

Since joining Cribl in July, I’ve had frequent conversations with Federal teams about observability data they collect from networks and systems, and how they use and retain this data in their SIEM tool(s). With the introduction of Executive Order 14028 – Improving the Nation’s Cybersecurity and Memorandum M-21-31 Federal Agencies, within a year of the Memo, must:
Ensure each event log contains the appropriate Minimum Logging Data, like Source and Destination IPs
Meet passive DNS logging requirements
Retain this data (generally) for 12 months in Active Storage
Ensure consistent timestamps across event logs
Be able to effectively forward events to SIEMs, bulk storage, and other analytical workflows and services
Provide logs/data to CISA and/or the FBI as needed for threat investigations
Implement an Enterprise Log Manager for centralized, agency component-level aggregation
Beyond this immediate requirement, Federal Agencies will later need to meet additional requirements. Cribl Stream’s ability to route, shape, reduce, enrich, and replay data can play an invaluable role for Federal Agencies. Over several blogs, we will walk through the power that we bring to these requirements. First, I’ll touch on the Routing and Replay capabilities of Stream. An old debate between two security schools of thought comes to mind.
Cribl On-Demand Webinar:
Cribl Stream for Federal Agencies: Addressing Requirements for Log Management, Maturity, and Retention
The Biden Administration’s May 2021 Cybersecurity Executive Order (and the follow-on guidance in OMB M-21-31) emphasizes cybersecurity as a national priority and lays out new requirements for logging maturity and retention. Wondering how your agency will comply with the EO? Cribl Stream can help.
One is that all data (every event and field) is critical to security and should be sent to the SIEM and retained there (for as long as needed). While on the surface this seems simplest and best, it dramatically increases the costs of a SIEM (licensing, people, and infrastructure) and leads to performance challenges due to the need to search a ton of data (only some of which is needed). This can even negatively affect the security posture.
The other school of thought is to classify data into different categories:
Data with value for monitoring and threat detection (aka “SIEM-worthy”) which should be sent to the SIEM and/or other security tools.
Data with little or no value for monitoring and threat detection which should be retained in lower-cost storage, but can be easily accessed or used when it needs to be reviewed for forensic or historic needs.
With this approach, we separate the wheat from the chaff and get the most value out of our SIEM tool, controlling costs and keeping performance optimal. While no size fits all, we find this approach achieves the best results when the budget is a challenge. By using Stream to implement this approach with an effective Routing, Filtering, and Replay strategy we can help our customers meet their retention requirements, maintain or improve their security posture, and manage cost-effectively. If all data must go to the SIEM regardless, this classification can be useful to place data in separate indexes (or different SIEMs altogether) to improve performance and offer more retention policy flexibility.
Classification (Example)
So “Let’s DO THIS” in Cribl Stream and use DNS Logs (from Zeek) as an example (after all, Passive DNS Logging is mandated). I’m also going to classify DNS logs as I have seen at customers:
Low Value DNS Log events: “East-West” traffic that never leaves my network
Low Value DNS Log events: Name Resolution Queries to “Top-1K” sites
High Value DNS Log events: “High-Risk” queries NOT above
We will then use the classification to route all events for storage in S3 (using the event classification to partition the events) and also route only High-Value events in our SIEM. Finally, we show how events in Amazon S3 (long-term storage) can be searched or replayed. There are certainly other ways of identifying “notable events” including matching to known threats, looking for base 64 encoded data exfiltration, etc, but this is a simple and common way to get the discussion started.
Since we want to classify our data and sort out our “Wheat”, I’ll walk through how to do this in Stream. Our DNS log data has 3 fields we will use: the client making the DNS request in id_orig_h, the hostname being resolved in query, and the DNS server responding in the field id_resp_h. We will create a pipeline to add the classification of our DNS log using 3 easy functions. In a Stream Worker Group, In the menu, navigate to “Processing/Pipelines→Pipelines” and click “+Pipeline”. In the newly created pipeline, we create 3 functions. Click “+Function” and select “Regex Extract” to break out the domain from the query (for example extract the domain of “google.com” from “finance.google.com”.
