

Here at Cribl, we are nearly always asked, “How can you help me justify the purchase of your software?” Most customers realize a return on investment using two or more of the approaches below.
Reduce Data Volume
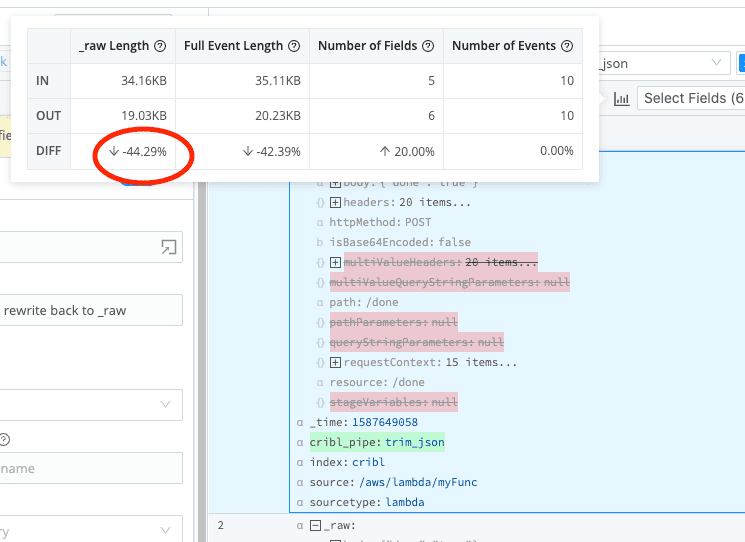
One form of cost reduction starts with volume reduction. Cribl Stream customers reduce data volumes by 25% or more. You can filter any event based on meta-information or by content, or both. Data reduction comes in two primary forms: (1) reducing the overall number of events, and (2) reducing the size of the events themselves.
Reducing event count is done by dropping, sampling, or suppressing events.
Dropping events – 100% of this type of data is discarded
Sampling events – 1 out of N of this type of data is delivered, the rest are discarded
Dynamic sampling – low volume data of this type is delivered at 100%, but as volume increases the % of dropped data increases.
Suppression – no more than N copies of this type of data is delivered per unit of time
With each of these methods, the administrator specifies the matching criteria to be used; meta information such as hostname, source, sourcetype, log level, in combination with content extracted from the events themselves.
Reducing volume per event is done by parsing the original event, then removing unnecessary and unwanted fields. Remove parts of an event that are overly verbose. In addition, parsed data may be translated to a more efficient format. (XML to JSON, for example.) In this case, you’re still sending one event out for each event in – but the byte count might be 20-75% reduced, depending on the dataset.
Now that we’ve filtered the data and reduced volume, let’s dig into how that provides ROI. Volume-based cost reduction using Cribl Stream is achieved in a variety of ways:
License reduction: This applies to commercial log analysis tools, whether you’re charged by events per second, by daily ingest volume, by compute cycles, by node count, or by volume of data being retained. You might not reduce your license costs immediately, but with data volumes growing year over year you may be able to defer additional spend.
Infrastructure costs: For non-SaaS analysis tools, reduced volume can mean reduced infrastructure costs for compute, disk, and memory.
SaaS charges: For SaaS-based analysis solutions, reducing volume delivered can either reduce ingest costs or allow you to increase retention period while maintaining the same overall storage sizing. Data Egress charges can be dramatically reduced as well.
Optimal use: By reducing volume, leverage capacity for additional data sources that are not in your analysis tool today. You’ll get more benefits out of the investment you’ve already made.
Reduce Storage and Infrastructure Costs
But wait! You say you have strict compliance requirements? You say you can’t reduce your data volume because you need to keep data for 2+ years and you’re not allowed to throw any of it away? Dear reader, you’ll find you’re not alone.
You can save money by separating your system of retention from your systems of analysis (like Splunk or Elastic).
You begin by sending a full-fidelity copy of your data, at pennies on the dollar, to a solution such as AWS S3, MinIO object storage, or existing on-prem storage – archiving the original data in a vendor neutral format, compressed at ratios of 10-to-1. Side benefit: the vendor-neutral storage future-proofs your data for future analysis approaches.
With that in place, you can be even more aggressive about the volume reduction approaches discussed above. More importantly you may also be able reduce retention periods (and hence infrastructure costs) in your log analysis system.
As an example, we worked with a customer whose log analysis environment was deployed in EC2, and who had a requirement to retain all data for at least 13 months. Typically, they only looked at data older than one month if they were investigating a specific security event, or going through an audit. At 8 TB/day ingest, the cost of storing data between 1 and 13 months of age was approximately $1.4M US. Alternatively, the cost to store that same data at 10-to-1 compression in S3 was under $100k. By reducing the retention in their system of analysis to 1 month, they were able to save 93% on their storage costs.
And of course, Cribl provides a GUI-based method to re-ingest that data, filtered and redirected, on an as-needed basis.
Other ROI Scenarios
There are more ways to save, and not all savings are directly tied to what you spend.
Simplifying Management Tasks:
Perhaps your current log analysis solution has a code-based way for achieving several of the benefits listed here. Do they require programming, or manual editing of .conf files? Do you have people proficient in those languages? What percentage of your new hires will be able to support that filtering approach? Cribl Stream’s management UI and coding-free interface allow you to lower the bar in terms of supporting, troubleshooting the streams processing environment.
Streamlining Data Ingestion:
By supporting the receiving protocols necessary for certain data sources, retire infrastructure devices that had been necessary in the past – send the data directly to Cribl Stream instead. This reduces costs for licensing and for compute infrastructure, as well as operational costs tied to supporting an otherwise more complex environment. For example, you could retire commercially supported syslog servers by sending the data directly to Cribl Stream instead or retire VMs that were stood up just to accept/parse/relay data to analysis destinations.
Speeding Up Analysis:
By enriching data at the time of ingestion rather than at search time, results are returned more quickly and efficiently. Pre-enriched data can be orders of magnitude more performant and use less processing load on the search environment. Of course, index-time enrichment is the only option for systems of analysis that cannot do their own search-time enrichment.
Accelerated Adoption:
By facilitating rapid adoption of new technologies and reduced timelines when moving to new technologies, you reduce operating expenses for new initiatives. When compared to other solutions, Cribl Stream allows you to rapidly adopt Cloud-first technologies as both data sources and as destinations.
Avoiding Penalties:
By encrypting sensitive data (PII), you can avoid penalties that might have been imposed by regulators such as GDPR or CCPA. Whereas alternate solutions might require that you send unencrypted data to one destination and masked data to another destination, with Cribl Stream you can avoid the performance and license penalties associated with this approach.
Wow, that’s a lot of benefit!
If you’d like to talk to us about any of this, please drop an email to sales@cribl.io – we’re here to help. You can also try out these approaches first hand by using one of our interactive sandbox environments. For an overview of Cribl Stream (including volume reduction) try our Fundamentals sandbox. To learn how to route data to S3, try our Affordable Log Storage sandbox.





