
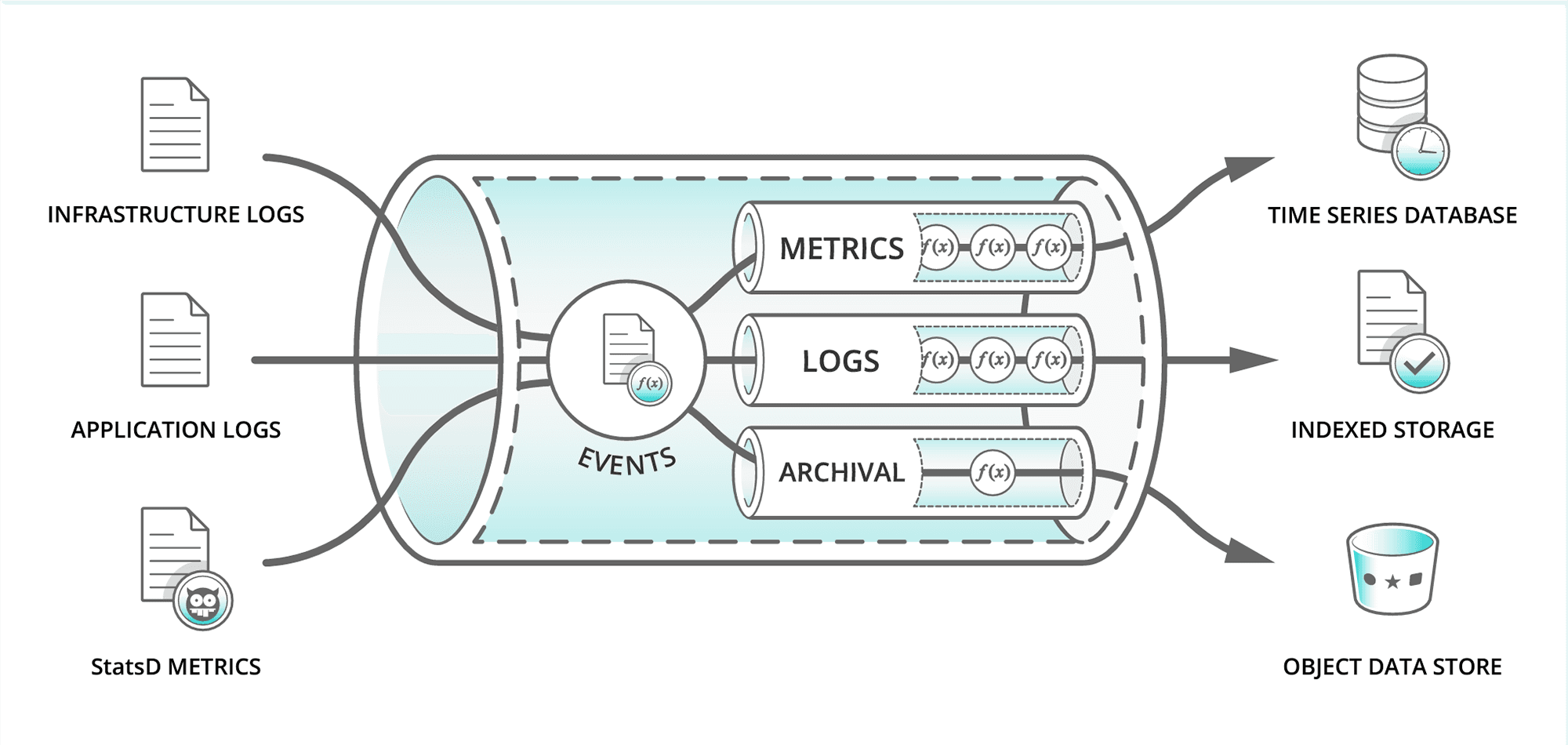
At its most basic level, a data pipeline can be seen as an aggregator or even a manifold that takes data from multiple sources and distributes that data to multiple destinations, eliminating the need for multiple bespoke systems. As the data transits the pipeline, it may also be acted upon, essentially shaped based on organizational needs and/or the requirements of a receiving system.
In today’s data-driven landscape, where decision-making heavily relies on data, the demand for streamlined and impactful data management has never been more critical. This is precisely where the concept of a data pipeline comes into the spotlight.
