

The ability to collect from myriad sources, send to just as many destinations, and transform your machine data in-between is extremely useful. When evaluating observability pipeline tools, though, something else to keep in mind is the ability to store and replay your raw data at a later date.
Think about it: when (not if) there is a data breach, you’ll need access to the raw data to analyze it in a new way that you haven’t been (otherwise you would have caught the breach sooner). Or if you need to prove compliance to certain security standards back to a certain date, you’re going to want your raw data on hand to help.
How do you get at your raw data? Do you need to contact the log administrator? The backup/storage administrator? Did you get the right data the first time? No? So you need to contact them all again? No wonder some large companies don’t disclose breaches for months if not years.
With the idea of storing and replaying your raw machine data in mind (“raw” meaning, prior to transmutation where you would pull out seemingly useless information), let’s look at how two of the major players in the space handle this task: fluentd and Cribl Stream.
Starting with fluentd there is an architectural design you have to keep in mind while deploying fluentd – once you send data to a destination, you can no longer make changes to the data, it’s gone. This means that if you want to send your raw machine data to, say, S3 for long-term storage prior to shaping and slimming it down, you have to have two fluentd instances: the first will collect the data and ship it to S3 as well as the second fluentd instance while the second instance is where you will do all of your fun data shaping AND pushing to your actual destinations.
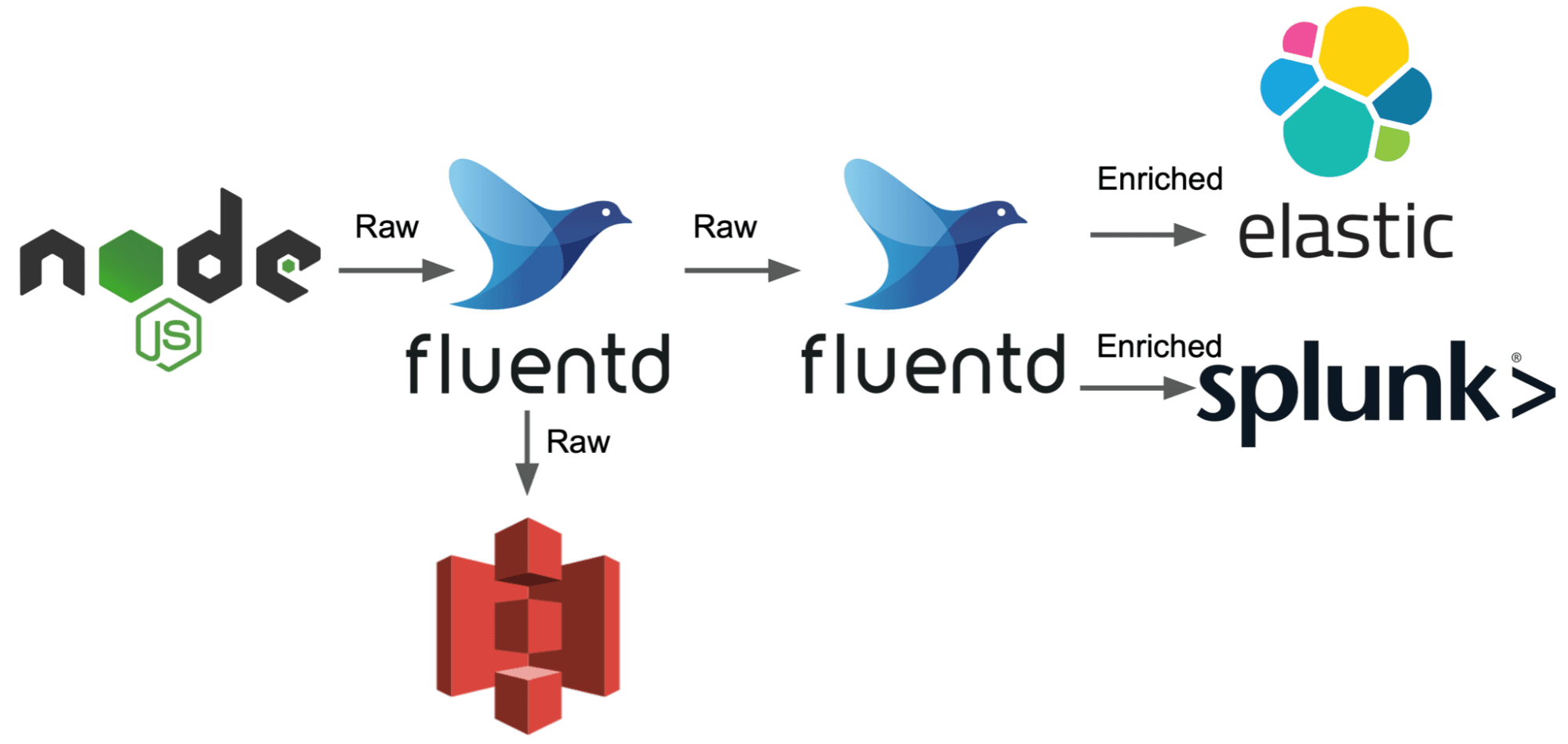
Wrapping ask that into one sentence: You need two ‘layers’ of fluentd just to send copies of your raw data off to long-term storage prior to manipulation. (You would also need another layer if you want to pull your stored data out of storage, even if it’s post transformation.)
