

In this post, we’ll compare the performance-price ratio of compute-optimized AWS instances built on: Intel, AMD, and Graviton2 (ARM64). Let’s start with the results. TL;DR Graviton2 based instances offer great performance-price benefits, except on some workloads …
The following table summarizes our findings about which instances had the best performance-price scores per scenario:
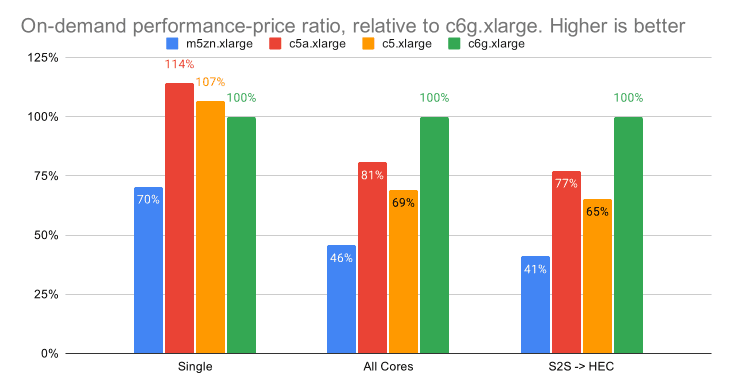
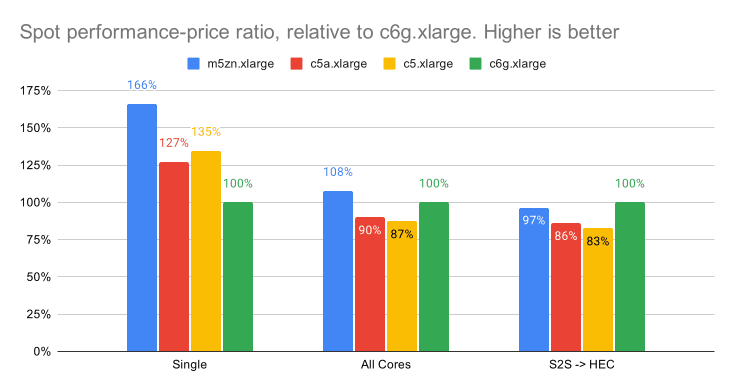
The charts below show the performance-price ratio relative to Graviton2 instances, where a higher score is better. AWS offers a variety of ways to purchase these instances, this post focuses on performance-price ratios based on On-Demand and Spot prices.
Discussion
Graviton2 (c6g) instances built on ARM64 architecture offer one physical core for each vCPU, while in Intel and AMD instances a vCPU is mapped to one hyperthread. AWS does not publish the clock speed on it’s Graviton2 instances, but our estimation is that they’re running at ~30% lower clock speeds than the Intel/AMD (c5/a) instances. Our findings are:
When all the CPU resources are fully utilized, Graviton2 instances offer 40% and 23% better performance-price than the Intel (c5) and AMD (c5a) instances, respectively.
On single-thread performance, on-demand AMD (c5a) instances offer 14% and 6% better performance-price than Graviton2 (c6g) and Intel (c5), respectively.
The high-clocked Intel (m5zn) instances, when bought in the Spot market, offer 65% and 27% better performance-price vs Graviton2 (c6g) and Intel/AMD (c5/a)
When all the CPU resources are fully utilized and Spot instances are used, the higher-clocked Intel (m5zn) instances offer 8% and 20% better performance-price vs. Graviton2 (c6g) and Intel/AMD (c5/a). As you can see in the charts above, this is one of the tightest performance-price ranges – pointing to the likelihood that AWS’ Spot pricing reflects the full compute power of these instances.
Given that Graviton2 instances have better performance-price when all cores are at 100% utilization, and worse performance-price at single-core utilization, it stands to reason that there is a breakeven point between the two. Our current estimation is that this breakeven point is ~70% utilization, meaning that benefits become apparent/relevant at CPU utilization rates above 70%.
Methodology
One of the hardest things about benchmarking is determining representative workloads to test with. For this post, we’ve come up with two types of workload profiles that we’d want to stress the systems under:
Single-thread – workloads cannot be well parallelized, e.g., processing one stream of event data in strict order
Overall system – workloads are highly parallelized, e.g., process N streams of event data in an unordered manner.
In addition to workload type, we need to consider the pricing model used to purchase the compute instances. We focus on On-Demand and Spot pricing models. (Reserved instances generally offer a constant discount across all instance types, and since we’re interested in relative performance-price ratios, the results would be the same as On-Demand.)
We chose to use the following instance types for this test, and as of this writing, these were their respective prices in the US-WEST-2 (Oregon) region.
Measurements
We tested the following three scenarios:
Data parsing and processing to saturate 1 core
Data parsing and processing to saturate all cores
Data parsing, processing, and sending out to saturate all cores
All data is downloaded and sent to a Cribl Stream SplunkTCP listener via the loopback interface. The test dataset is a ~6GB capture sent on a loop for 15 minutes. Next, we record the average throughput, as reported by Stream over the past-15-minutes window.
If you care about all things performance, we’re hiring! Please check out our Jobs page.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.