The internals of a data pipeline can be viewed as a series of steps or processes that shape the data in motion as it travels from its source to its destination. These tools and techniques perform an ETL (extraction, transformation, and loading) type function on the raw data and shape it into a format suitable for analysis.
Data pipelines are built using a combination of software tools, technologies, and coding scripts. Many companies offer data or observability pipelines. They share many common features like routing, filtering, and shaping, but each vendor also has some unique values. In addition to buying a data pipeline solution, some organizations may use open-source tools to build their own, either for cost-saving or to address specific issues in their enterprise. However, once it’s built, you have to maintain it forever, which might prove to be more expensive and complex than an off-the-shelf solution.
Types of Data Pipelines
Data pipelines come in a variety of types, some designed for a specific purpose, while others support a range of functionalities. Understanding them is crucial to optimizing data processing strategies. It enables enterprises to leverage the right approach for their specific needs and objectives. Let’s explore these types in more depth.
Batch processing
This pipeline function is specifically designed to process large volumes of data in batches at scheduled intervals. It excels in handling large datasets that do not require real-time analysis. By moving data in batches, it optimizes efficiency and resource utilization.
Streaming Data
As the name suggests, this function is designed to handle streaming data in real-time. It is particularly useful for applications that require immediate analysis and response, such as fraud detection and monitoring system performance. Processing data on arrival enables fast decision-making and proactive actions.
Hybrid Data Pipeline
Most data pipelines have some capability to support both capabilities. Combining elements from both to handle real-time and batch-processing needs. This flexibility allows companies to efficiently manage diverse data processing requirements, ensuring both immediate insights and comprehensive analysis.
Deployment Modes
Data pipelines are available as both cloud (SaaS) and on-premise (SW) solutions. The choice of deployment model is user-specific and may depend on security concerns and the location of data sources and destinations. Some vendors offer hybrid solutions that leverage both cloud and hardware/SW components.
What are the benefits of a data pipeline?
A well-designed data pipeline provides a range of benefits for organizations managing large volumes of data or seeking faster, more reliable access to insights. These advantages span operational efficiency, data quality, and business impact.
Automation and Efficiency
Data pipelines automate the movement and transformation of data, reducing the need for manual intervention. This streamlines operations and frees up engineering resources to focus on higher-priority tasks.
Real-Time or Timely Insights
Streaming or near-real-time pipelines enable organizations to access data as events happen. This supports time-sensitive use cases such as security monitoring, alerting, and operational analytics.
Improved Data Quality
By integrating validation and transformation steps early in the process, pipelines help ensure that only clean, structured, and consistent data reaches downstream systems.
Scalability and Flexibility
Modern pipelines are built to scale with growing data volumes and adapt to new data sources. They also support flexible architectures, including cloud-native and hybrid deployments.
Consistency and Reliability
Pipelines enforce repeatable, automated processes with built-in error handling and retry logic. This ensures consistent data delivery and minimizes the risk of loss or duplication.
Faster Decision-Making
By accelerating data flow from source to destination, pipelines help teams act on insights more quickly—whether optimizing operations, responding to incidents, or informing strategic decisions.
Data Pipeline Architecture
The architecture of a data pipeline can vary significantly, depending on the specific needs and complexities involved in managing the data, especially when building data pipelines for reliability. Some common components typically included in a data pipeline are:
Data Source
This encompasses a wide range of sources from which raw data is collected, including databases, files, web APIs, data stores, and other forms of data repositories. These diverse sources provide a comprehensive and varied pool of information that serves as the foundation for data analysis and decision-making processes. Think of it like this: before you can ingest data, you must attach a source to a data pipeline.
Agent / Extractor
This component is actually external to the pipeline. Typically, it’s located on the data source or between the source and the pipeline and plays a pivotal role in the data processing for seamless retrieval of data from its designated source. Its role is to efficiently collect and transfer data to the pipeline, playing an integral role in getting the right data into the pipeline.
Pre-Processing / Transformer
This is the first stage when raw data enters the pipeline. Here, the data is filtered and formatted data is cleaned and transformed into a more usable format for analysis. Meticulous data preparation ensures accuracy, consistency, and reliability, laying the foundation for meaningful insights and informed decisions.
