

Security teams are collecting more telemetry than ever, but most traditional SIEM architectures were never designed to retain and analyze petabytes of data economically. Between cloud infrastructure logs, SaaS audit trails, endpoint telemetry, identity events, and application data, organizations are forced to choose between retaining everything or controlling costs.
That tradeoff is becoming harder to justify.
Modern security investigations increasingly depend on broad historical context. Threat actors move slowly, compliance frameworks require longer retention windows, and AI-driven analytics demand access to large, diverse datasets. At the same time, organizations must secure sensitive information, enforce governance policies, and prove compliance across increasingly complex environments.
This is why more teams are building security data lakes.
A secure data lake combines low-cost object storage with governance, access controls, encryption, and scalable analytics. Instead of locking telemetry into a single vendor platform, organizations can centralize data in open formats and run multiple analytics engines against it as needs evolve.
The goal is not just to store more data cheaply. It is to build a scalable, compliant foundation for modern security operations.
Understanding Security Data Lakes?
A security data lake is a centralized repository that stores raw and processed security telemetry in scalable object storage such as Amazon S3, Azure Blob Storage, or Google Cloud Storage.
Unlike traditional SIEMs, which often require expensive indexing and tightly coupled compute resources, data lakes separate storage from compute. This allows organizations to retain massive amounts of telemetry at lower cost while analyzing data using different tools and engines.
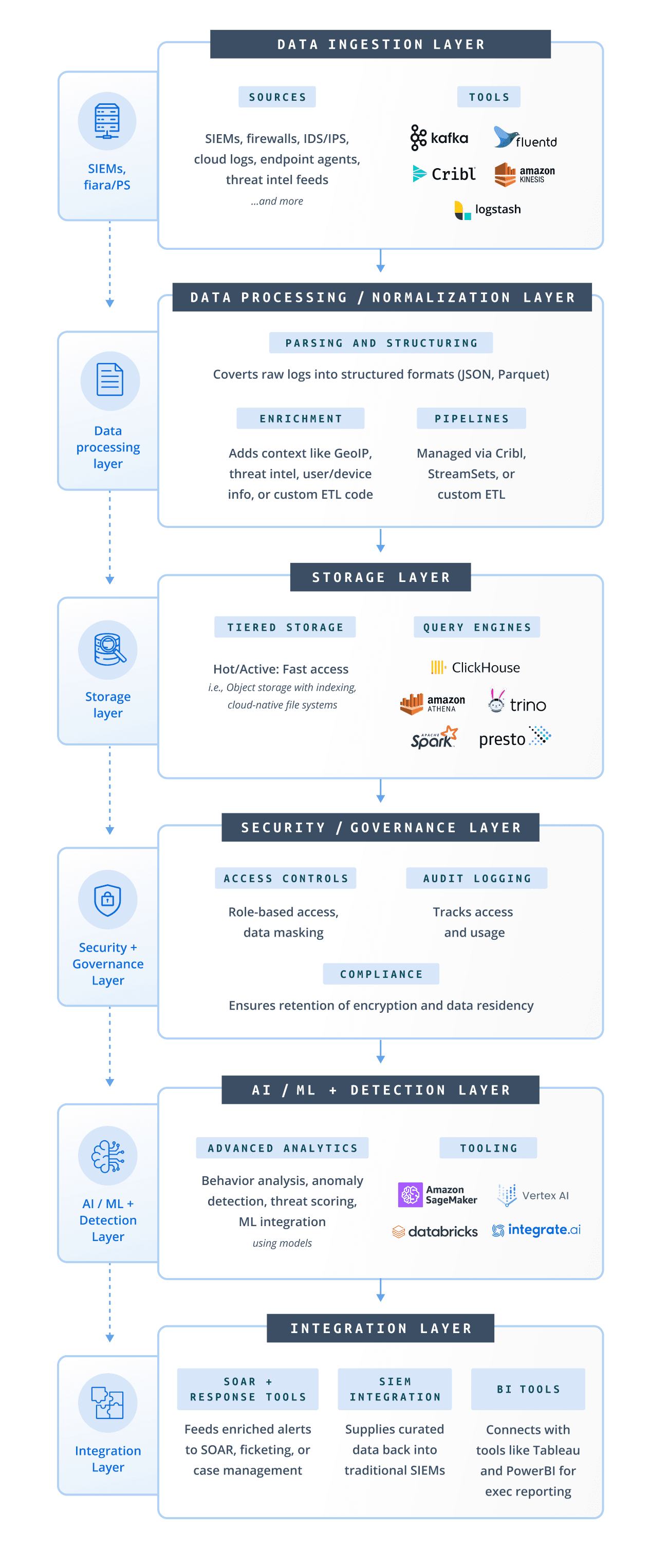
Security data lakes commonly store:
Cloud infrastructure logs
Identity and access events
Endpoint telemetry
SaaS audit logs
DNS and network flow data
Application and container logs
Threat intelligence feeds
Security alerts and case data
The architectural shift matters because telemetry growth is outpacing the economics of legacy systems. Many organizations reduce retention periods or drop high-volume datasets entirely to manage SIEM licensing costs.
