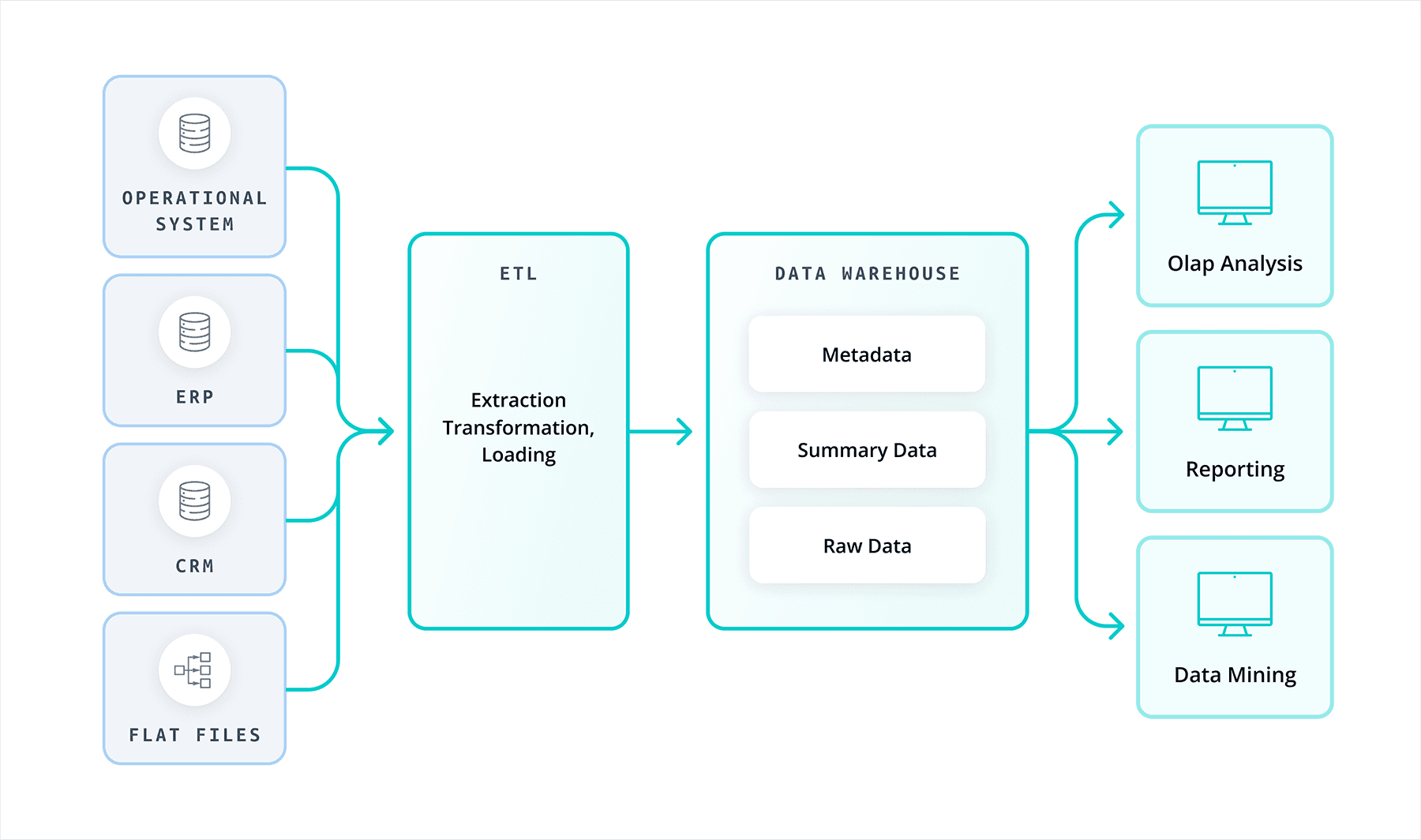
Data consolidation is the process of bringing data together from various sources and assembling it within a single location. This process allows users to engage data from multiple sources into a single point of access and typically involves combining or aggregating the unique data sources for one of many reasons. You can then aggregate, summarize and optimize metrics, fostering the generation of data insights gathered from the aggregate. This process aids in creating unified metrics for easier analysis and consistent reporting.