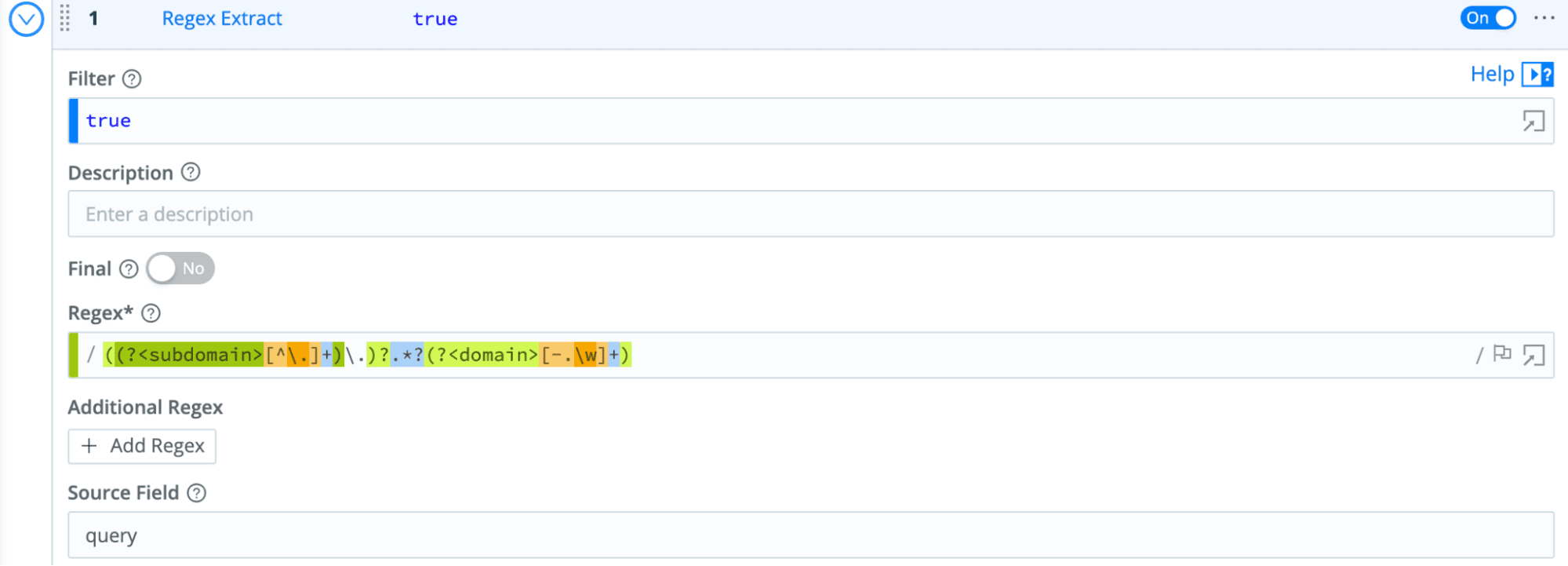
Next, we simply add a lookup of the domain against a list of Top Sites (in my case, I used a list of top domains from Cisco Umbrella and grabbed the top 1000 of them). For this, we add a second function and choose “Lookup” and use the domain field to lookup the Rank of the domain (or if not found, set it to 0 as a default).
