

Data lakes are everywhere! With data volumes increasing, cost-effective storage is becoming a greater need. With Cribl Stream, you can route data to an Amazon S3 data lake and replay or search that data at rest. But nothing is more frustrating than something not working and those blasted error logs that pop up. In this blog, some common errors for your S3 sources or destinations are highlighted, and some potential root causes and solutions are highlighted. This is not an exhaustive list but encompasses some of the more common issues you may encounter. That being said, each environment is different, so use these as a general guideline.
Authentication Options
You have two main authentication options for setting up S3 Sources/destinations. You can leverage Assume Role in which Cribl workers adopt an AWS role with permissions and policies attached. Alternatively, you can use an access key/secret key combination to authenticate (also with restrictions and policies).

You may use one over the other for various reasons, but primarily when trying to accomplish cross-account access between Cribl.Cloud to your AWS account, Assume Role is the preferred method. It allows you to gain access without creating temporary IAM keys. For anything not running in AWS (your on-premise and other cloud provider workers would fall into this category), the Access Key/Secret Key option is available to create a static set of user-associate IAM credentials for authentication.
For more information on cross-account access and configuration, visit this link.
Where to Look for a Problem
Whether you are troubleshooting an AWS S3 source or destination, you can start by navigating to the source or destination you suspect has an issue (Figure 4). If you are troubleshooting a collector, you will instead want to navigate to the Job Inspector (Figures 1-3) for the latest collector run (Monitoring > System > Job Inspector > Click on the relevant Job ID).
Within the source or destination pop-out, the “Logs” tab includes all errors/warnings/etc (Figure 5). Messages that you can search and the “Status” tab (Figure 6) give you a high-level view of errors at a worker level. Both will be handy in diagnosing your issue. Within the collector job pop-out, the “Logs” tab (Figure 2) is also relevant as well as the “Task Errors” tab (Figure 3), where you can drill deeper into the specific errors for the collection tasks at hand. A handful of screenshots below will highlight and display each of these pages.

Figure 1: Job inspector – Job stats page

Figure 2: Job inspector – Job logs page
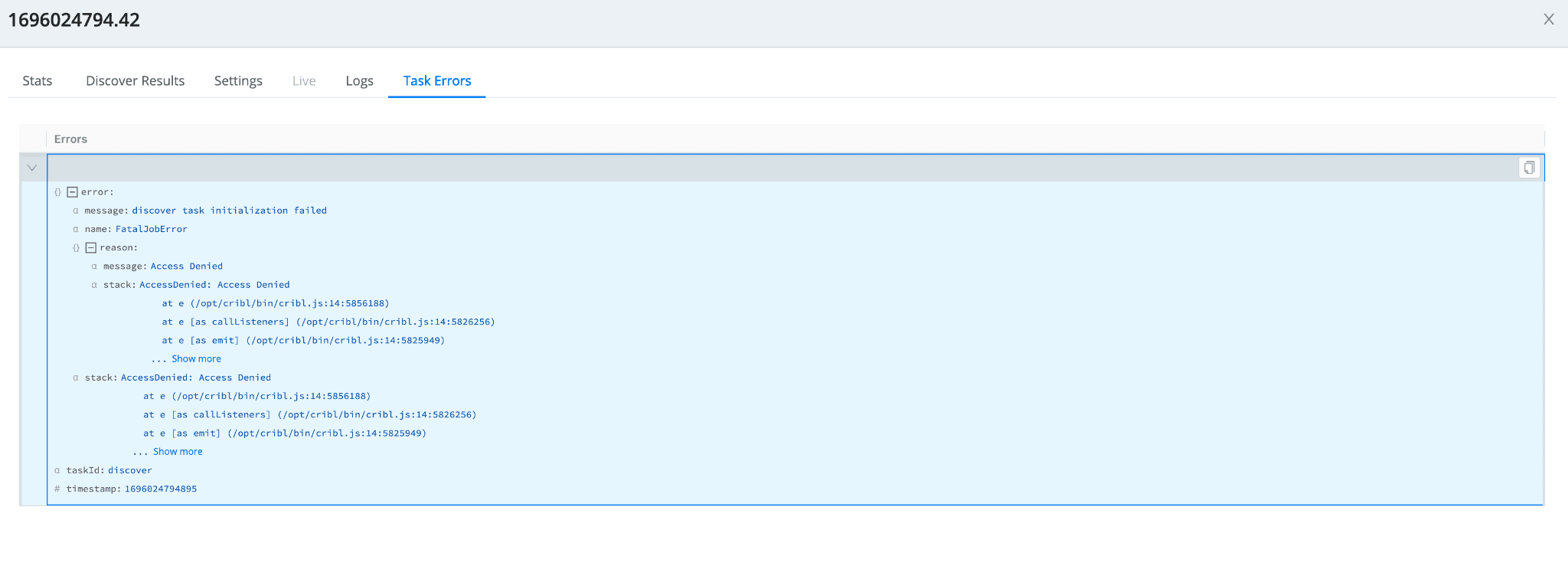
Figure 3: Job inspector – Job Task errors page