Data is coming at you from every direction — cloud apps, security tools, logs, metrics, customer platforms — and it’s not slowing down. If you’re piecing it together manually or relying on disconnected systems, you’re wasting time and missing insights.
Data consolidation changes the game. By bringing data from multiple sources into one place, you simplify management, improve data quality, and unlock faster, smarter decision-making. No more juggling silos or drowning in raw data.
We’ll unpack what data consolidation really means, walk through proven methods, flag common mistakes, and show you how Cribl makes it simple to consolidate, transform, and route your data exactly where you need it.
Understanding the difference between data integration and data consolidation
It’s easy to mix up data integration and data consolidation — they sound similar, but they serve different purposes in your data strategy. Let’s break it down.
Data integration is all about getting your data to flow seamlessly between systems. Think of it as the plumbing: it connects multiple sources and routes the data to various destinations, ensuring that everything moves smoothly across your architecture. Whether you’re pulling from CRMs, cloud services, or security tools, integration is what lets you collect, process, and deliver data where it needs to go.
In Cribl, this means setting up:
Sources: Where the data comes from.
Destinations: Where the processed data goes.
Plus, smart features like backpressure triggers, persistent queues, and load balancing to keep things running reliably.
Learn more about Cribl Integrations.
On the other hand, data consolidation happens a step deeper. Once your data is flowing, consolidation focuses on optimizing and simplifying that data to make it actionable. You’re not just moving data — you’re cleaning it up, reducing complexity, and shaping it for better performance.
With consolidation, you’re:
Tackling high-cardinality data by consolidating, aggregating, or dropping noisy metrics.
Optimizing metrics by grouping similar ones and rolling them up over time.
Normalizing data from different systems into a single, unified view.
So, while integration keeps your data moving, consolidation makes sure that data is useful, efficient, and ready for analysis. Both are essential — integration feeds the pipeline, consolidation tunes it for performance.
Data Consolidation Techniques
Businesses have several options when it comes to consolidating data, depending on their infrastructure, data volume, and technical expertise. Let’s explore the most common techniques.
Hand Coding
Hand coding involves manually writing scripts to extract, transform, and load (ETL process) data from various sources. Developers typically use languages like Python, SQL, or Java to build custom pipelines. While this method offers maximum control and customization, it is time-consuming and requires significant technical skill. Moreover, maintaining and scaling hand-coded solutions can become a bottleneck as the amount of data grows.
ETL Software
ETL (Extract, Transform, Load) software automates much of the data consolidation process. These tools streamline the collection of raw data, automate transformations, and load consolidated data into a data warehouse or data lake. ETL software reduces the need for hand coding and improves efficiency, making it easier to manage data from multiple sources.
ETL Tools
Beyond full-fledged ETL software suites, there are specialized ETL tools that offer more targeted capabilities. These tools focus on specific tasks like automated data extraction, data cleansing, or metadata management. They are particularly useful for businesses looking to enhance an existing data pipeline without rebuilding it from scratch.
How to Choose the Right Technique?
The best technique for your organization depends on several factors:
Volume of data: Larger data sets benefit from automated ETL tools.
Technical expertise: If your team lacks coding skills, ETL software offers a user-friendly alternative.
Scalability: Consider future growth. A flexible, scalable solution like Cribl Stream helps avoid future bottlenecks.
Real-time needs: If near-real-time processing is required, choose solutions that support streaming data pipelines.
Pro Tip: Not sure if ETL is the right fit, or if you should go with a broader data pipeline approach? Check out this guide comparing Data Pipelines and ETL to choose the best strategy for your data needs.
By carefully evaluating your business needs and technical environment, you can select the most efficient technique to ensure a successful data consolidation project.
How the Data Consolidation Process Works
The data consolidation process defines how data is systematically discovered, extracted, transformed, loaded, integrated, and stored to create a reliable dataset for business intelligence and decision-making. The data consolidation process involves several key techniques to manage and optimize data to improve data visibility and insights.
Some examples used by Cribl Stream include:
1. Reducing High-Cardinality Data - Start by tackling high-cardinality data — the kind that’s packed with unique dimensions and uncommon values. Left unchecked, it clutters your dashboards and slows down queries.
Consolidate: Merge metrics with large numbers of unique dimensions to simplify your data landscape.
Aggregate: Summarize metrics to trim down the total number of time series, making analysis faster and cleaner.
