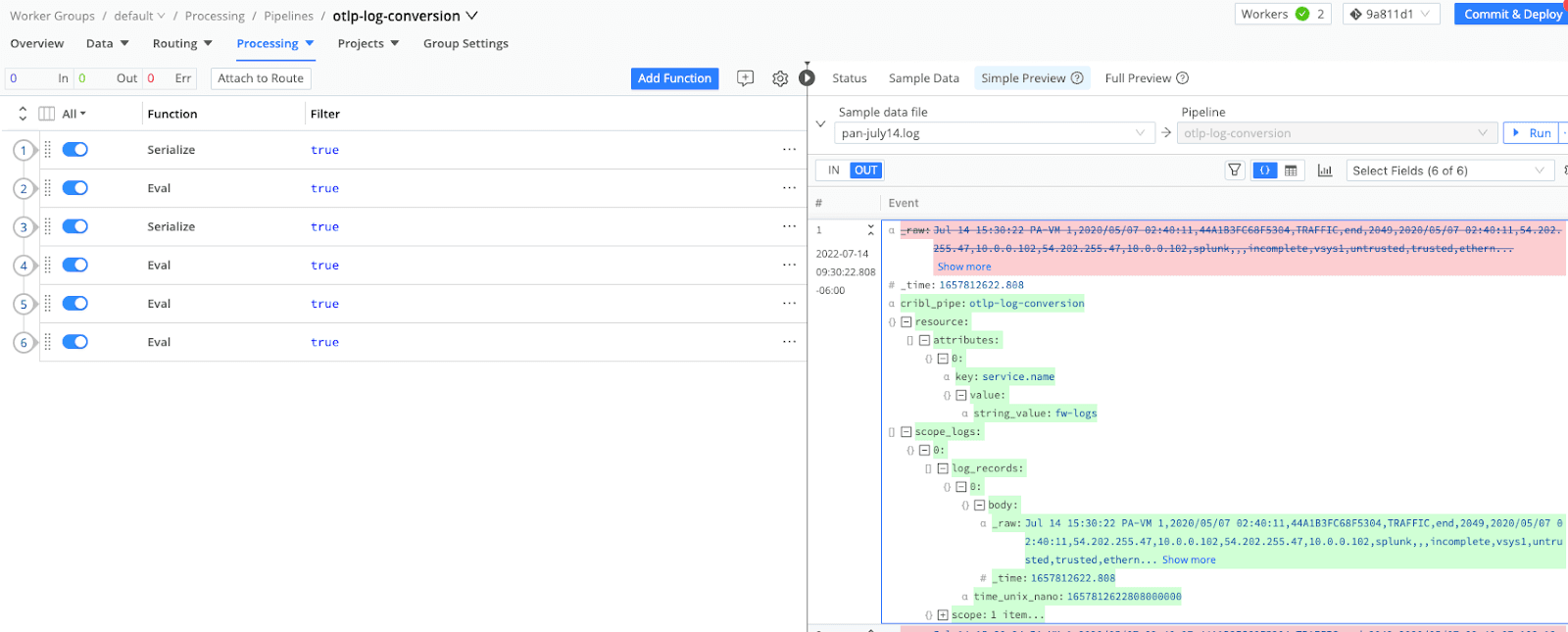
With Cribl Lake:
Compliance & retention stores
Data governance typically encompasses how you ultimately store your data as well. Do you keep it searchable in hot storage for long periods of time? What is your age-out strategy? Are there any policies or compliance requirements that dictate how long you need to retain your data and what accessibility requirements there are around that data? Regardless of what your goals are for retention, Cribl Lake can help by creating an easy to manage data lake that you can easily route data to from Cribl Stream. Cribl Lake gives you the ability to quickly create and route data to a data store, control access and retention policies on that data, and ultimately access that data when you need it.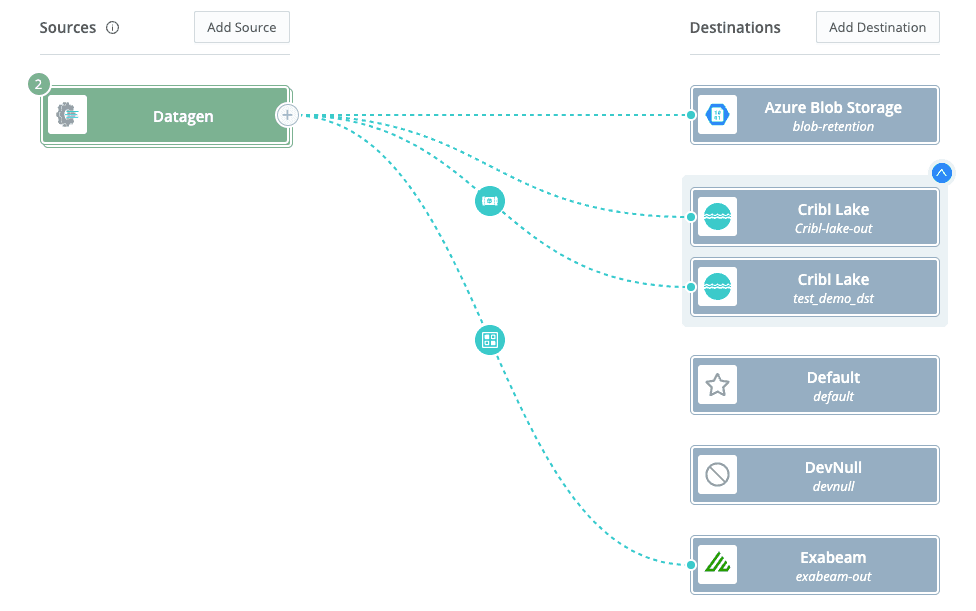
With Cribl Search:
Conformance Searches
Last but not least is Cribl Search. The one thing that is a given is that change is constant. Detecting the changes in data is a little bit more challenging and ultimately, with data governance practices, you want to manage the data quality of your data closely. Cribl Search gives you the ability to do so by building KQL queries to detect data changes and schedule those to run on a scheduled basis.Data drift
Oversized events
Broken events
And more…
Conclusion
In summary, bringing Cribl into your data governance strategy gives you the flexibility and control you need to manage data at scale. It helps improve data integrity, supports compliance, and adds real strategic value. With better visibility and accountability across your data pipelines, you can get more out of your data while staying aligned with the governance standards your organization depends on.