Figure 4: S3 Destination – Configuration page

Figure 5: S3 Destination – Logs
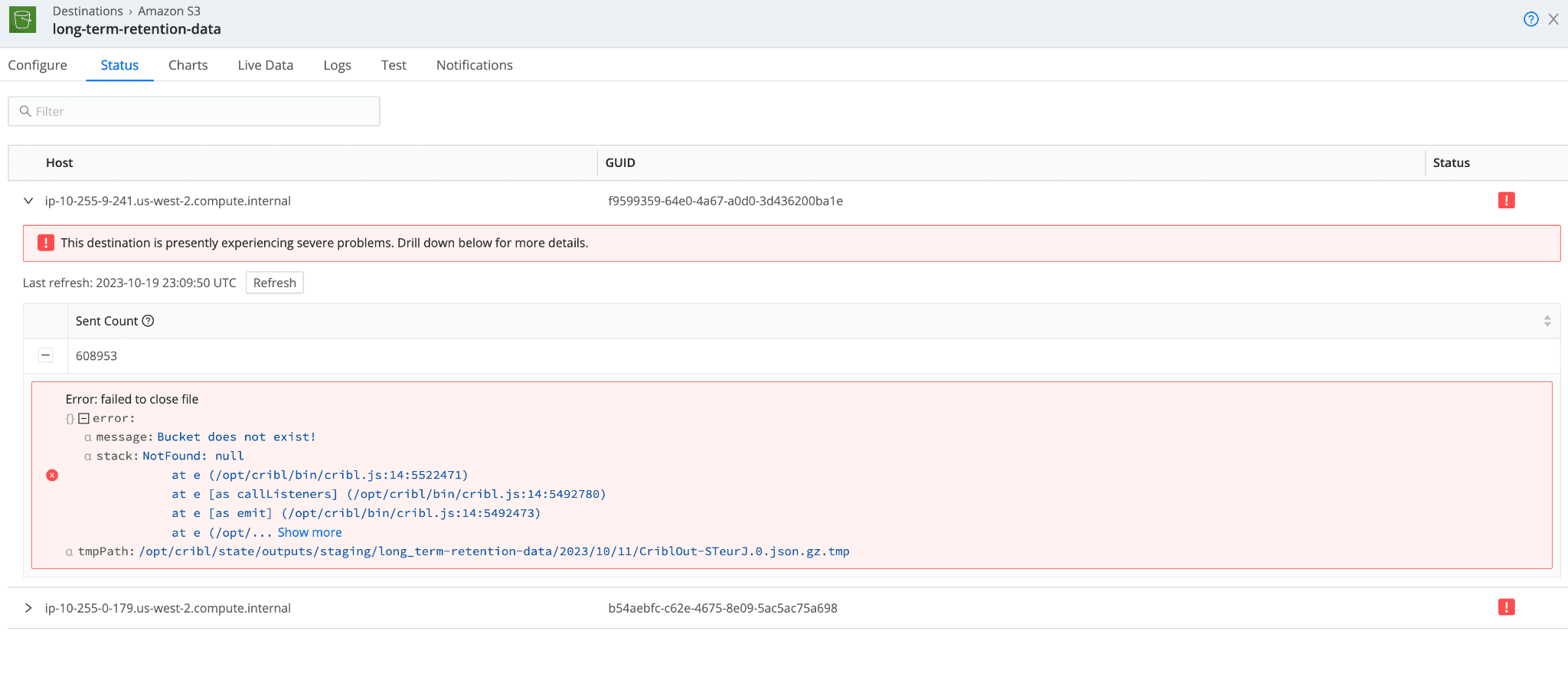
Figure 6: S3 Destination – Status page
Embedded Log Hints
With the latest minor release (4.4), Cribl has integrated more hints into the S3 source and destinations to offer help while troubleshooting. When looking at the errors in the status tab and logs, you will now find a “hint” field that offers a bit more context around the error message you are receiving. See the example down below for a “Bucket does not exist” error and its corresponding hints. This now allows you to speed up your troubleshooting and focus on some of the more common fixes first.

