

This is a short blog post about a pattern that we’ve observed more frequently among some of the large enterprises: the use of AWS S3 as both an observability lake and a data bus.
AWS S3’s simple API, ubiquitous language support, unmatched reliability and durability, retention options, and numerous pricing plans have made it the de facto standard for storing massive amounts of data. Observability data is one of the most voluminous and fastest growing data sources, so it should come as no surprise that S3 is a compelling destination for such data.
We’re observing a pattern among large enterprises: using AWS S3 as a data bus. The implementation of this pattern comes in two flavors:
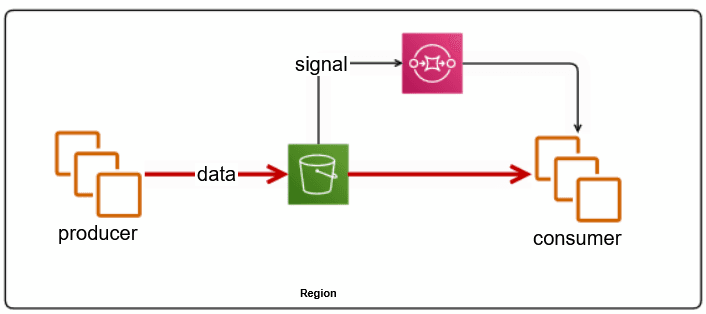
AWS S3 + SQS + Data Client
AWS S3 + SNS + (SQS + Data Client)+
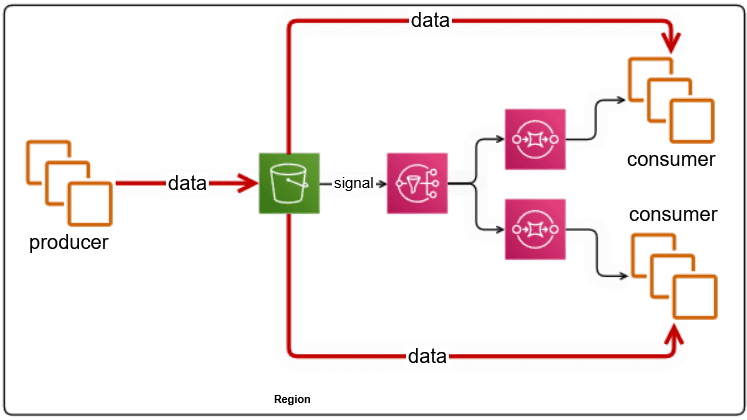
This pattern is widely adopted among customers with multiple AWS accounts, where the problem being solved is centralization of logs and metrics into one account – let’s call this the centralized log account.
An observability pipeline or a log analytics solution runs in the centralized log account, where it monitors the SQS for data to become available in the S3 bucket, processes it, and then deletes/consumes the SQS message.
The S3 bucket needs to be configured to (a) trigger notifications when new objects are stored, and (b) have a retention policy to either age out objects, or move them to cheaper storage layers – we’ve commonly seen 24h to 7d retention.
In this pattern, S3 provides a reliable and durable staging ground for the data, while SQS provides notifications and delivery guarantees to the clients. The latency in data delivery is dominated by the file batch size – i.e., how long does the producer batch data before sending to S3. For example, a producer that generates 10GB/day can create a 7MB raw file by batching data for 1 minute. Our experiments show that S3 -> SQS notification latency is sub-second, and so is SQS -> Client notification.
What About Costs?