On to Stream, where Replay is built into the product from the beginning. In Stream, sending to multiple destinations pre AND post data manipulation is not only doable but encouraged. To do this, we create a pipeline that doesn’t do anything to the data, just passthrough. Oh wait, it’s already there by default. Ok, then let’s add the pipeline to a route that pushed everything to S3.
Now that is out of the way, we can continue on with the rest of our data transmutation by adding more routes. So long as we didn’t select ‘final’ on the raw to S3 route, the data stays in Stream and allows us to reuse/edit it in flight to send it to our final destinations.
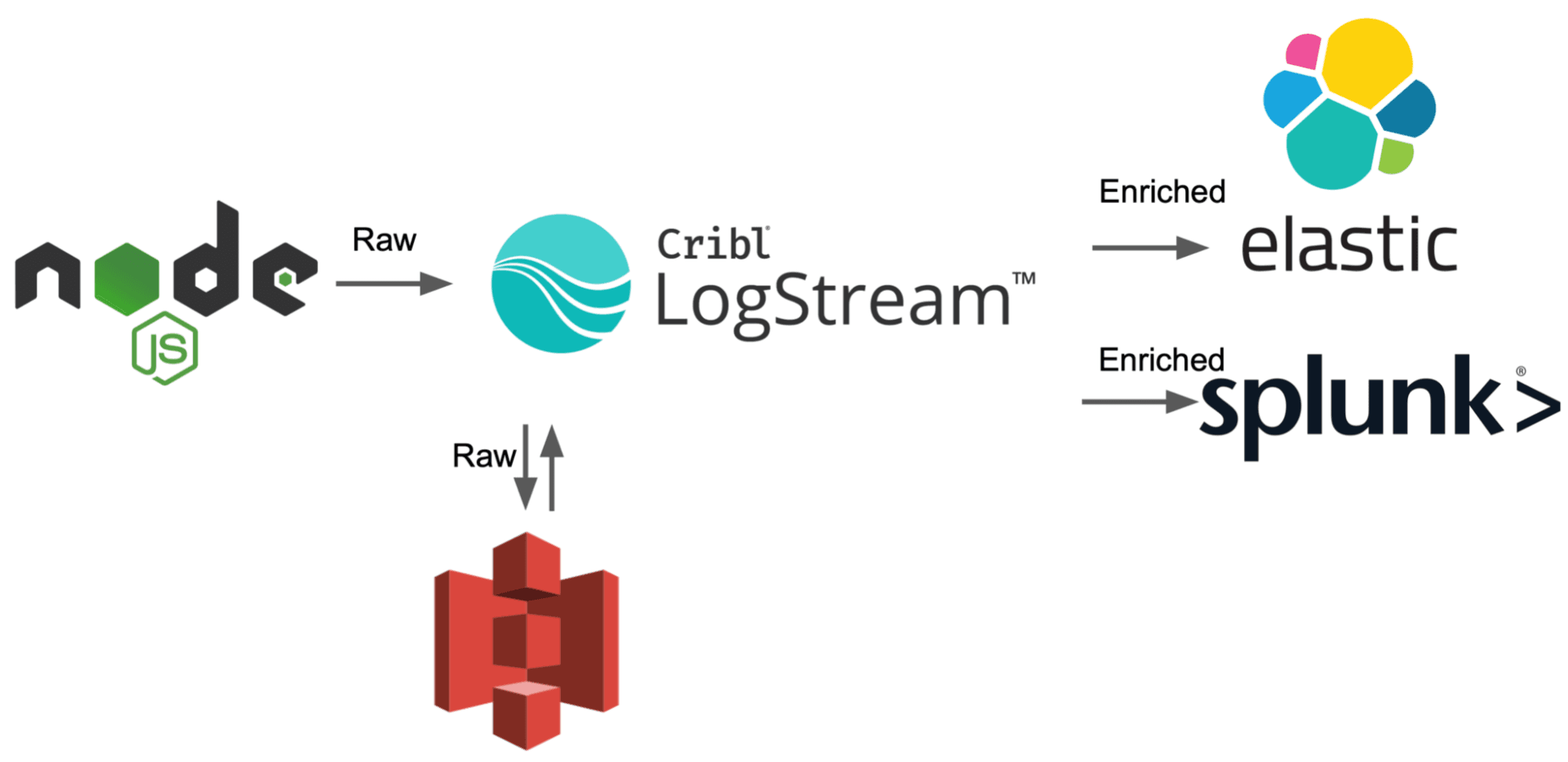
Ok, recap: Using fluentd, you need to architecturally have two ‘layers’ of fluentd running. One ONLY sends to S3 and your second layer of fluentd, because once data is sent somewhere from fluentd it leaves the pipeline. Conversely, with Stream you can simply use the included passthrough pipeline with a non-final route to take raw data and put it in S3. From there, you can continue to sanitize and slim down the data before sending it off to your other sources.
All this is to say, when considering tools to use in your observability pipeline, consider the ability to send raw data to cheap storage. Stream seems like the easy choice to make. Oh by the way, next time we’ll talk about how different vendors handle pulling data from S3 in order to actually replay the raw data you just sent there. Hint: fluentd doesn’t have a certified S3 source plugin.
The fastest way to get started with Cribl Stream is to sign-up at Cribl.Cloud. You can process up to 1 TB of throughput per day at no cost. Sign-up and start using Stream within a few minutes.







