
Remember the first time you were at a wedding, or a party and you learned about dances like The Electric Slide? You know, those dances with a clear structure and steps to follow, which were a huge help to someone who was slightly challenged on the dance floor, like me? All you had to do was learn a few simple steps, and you could hang with even the best dancers. I’m not just being self-deprecating about my dancing skills; it’s about how applying some structure and repeatable steps to most things can make them easy.
When using Cribl Stream, approaching observability pipelines like a dance can help create a more systematic approach. Although the natural inclination may be to go left, center, and right to progress data, going left, right, and then center can actually be more beneficial. This is where a staff observability engineer can shine as an internal consultant. By understanding the sources teams need to onboard and the desired outcomes (such as cost control, data enrichment, or storing raw data in low-cost object storage), they can build the most reliable routing pipelines from the center outward. This approach ensures a smoother flow of data and optimal outcomes for the organization.
The Breakdown
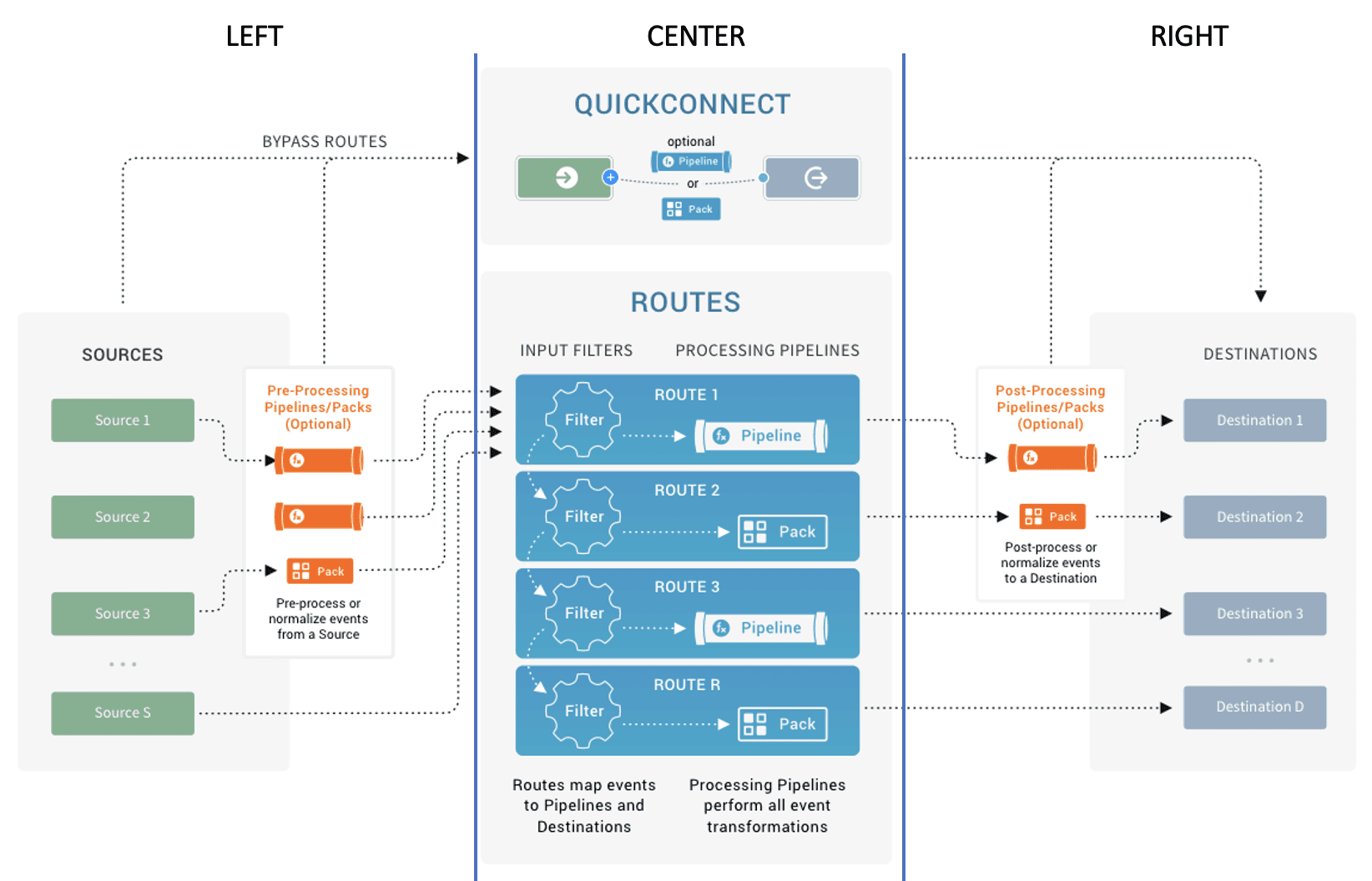
Let me break it down for you (also something you would probably say before busting a move) in more detail. As a visual aid for this discussion, let’s break the Cribl Architecture diagram below into three sections: Left, Center, and Right.