That creates blind spots.
A secure data lake solves this by making long-term retention economically practical while preserving flexibility for investigations, compliance, AI, and analytics workloads.
Why organizations are moving toward security data lakes
The biggest driver is scale.
Cloud-native infrastructure, Kubernetes environments, remote work, SaaS adoption, and AI applications generate exponentially more machine data than traditional environments. Security teams need broader visibility, but centralized indexing systems become expensive and operationally difficult at scale.
Security data lakes address several challenges simultaneously:
Data lakes also support evolving security workflows.
Security teams increasingly use multiple tools simultaneously, including SIEMs, detection platforms, threat hunting systems, AI analytics, and lakehouse engines. A centralized data lake allows all of these tools to operate against the same underlying dataset.
Open standards help make this possible.
Frameworks like Open Cybersecurity Schema Framework (OCSF) and Elastic Common Schema (ECS) improve interoperability between tools, simplify normalization, and reduce long-term migration risk.
Data lake vs. lakehouse: what security teams should know
Security teams often encounter both “data lake” and “lakehouse” architectures. While related, they are not identical.
A traditional data lake focuses primarily on scalable storage for raw and semi-structured data using schema-on-read principles.
A lakehouse builds on this by adding capabilities such as:
ACID transactions
Metadata management
Performance optimization
Structured analytics support
Governance enhancements
Technologies like Delta Lake, Apache Iceberg, and Apache Hudi enable lakehouse functionality on top of object storage.
Many organizations ultimately adopt a hybrid approach.
Raw telemetry lands in a data lake, while subsets are optimized into lakehouse tables for analytics and AI workloads.
How to Build Security Data Lakes
Step 1: Define compliance and governance requirements early
The biggest mistake organizations make is treating governance as a later-stage project.
Compliance requirements influence architecture decisions from the beginning, including storage structure, retention policies, encryption strategies, identity models, and data processing pipelines.
Before building the lake, identify:
Which regulations apply
What data types are considered sensitive
Retention requirements by dataset
Geographic residency requirements
Audit evidence expectations
Access control requirements
Data deletion obligations
Different frameworks impose different controls.
Retention strategy is especially important.
Not every dataset needs the same lifecycle policy. Security alerts may require short hot retention with long cold retention, while compliance records may need immutable multi-year storage.
Organizations should also define data ownership early. Every major dataset should have a documented owner responsible for quality, governance, and access approvals.
Step 2: Build a defense-in-depth data lake architecture
A secure data lake is not secured by one tool or one control.
It requires layered protections across storage, identity, networking, pipelines, compute, and monitoring. This is the core principle of defense in depth.
A strong architecture typically includes:
Encryption at rest and in transit
Federated identity and MFA
Role-based access control (RBAC)
Network segmentation
Immutable audit trails
Continuous monitoring
Automated policy enforcement
Data classification and lineage tracking
Encryption and key management
Encryption is foundational for secure data lake design.
Data should always be encrypted:
At rest in object storage
In transit between systems
During processing where applicable
Cloud-native key management systems simplify this process.