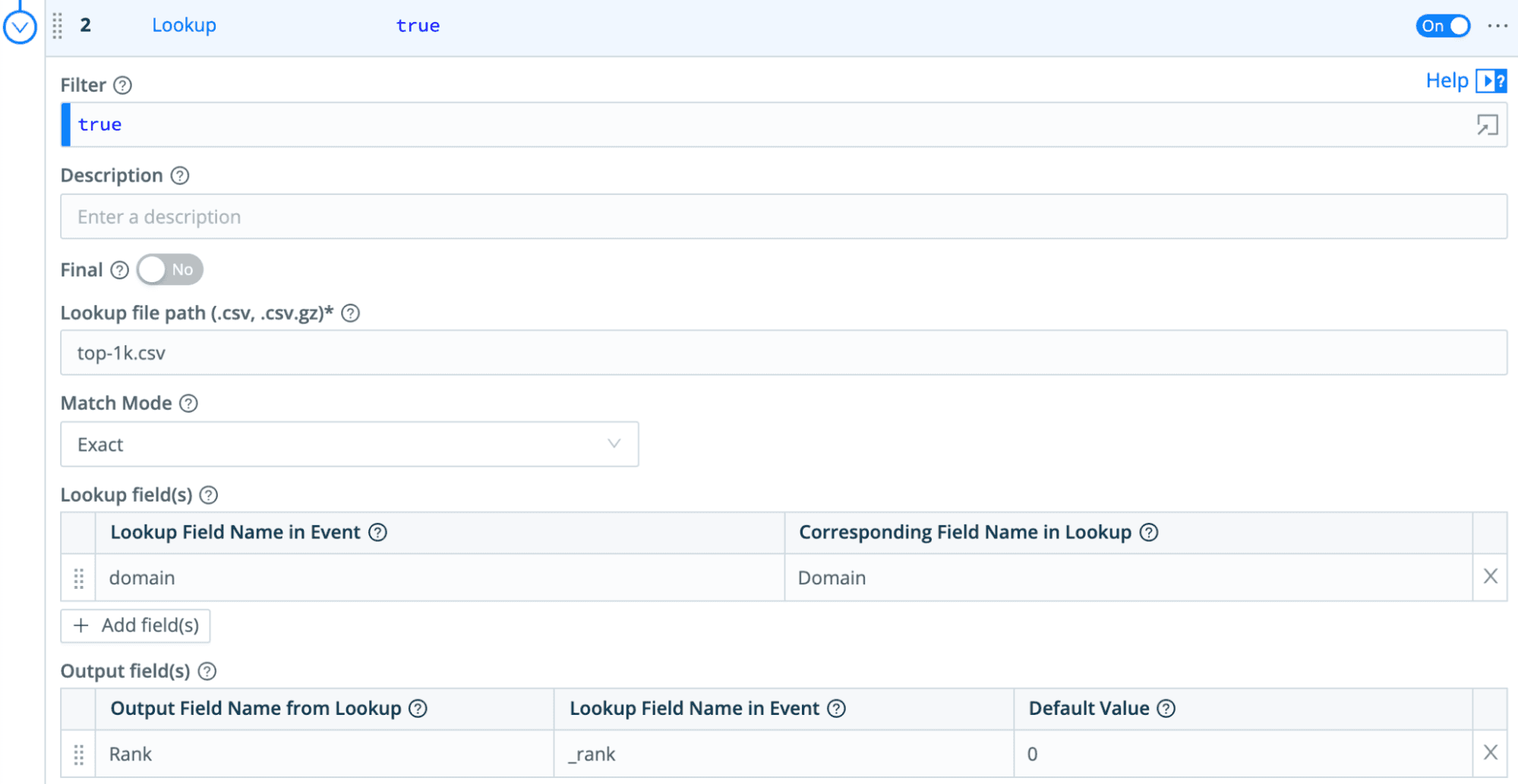
Finally, we add an “Eval” function to figure out the right DNS Risk_Class:
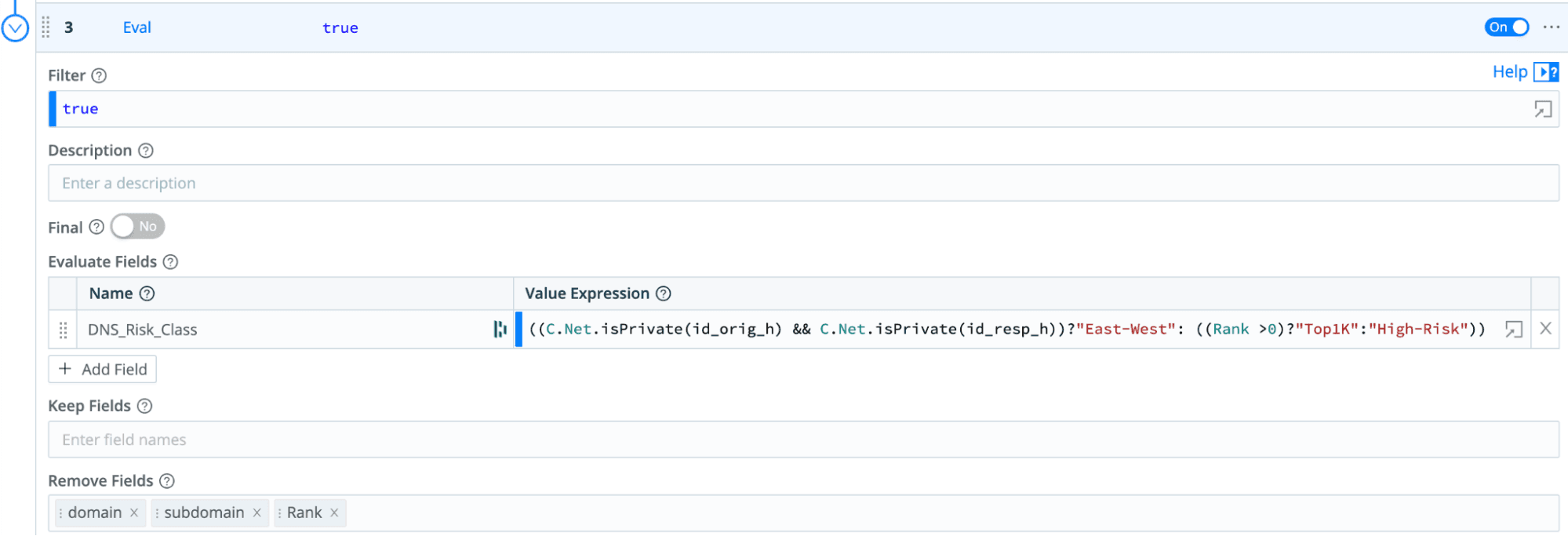
Note how we are using a built-in Cribl Network Function C.Net.isPrivate() to check if both the hosts are in Private IP addresses, but we could also easily