Routes/ Loader
This component’s primary role is to forward the pre-processed data to its designated path for processing. Systems typically use a set of filters to identify a subset of received events and deliver that data to a specific pipeline for processing.
Processor
Data matched by a given Route is delivered to a logical Pipeline. Pipelines are the heart of data processing and are composed of individual functions that operate on the data they receive. When events enter a Pipeline, they’re processed by a series of Functions.
At its core, a Function is code that executes on an event. The term “processing” means a variety of possible options: string replacement, obfuscation, encryption, event-to-metrics conversions, etc. For example, a Pipeline can be composed of several Functions – one that replaces the term “foo” with “bar,” another one that hashes “bar,” and a final one that adds a field (say, dc=jfk-42) to any event that matches source==’us-nyc-application.log’.
Destinations
The final stage of the pipeline data processing is forwarding the data to the final destination. This can include data stores, systems of analysis, or many others.
The Future of Data Pipelines
By 2030, data pipelines will evolve to decouple telemetry collection from analysis, paving the way for advanced observability. This shift will eliminate the need for enterprises to swap agents to adopt new visualization tools or share telemetry across teams. Instead, agents will become versatile, powering multiple experiences without reconfiguration, thanks to the widespread adoption of OpenTelemetry (OTLP).
Translating between formats—such as logs to metrics or traces to metrics—will further reduce operational complexities, allowing teams to analyze, visualize, and correlate telemetry seamlessly. This evolution will break down barriers across technologies, enabling IT and security teams to work with unified, adaptable data pipelines.
Decoupling agents from their platforms is crucial to this transformation. By freeing agents from tightly coupled integrations, organizations will unlock the potential for true flexibility and innovation in their telemetry strategies. The result? A future where data pipeline tools adapt to the needs of the business, not the other way around.
Data Pipelines and Cribl
Data pipelines are the lifeblood of modern IT ecosystems, enabling the seamless flow of information from diverse sources to analytical tools. Cribl elevates this foundational concept with a transformative approach that prioritizes flexibility, efficiency, and independence from vendor lock-in.
With Cribl Stream, organizations gain access to a universal receiver capable of ingesting telemetry data—logs, metrics, traces, and more—from any source, regardless of format or protocol. This removes the complexity of managing multiple, siloed data collectors across disparate systems.
Cribl’s universal telemetry receiver functionality not only simplifies ingestion but can normalizes telemetry data, ensuring compatibility with all of your tools and ease of management. This feature breaks down silos, empowering organizations to share data freely across IT, security, and operations teams without duplicating configurations or creating unnecessary workloads.
When it comes to routing telemetry data, Cribl Stream shines by enabling data to flow to multiple destinations simultaneously and only collecting it once. Whether integrating with AWS, Azure, GCP, or on-premises storage solutions, Cribl optimizes costs by directing only the necessary data to high-expense analytics platforms, preserving resources for innovation. The flexibility to route telemetry anywhere adds an unmatched level of agility to telemetry data pipeline strategies.
Cribl doesn’t just simplify telemetry data pipelines—it redefines what they can do. With its powerful, scalable, and adaptable functionality, Cribl Stream enables organizations to build smarter, more efficient telemetry data ecosystems, ready to tackle the challenges of tomorrow.
FAQ
What is meant by a data pipeline?
A data pipeline is a series of processes that moves telemetry data from a source to a destination while transforming, enriching, or organizing it along the way. It ensures seamless data flow for analysis, visualization, or storage.
What is an example of a data pipeline?
An example is a telemetry pipeline that collects user activity logs from a website, processes them in real time to generate metrics, and sends the insights to a dashboard for monitoring for user experience.
Is a data pipeline an ETL?
Not necessarily. ETL (Extract, Transform, Load) is a type of data pipeline focused on structured data workflows. Data pipelines encompass broader use cases, including real-time processing, data routing, and telemetry management. Learn more about the differences between both and which is best for your data strategy here.
What are the main 3 stages in a data pipeline?
Ingestion: Collecting raw data from sources.
Processing: Transforming, enriching, or organizing data.
Delivery: Sending processed telemetry data to its final destination, such as storage or visualization platforms.