Drop: Cut out noisy, low-value metrics with uncommon values to improve overall query performance.
2. Optimize Metrics - Once you’ve reduced the noise, focus on organizing what remains:
Group and Segment: Categorize similar metrics into fewer groups to reduce complexity.
Time-Based Rollups: Aggregate high-frequency metrics into larger intervals (e.g., hourly or daily).
Combine Metrics: Merge related or duplicate metrics to create a unified metric.
3. Normalize Metrics - Finally, bring it all together by normalizing your data:
Aggregate from Different Systems: Combine metrics from various sources into a single, unified view for easier analysis and consistent reporting.
Cribl Stream automates much of this process, allowing you to select metrics to aggregate directly from the Data Preview, which then automatically adds the necessary functions to your pipeline.
Common Challenges of Data Consolidation
Data consolidation brings huge value, but it’s not always a smooth ride. Here’s where things tend to get tricky — and how to stay ahead of them.
Data Silos and Fragmentation
Data stuck in isolated systems is a common pain point. Breaking down these silos — especially across legacy tools and third-party platforms — can get complicated fast.
Solution: Use flexible tools that integrate data from multiple sources without the headaches.
Data Quality Issues
Messy data slows everything down. Inconsistent formats, duplicates, and gaps lead to bad analysis and even worse decisions.
Solution: Build in strong ETL processes for data validation, cleansing, and normalization to keep your data clean and trusted.
Scalability Concerns
As your data grows, manual or clunky systems struggle to keep up — leading to delays and rising costs.
Solution: Go with scalable solutions like Cribl Stream that handle large volumes and automate processing with ease.
Time-Consuming Manual Efforts
Manual coding and hand-built processes eat up time and increase the risk of errors.
Solution: Automate wherever you can. ETL tools and data consolidation tools take the manual effort out of the equation.
By tackling these challenges head-on, you’ll speed up your consolidation efforts and get more value out of your data — faster.
Data Consolidation Best Practices
The goal of any best practice is to ensure that businesses can navigate the process efficiently, maintain data accuracy and security, and leverage data for better decision-making. To that end, data consolidation should act like a universal receiver, a central hub that can automatically ingest data from a vast array of sources. This eliminates the need for complex configurations and custom scripting for each data source.
Data consolidation also needs to speak the same language as your data — and in Security and IT systems, that’s no small task. You’re dealing with hundreds of data types and formats, from Syslog to key-value pairs, JSON, CEF, OTel Spans, and beyond. (Pro tip: here’s a deep dive on OTel Spans and Metrics).
The good news? Consolidation supports hundreds of out-of-the-box protocols and parsers, so you don’t have to wrestle with custom scripts or manual normalization. Instead of decoding every cryptic format, you translate everything into a common language — fast, consistent, and accessible.
The result: your data flows smoothly, your analysis gets simpler, and you can ditch the need for one-off solutions for every data type in your stack.
Finally, since consolidation is potentially combining large numbers of sources, it requires an architecture with a focus on efficiency and scalability. Scalability to handle the expected load, but also a front end able to identify and pre-process data, filtering out unnecessary information before sending it onward. This reduces bandwidth consumption and ensures your data pipelines aren’t overloaded by irrelevant data. This is especially crucial in cloud environments where costs can quickly balloon.
Want to see how Cribl’s Universal Receiver cuts through data silos and streamlines integration? Check out this deep dive.
Data Consolidation with Cribl
Cribl Stream’s flexibility makes it a perfect fit, whether you’re dealing with traditional on-premises systems or modern cloud-based deployments. It can receive continuous data input from various sources, including Syslog, OpenTelemetry (OTel), Model Driven Telemetry (MDT), Kinesis, Kafka, TCP JSON, etc. This eliminates the need for separate collection systems for each data type reducing the maintenance and scaling challenges.
Cribl Stream’s unique capabilities as a universal receiver simplify the consolidation of data flows into a central tier for collection, processing, and routing. It is designed to ingest data intermittently, either on-demand (ad hoc) or on a scheduled basis. They can fetch or "replay" data from local or remote locations and are useful for optimizing data throughput by selectively routing only needed data to your systems of analysis.
These capabilities serve to simplify data management and reduce the strain on your teams while maintaining full control over your data.