Examples include:
AWS KMS
Azure Key Vault
Google Cloud KMS
Tenant-specific keys and automated rotation policies further reduce exposure risk in multi-team or multi-tenant environments.
Identity and access controls
Identity becomes significantly more important in data lake architectures because multiple analytics tools and users access shared datasets.
Strong controls include:
SSO integration
MFA enforcement
Least-privilege RBAC
Short-lived credentials
Conditional access policies
Automated deprovisioning
Granular authorization is equally important.
Modern governance systems such as AWS Lake Formation and Apache Ranger support:
Row-level policies
Column-level restrictions
Attribute-based access controls
Dynamic masking
This becomes critical when datasets contain regulated information like PII or PHI.
Step 3: Secure the ingestion pipeline first
The ingestion layer is one of the most important parts of a secure data lake architecture.
It is also where organizations can reduce both compliance risk and storage costs before data lands in long-term storage.
Best practices include:
Filtering unnecessary telemetry
Masking or tokenizing sensitive data
Normalizing schemas
Enriching metadata
Compressing high-volume logs
Routing data to appropriate storage tiers
Sensitive information should ideally be transformed before long-term retention.
For example:
Replace usernames with unique IDs
Hash IP addresses where appropriate
Remove unnecessary PII fields
Redact secrets and tokens
Doing this at ingestion time is dramatically easier than remediating sensitive data later across petabytes of storage.
This is where vendor-neutral pipeline technologies become valuable.
Cribl Stream allows teams to filter, route, enrich, redact, and normalize telemetry before it reaches downstream systems. Instead of tightly coupling ingestion to one analytics platform, organizations can control data flow independently of storage and compute decisions.
That flexibility becomes increasingly important in hybrid and multi-cloud environments.
Common security data ingestion patterns
Most security data lakes use a combination of ingestion methods.
Cloud-native log exports
Cloud providers can stream telemetry directly into object storage.
Examples include:
AWS CloudTrail
VPC Flow Logs
CloudWatch exports
Azure Monitor
Google Cloud Logging
This approach is scalable and operationally simple.
SaaS audit log collection
Modern enterprises rely heavily on SaaS applications, making SaaS telemetry essential for investigations and compliance.
Common sources include:
Okta
Slack
Salesforce
Zoom
Atlassian
Microsoft 365
GitHub
PagerDuty
Collection methods typically use APIs, serverless polling functions, or aggregation services.
Agent and pipeline collection
Not all environments support direct cloud-native exports.
Organizations often use collectors and pipelines for:
On-prem infrastructure
Edge environments
Kubernetes clusters
Custom applications
Hybrid systems
Popular tools include:
Fluent Bit
Vector
OpenTelemetry collectors
Cribl Stream
Step 4: Implement strong data lake governance
Without governance, data lakes quickly become unusable data swamps.
Governance ensures datasets remain searchable, trustworthy, compliant, and understandable over time.
Core governance capabilities include:
Data cataloging
A catalog provides centralized metadata about datasets, schemas, ownership, and lineage.
Common cataloging technologies include:
Apache Atlas
AWS Glue Data Catalog
Amundsen
DataHub
Cataloging improves discoverability and audit readiness.
Automated classification
Classification systems identify:
PII
PHI
Financial records
Regulated content
Secrets and credentials
Automation matters because manual classification does not scale.
Lineage tracking
Lineage tracks how data moves from ingestion through transformation and analytics.
This helps security and compliance teams answer critical questions such as:
Where did this data originate?
Who modified it?
Which systems accessed it?
Which downstream tools consumed it?
Policy enforcement
Governance policies should automatically block prohibited data flows.
Examples include:
Preventing PII from entering non-compliant regions
Restricting sensitive datasets to approved teams
Blocking unencrypted exports
Preventing public object storage exposure
Strong governance reduces operational risk while improving trust in the platform.
Step 5: Secure compute and analytics workloads
Data is vulnerable during processing, not just during storage.
Security teams often focus heavily on protecting storage buckets while overlooking compute-layer exposure.
Best practices include:
Isolating workloads by function
Using temporary compute where possible
Logging all query activity
Restricting outbound network access
Enforcing workload-level IAM
Monitoring abnormal query behavior
Different workloads often require different environments.