Common Errors
Throughout our experience working with customers sending and receiving data from S3, we have compiled a list of common error messages you may receive from one of your S3 sources or destinations. Below is the list of these common errors, why they may be an issue, and what a potential resolution might be. Once again, this is not an exhaustive list of either errors or resolutions but it offers some guidance on a starting point. Your environment may differ, and you must incorporate any intricacies in your troubleshooting.
Error #1
When you have received this error, there can be several root causes:
Problem with User/Role permissions
Problem with a resource or trust policy
Problem with prefixes
Problem with Access Key/Secret Key
Some of the items to check would be:
Access Key is not inactive, empty and is correct
Check your resource policies and trust policies and ensure accuracy. Revisit the cross-account access use case documentation for samples.
Validate you added the correct prefixes for your bucket in your resource policy if specifying.
Your cloud administrator may have a permissions boundary in place
Error #2
When you have received this error, there can be a number of root causes:
The bucket may not exist
The bucket may not be in the specified region
The bucket may be misspelled
Some of the items to check would be:
Check that the bucket exists
Check the existence of the bucket in the account you specified. Keep in mind that you may have permissions via Access Key or AssumeRole to a different account.
Check spelling of the bucket name
Check the region of the bucket
Error #3
When you have received this error, there can be a number of root causes:
Bucket or data is being encryptedNOTE: This is extremely common with CloudTrail data in S3 buckets that is being encrypted with a KMS key
Some of the items to check would be:
Check KMS is reference in the service config (ie: CloudTrail, S3, etc)
Check your resource policy has the appropriate access to the KMS key needed (“KMS:decrypt”)
Allow access to the KMS key from the key policy itself (in AWS Console, navigate to KMS → Key → Permissions)
Will typically manifest as a task error
Error #4
When you have received this error, there can be a number of root causes:
User does not have access to the proper KMS key
Some of the items to check would be:
Validate resource permissions include “KMS:decrypt” permissions for the user being used
Allow access to the KMS key from the key policy itself (in AWS Console, navigate to KMS → Key → Permissions)
Error #5
Similar to above, when you have received this error, there can be a number of root causes:
Role does not have access to the proper KMS key
Some of the items to check would be:
Validate resource permissions include “KMS:decrypt” permissions for the role being used
Allow access to the KMS key from the key policy itself (in AWS Console, navigate to KMS → Key → Permissions)
Error #6
When you have received this error, there can be a number of root causes:
Access key presence in the Cribl Stream config but it is not in use
Incomplete or incorrect resource policies
Some of the items to check would be:
Remove any Access Key/Secret Key information from the Cribl Stream config page if you are no longer using it and opting for AssumeRole instead
Check the externalID (if in use) is correct and matches what is in the trust policy
Verify the role exists in IAM
Validate your resource policies for correctness. Revisit the cross account access use case documentation for samples.
Error #7
When you have received this error, there can be a number of root causes:
Improper resource policy for the S3 bucket
Permissions boundary in place
Permissions lacking locally in the Cribl worker staging directory
Some of the items to check would be:
Improper permissions on the Resource. You will need access to the bucket for the “s3:ListBucket” action but will need access to the /* prefix for “s3:GetObject” and “s3:PutObject” permissions.
Your cloud administrator may have a permissions boundary in place for that s3 bucket.
Check the staging directory on your workers. Update permissions on this directory (chmod 777) to allow workers to write objects here while staging them to go to your s3 destination bucket.
Error #8
When you have received this error, there can be a number of root causes:
File compression issues
Non-supported compression type
Some of the items to check would be:
Problem with file compression. Test without compression to see if the issue continues to manifest.
Improper file name extension or unsupported compression type
Cribl Stream uses content encoding headers to validate data is actually encrypted. Validate headers are not corrupted if compression continues to be an issue. Typically, you can check locally on your machine by testing if you can uncompress a file first.
Error #9
When you have received this error, there can be a number of root causes:
Connectivity Issues
Running up against S3 API limits
Downstream Cribl Stream destination having issues
Some of the items to check would be:
It could be a lower-level connectivity issue. Check proxies and firewalls egressing/ingressing to S3 (depending on context)
Check routes/pipeline issues for S3 sourced data (via collector or SQS). If the downstream destination has an issue, this can manifest.
S3 has limits to the API – 3,500 PUT/COPY/POST/DELETE or 5,500 GET/HEAD requests per second per prefix in a bucket. You may run into this issue if you are hitting this limit. Consider adjusting your partitioning to reduce cardinality. Visit the S3 best practices video for more information.
Conclusion
As a quick summary, we’ve highlighted some common errors you may encounter while setting up your S3 sources and destinations in Cribl Stream. We hope that has alleviated some of the potential headaches you may encounter during your implementation of Stream. We are always open to hearing more about anything you’ve experienced. Hit us up in Cribl Community Slack with any additional questions, comments, or new issues you’ve encountered. Happy troubleshooting!