match on CIDR block using C.Net.cidrMatch() or do a lookups in a allowlist.
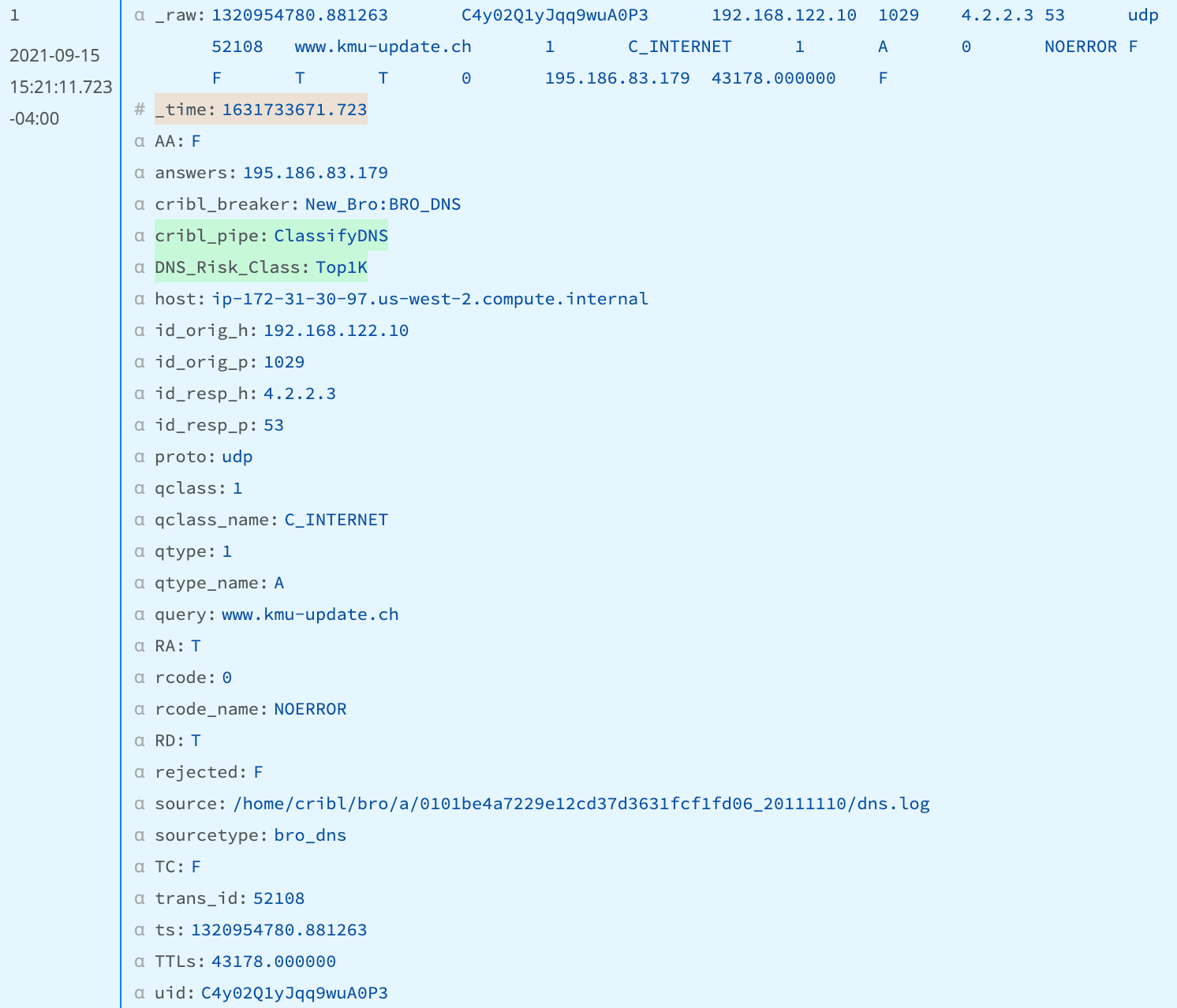
We can see everything is working by looking at the OUT of a Sample DNS Capture and see the DNS_Risk_Class has been added:
Routing by Classification (Example)
Now that we have DNS data classified (for those following the analogy, our “Wheat” is our “High-Risk”, the “Chaff” is either “Top1K” or “East-West”), we can easily use this field to route to one or more destinations as needed. In the below example, we simply route “High-Risk” to Splunk and all DNS logs to an S3 (API Compatible) destination for retention.