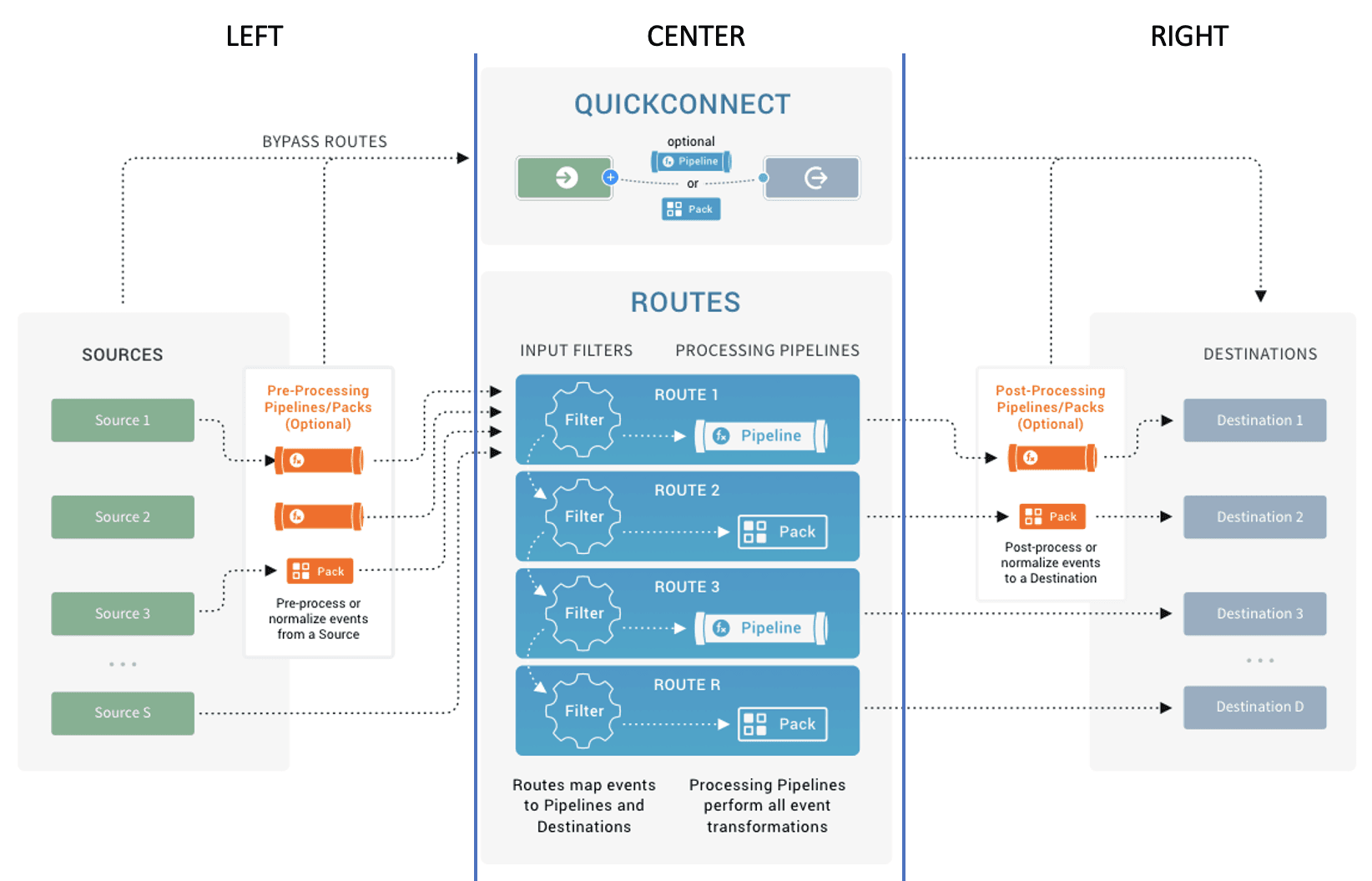
To the Left
For the first step in our “dance” we are going to focus on the LEFT side of the diagram above: our data sources. We start here, because, let’s face it, it’s all about the data. Before we start configuring anything in Stream, let’s try to answer a few questions first:
What data sources am I currently sending to my SIEM, system of analysis, data lake, etc…?
Are there any data sources that are particularly troublesome (size, format, lack of context, etc…)? I like to call these the “big rocks”. It’s always a good idea to start with these to get some big value early.
What is the best method for getting each data source into Cribl Stream (existing agent, direct to Stream, Cribl Edge)?
Can Stream provide value in how that data is being ingested? Can any syslog or WEF infrastructure be retired or repurposed? Is Cribl Edge a good option?
You get the idea. Once there is an understanding of where the data is coming from and how you can ingest it into Stream, you can start to configure your sources and get a look at the data.
To the Right
For step two, we focus on the RIGHT side of the diagram: our destinations. Each destination may have requirements which will control what we are able to do in step three. That is why this part goes second. There are a few things to think about before you send data to a SIEM, data lake, or other destination:
Can the data going to the destination be optimized without breaking anything (parsing, dashboards, reports, alerting, etc…)?
What is the best method of sending data to a destination? Sometimes there are multiple ways to do this.
What is the best format for the data (JSON, CSV, key/value pairs)?
Is there any context that could be added to the data that would be helpful in routing, processing, or searching the data?
Can we convert logs to metrics for more performant searching and lower storage requirements?
