

We hear it often—data volumes are growing at a 28% compound annual growth rate (CAGR) year over year, and organizations struggle to manage it all. With no additional money in their budgets, they can’t afford to store more and more data in their SIEM, which in most cases means being uncompliant or, worse, not having older data readily available in the case of a recently discovered breach.
I’ve repeatedly heard that the data they have archived is practically inaccessible. This is not so reassuring when you’re in a pressure cooker, with a security incident unfolding and your team waiting for your archived data to rehydrate so that you can search it and see if it contains anything worthwhile in your incident response process.
What if I told you there was a better way? A way to store large volumes of data, stay on budget, ensure compliance, and not have to wait for data to rehydrate? What if you could have your cake and eat it too?
I’m excited to introduce you to Cribl Lake and show how, along with Cribl Stream and Cribl Search, you can have a scalable, cost-effective archive of all your security data (and then some) immediately accessible when you need it!
SIEMs Are Not Long-Term Storage Solutions
Let’s face it: SIEMs are excellent at what they do but not designed for long-term storage. They’re great for real-time analysis, collecting, correlating, and analyzing data to detect and respond to security incidents. However, when it comes to long-term storage, they can burn a hole in your budget faster than a data breach – charging premium per GB fees on raw data volumes while storing that data compressed on low-cost cold-tiered solutions.
Also, the rehydration process is one of the most significant pain points for many of the customers I talk to. First, they have to submit a ticket to get access. We’ve heard of some SIEMs requiring them to wait anywhere from 2-4 weeks before the data can be queried! Even though some SIEM vendors allow you to store your data in your S3 bucket, the data isn’t readily accessible. You still need to trigger a job to move the data back into the SIEM so that you can query it – at another cost to you.
Cribl Lake to the Rescue
If you’re reading this, there’s a good chance you already know about Cribl Stream — Cribl’s observability pipeline designed to handle real-time processing of your logs, metrics, and traces. You might even use it to reduce the log volumes you’re sending to your SIEM today.
Using Cribl Stream to route your data to Cribl Lake can drastically reduce your storage costs while retaining the ability to rehydrate and analyze the data if needed. Again, it’s like having your cake and eating it, too—only the cake is made of data and doesn’t go stale.
Cribl Lake lowers your overall storage costs and ensures that your data is easily accessible using tools like Cribl Search. Search gives you fast access to all your archived data without any delays. You can take back control of your storage costs and access to your data, giving you a sense of control and confidence in your data archival strategy.
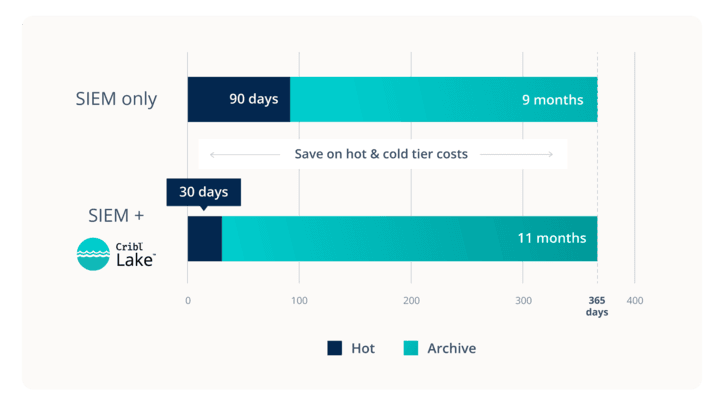
Reduce Hot/warm SIEM Storage Tier Costs With Cribl Lake
With Cribl Lake, your archived data is always accessible without delay or rehydration times. Rather than keeping data in a warm tier or longer in the hot tier so it’s accessible, Cribl Lake and Search can return your results within seconds. You can always send your search results back into Cribl Stream if you’d like to have older data back in your SIEM’s hot tier for investigation.
How It Works
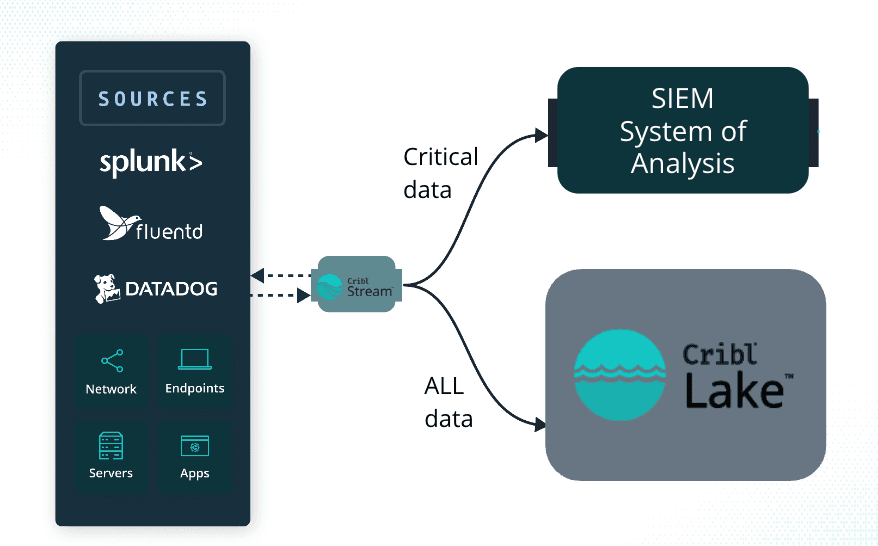
Cribl Stream is your universal receiver, allowing you to collect from any data source. Stream can further reduce noise and volume, opening up headroom for your SIEM ingestion. Next, send a copy of all events into one or more Cribl Lake Datasets, and that’s it!
If you’re already using Stream, you need to take three easy steps:
Create a Dataset in Cribl Lake and set your retention period. A dataset is akin to an index in your SIEM.
Within Stream, add a new Cribl Lake Destination mapped to your newly created Dataset.
Use QuickConnect or a Data Route to send your security data into your Lake Dataset for long-term storage.
Accessibility Without the Wait
Your data is always immediately accessible in Cribl Lake – no more waiting for rehydration jobs to complete!
With Stream, you can replay data from Lake to any solution for investigation or analysis. Using Cribl Lake as a Source within Stream, you can specify a time range within your archive to bring back into Stream. As you’ve stored a full-fidelity copy in Lake, you can use a pipeline to get the data back into the correct format before sending it to your SIEM for review. In essence, you are rehydrating your data, but without the delays. Data is always available with millisecond latency, allowing you to get back to what matters most — getting data out of the archive to speed up investigations.
If you want to review the log events before replaying them, Cribl Search can help. Search has full access to all your datasets in Lake. With its rich query language, you can quickly sift through terabytes of data to find the events you’re looking for. Using Search’s send operator, you can forward these events to Stream and then into your SIEM. It saves you time and reduces costs by not having to ingest more data than necessary.

Get Started With Cribl Lake
By using Cribl Stream to store a copy of security data in Cribl Lake, you can significantly lower your storage costs and improve data accessibility. The ease of implementing this solution, with the support of Cribl Stream and Search, provides relief from the complexities of data management, enabling you to optimize your security operations without breaking the bank.
So, why not give your SIEM a break and let Cribl handle the heavy lifting? Get started with a free account on Cribl.Cloud today!