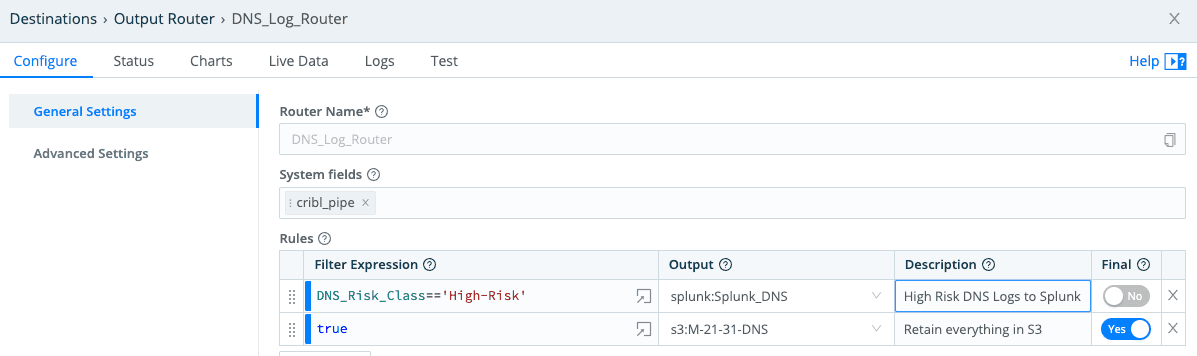
Now that we have our “High-Risk” data in our SIEM, how do we meet the need to be able to readily access all the rest? With Stream the answer is straightforward. First, partition (or organize) your data into directories that let you efficiently identify the data that meets your needs (for example, an incident response workflow that requires analyzing data for a certain date range from the top1K sites in addition to the High-Risk data). Second, we must be able to quickly retrieve that data and maybe even filter it based on any field values of interest.
Let’s look at how Stream enables you to organize your data based as it is written to a system of retention like S3. Stream offers tremendous flexibility for our customers through the use of JavaScript Expressions in defining how to organize data (we call the the “Partitioning Expression”. What this means is that you can use information from the log event itself to define where it is stored. For this example, we will use the sourcetype of the event (in this case DNS), the time of the event, and the Risk Classification we assigned to determine what directory we will place the data in. We could easily add other fields like the DNS query, or even do a Geo_IP lookup of the client or responding DNS Server and include the country as part of the structure. Back to our sample, we simply use the following Partitioning Expression leveraging the strftime() Cribl Time function:

Now everything is structured under ‘DNS’ organized by Year, Month, Day, Hour, and Risk Classification.
Using our Bulk/Active Storage
So, did we just pile up all our “Chaff” or can we use it, and importantly, meet our goal for “Active Storage” (defined as “stored in a manner that facilitates frequent use and ease of access”). By leveraging S3 (or Azure Blob Storage etc) as a system of retention, we are able to easily access the data and are free to use any tool that best fits our needs.Our data certainly is easy to access – we can directly access it using S3 – for example we can use a browser to get all dns log events from Jan 21, 2022 between 4:00 and 4:59:59: https://<bucket_uri>/M2131-Storage/DNS/2022/01/21/04/Top1K/
We can use a Stream S3 Collector to Replay the data using a path like:

With the Stream Collector, we can add further filtering down to the logs we want based on matching source IP, responder IP, query used, etc., and route/shape the data to send anywhere Stream supports (including Splunk, Elastic, ExaBeam, Sumo Logic Grafana). We can also leverage this to meet data requests from CISA or the FBI via TCP, HTTP or other means and ensure we provide it in the requested (key-value) format.
Wrapping Up
I truly feel blessed to be in a position to work with customers and to share thoughts both on effective approaches to their problems and how Cribl Stream can help bring their solutions to fruition. In this article, I have shown how Stream can enable our Federal (and other) customers to rethink how they can sort out what data they really want to always have in their SIEM or other analytics tool, and how they can effectively manage the data volumes and requirements as mandated for Federal Agencies in M-21-31. This approach demonstrates a specific case, but applies more broadly to:
Effectively managing large volumes of log data and retaining that data
Event Forwarding
Meeting data requests from from CISA and/or the FBI
Routing and Aggregating data from Component-level to Agency Level
Expect to hear more about other ways that Stream can be leveraged to meet the needs of the Public Sector and M-21-31 including how to standardize/normalize timestamps, and how to enrich data both for Security and for assigning tags to help Agencies aggregate across components/organizations.
Ready to get started with Cribl Stream? There are 3 easy ways to start today: sign-up today for Cribl Stream at Cribl.Cloud, Play (and Learn) with one of our Cribl Sandboxes, or Download Stream now.