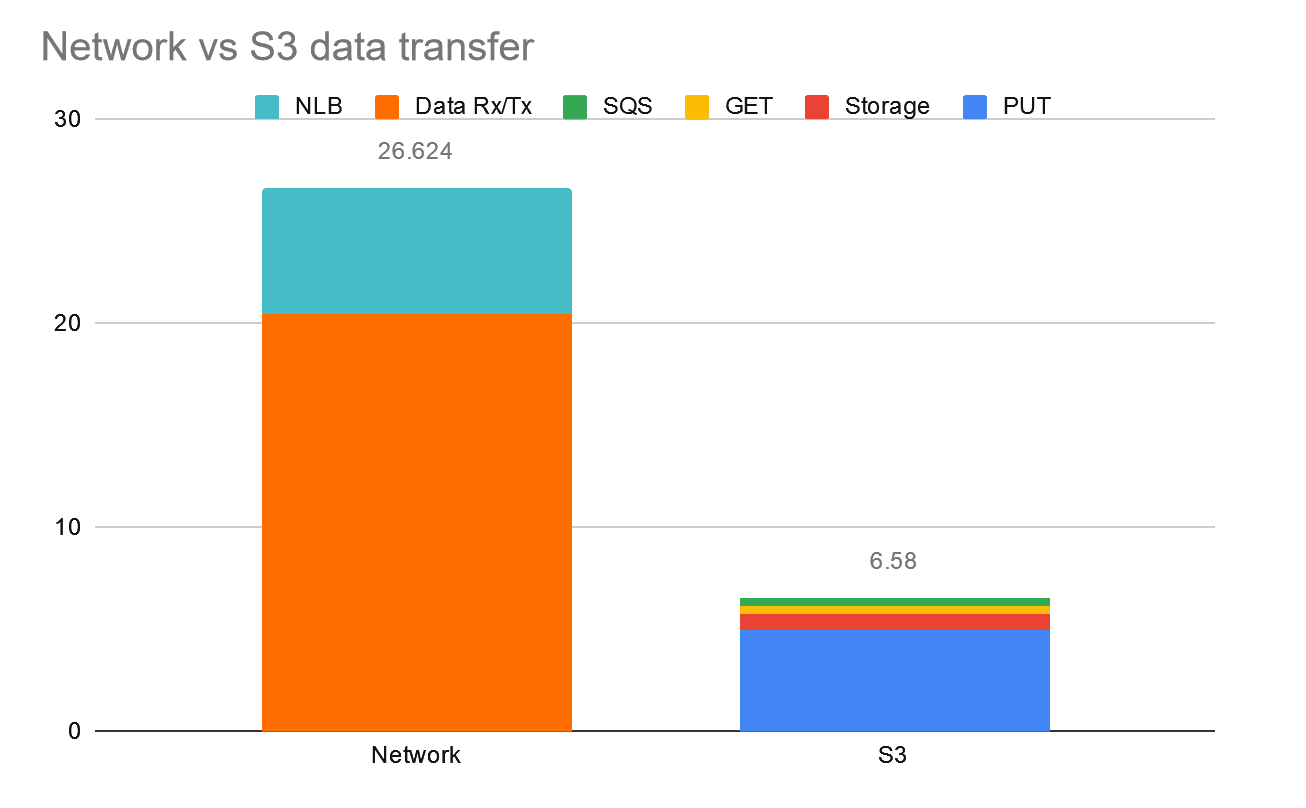
This mode of data transfer is very cost effective (75% cheaper than cross-AMZN transfer), because there are no data transfer charges to/from S3 within the same AWS Region. Let’s look at an example of transferring 1TB of data using either of the following methods:
Via S3 as 1 million x 1MB files, with a 24h retention period.
Direct networking to a cross-AMZN-destination service, exposed via an NLB.
Delivery Guarantees and Availability?
S3 offers read-after-write consistency, guaranteeing that deposited data (for which a notification is sent out) is available for consumption. SQS offers at-least-once delivery guarantees, leaving it up to the clients to minimize (or eliminate) data duplication.
AWS Graviton Ready
Cribl is also proud to announce we have achieved the AWS Graviton Ready designation, part of the Amazon Web Services, Inc. (AWS) Service Ready Program. Read more about the program on the Amazon Partner Network blog.
What About Being Able to Replay Old Data?
Having the raw data staged in a durable, reliable, and cost-effective storage system gives users the ability to replay some or all the stored data. This capability is very handy in case of any downstream consumer system failures, or more commonly, to facilitate populating new systems.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