Do the consumers of the data in different systems have specific requirements?
Overall, it’s a good practice to have an idea of your tolerance for change downstream before using Cribl Stream to transform and route your data.
To the Center
For the last step in our “dance,” we focus on the CENTER of our diagram: our routes and pipelines. This is where you use the control and choice that Stream provides to route, optimize, and/or transform your data, getting the right data to the right destination in the right format.
Just like with the plumbing in your house, you want to put the pipes in before you start the flow of water. In Stream, you will want to focus on your pipelines before you turn on the flow of data. You have your sources configured from step one, so you can capture a sample of your data. And you also know where that data is going and what the requirements are for each destination. So, now you can build a pipeline to optimize and/or transform your data appropriately. But before you start from scratch, you will want to check our Packs Dispensary to see if there is an existing pack to help you out. Packs are great starting points so you don’t have to reinvent the wheel, and they are completely customizable so you can make them fit your specific needs.
Once you have your pipelines in order, it’s time to start the flow of data. Using routes, you can send your data where it needs to go and pass it through the pipeline that you just built or found in the Packs Dispensary. Start slowly though! Send a small amount of data, just to make sure it lands properly and things like parsing or dashboards don’t break at the destination. Once you see that things look good, fire away!
Wrap up on the 3 Step Dance
Hopefully, you find this approach helpful, and you can start busting out your sick moves for your co-workers or even on the Cribl Community Slack. Check out some of the links below to learn more about Cribl Stream!