For example:
Lakehouse technologies also improve reliability.
ACID transaction support in technologies like Delta Lake or Apache Iceberg helps prevent corruption, inconsistent reads, and partial writes during concurrent processing.
That matters for both investigations and compliance evidence integrity.
Step 6: Build centralized audit trails and continuous monitoring
Auditability is one of the most important characteristics of a compliant security data lake.
Organizations should be able to answer:
Who accessed which data?
When was it accessed?
What changes occurred?
Which policies changed?
Which datasets moved locations?
Comprehensive audit trails should include:
Query logs
IAM changes
Policy modifications
Bucket access events
Data movement activity
Encryption key activity
Administrative actions
These logs should themselves be:
Immutable
Centrally stored
Access restricted
Retained separately from operational datasets
Continuous monitoring is equally important.
Configuration drift detection
Misconfigured storage buckets remain one of the most common cloud security failures.
Use automated monitoring tools such as:
AWS Config
Azure Policy
GCP Config Connector
Alert on:
Public exposure
Disabled encryption
IAM policy drift
Key rotation failures
Automated compliance evidence
Manual audit preparation wastes enormous operational time.
Automated evidence pipelines can continuously collect:
Access reviews
Encryption status
IAM assignments
Policy snapshots
Audit logs
Retention configurations
This dramatically reduces compliance overhead.
Which security data lake platforms are best?
There is no universal “best” security data lake platform because requirements vary significantly across organizations.
Platform selection typically depends on:
Cloud strategy
Compliance requirements
Existing tooling
Analytics needs
Operational maturity
Cost constraints
Multi-cloud requirements
Most architectures combine several categories of technology.
Vendor-neutral architectures often provide the greatest long-term flexibility because storage, ingestion, and analytics layers can evolve independently.
This is one reason organizations increasingly adopt decoupled telemetry pipelines rather than routing all data directly into a single analytics platform.
Cribl Search is one example of this approach. Instead of requiring full rehydration or centralized indexing, it allows teams to search data directly across cloud object storage and existing environments, helping organizations investigate across distributed datasets without moving all telemetry into one system.
Best practices for building a security data lake
Here is a practical summary of the most important recommendations.
Define compliance and retention requirements before architecture design
Use defense-in-depth security controls across all layers
Encrypt all data at rest and in transit
Implement least-privilege RBAC and MFA everywhere
Mask or tokenize sensitive data during ingestion
Standardize schemas using open frameworks like OCSF
Automate governance, classification, and lineage tracking
Separate storage and compute for scalability and flexibility
Log every query, access event, and administrative action
Continuously monitor for configuration drift and policy violations
Use immutable audit logging for compliance evidence
Prefer vendor-neutral architectures that reduce lock-in
A secure data lake is not simply a storage destination. It is a long-term security data platform that must balance scalability, governance, flexibility, and operational simplicity.
Organizations that treat governance and pipeline design as foundational architectural components — rather than later optimizations — are far more successful at scaling securely.
What is a secure data lake?
A secure data lake is a centralized repository for storing and analyzing large volumes of telemetry while enforcing encryption, access controls, governance, audit logging, and compliance policies.
How do compliance controls work in a data lake?
Compliance controls typically include encryption, RBAC, MFA, audit trails, retention policies, data classification, lineage tracking, and automated governance enforcement.
What are the benefits of a security data lake?
Security data lakes improve retention economics, reduce vendor lock-in, support multiple analytics tools, enable long-term investigations, and centralize governance across large telemetry environments.
What is the difference between RBAC and attribute-based access controls?
RBAC assigns permissions based on roles, while attribute-based access control uses dynamic policies tied to user, dataset, or environmental attributes.
Why are open schemas important in security data lakes?
Open schemas such as OCSF improve interoperability between tools, simplify normalization, and reduce long-term migration complexity.
Should organizations use cloud, on-premises, or hybrid data lakes?
Cloud deployments provide scalability and operational simplicity. On-premises deployments may support stricter sovereignty requirements. Hybrid architectures are common for organizations balancing both flexibility and regulatory obligations.





