AI observability is how teams see what their AI systems are doing, why they are doing it, what they cost, whether they are safe, and how they change over time. For a traditional application, a fast response and a clean status code may be enough to say the system is healthy. For an AI system, that same request can still be wrong, unsafe, expensive, or based on bad retrieval. That is the gap AI observability is meant to close.
Modern AI systems generate more than logs and latency charts. They produce prompts, completions, tool calls, retrieval steps, token counts, model choices, policy events, and infrastructure signals. AI observability brings those signals together so teams can understand real behavior instead of guessing from the outside.
Cribl's approach starts with telemetry. AI systems create a flood of useful signals, but most teams still scatter that data across too many tools, storage tiers, and owners. Cribl frames this as an AI Platform for Telemetry problem. If you collect, shape, protect, and route AI telemetry correctly, the rest of the observability work becomes more practical.
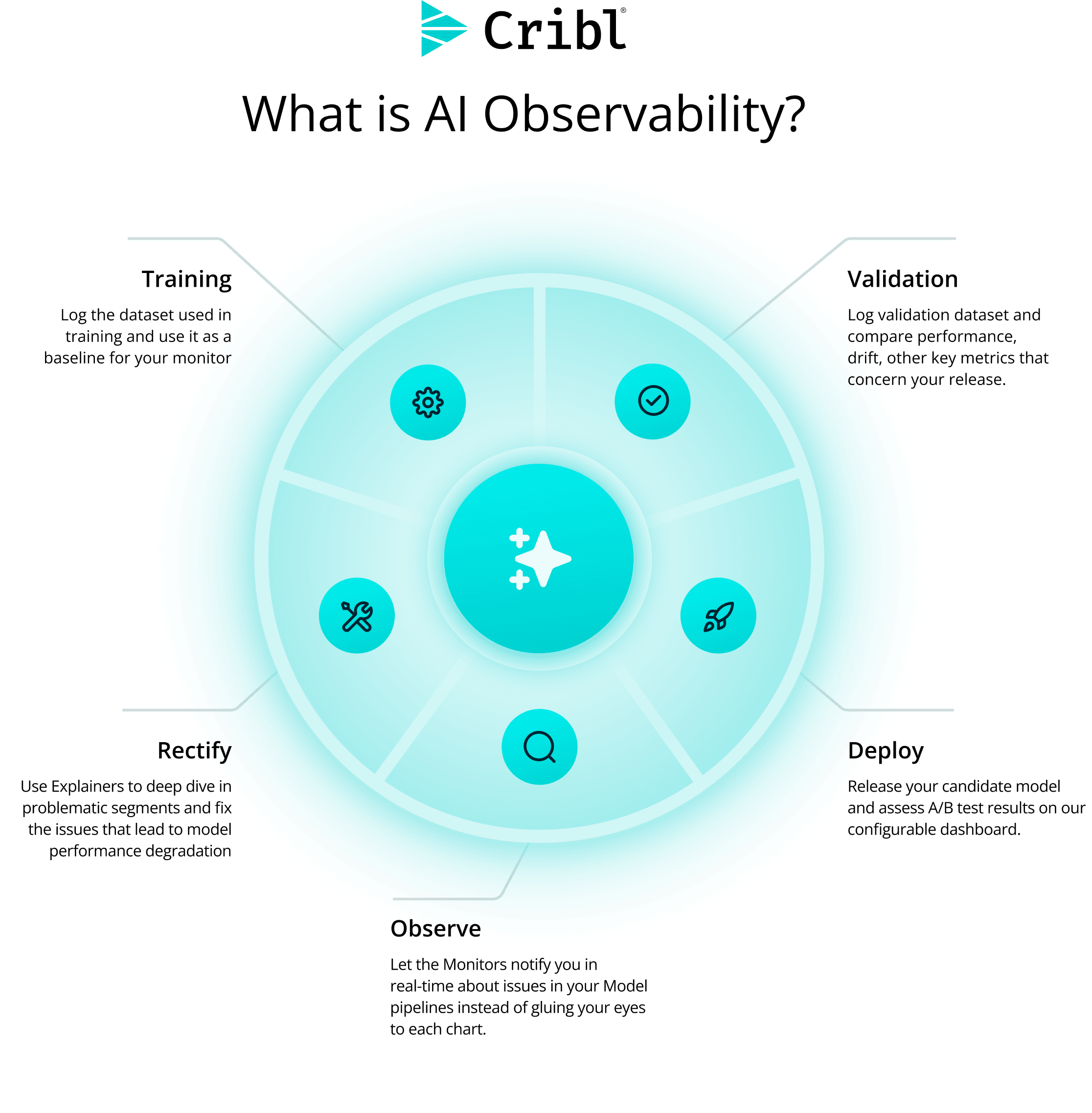
What is AI observability in a nutshell?
At its simplest, AI observability is the practice of collecting, correlating, and analyzing the signals that explain how an AI system behaves in production. That includes questions like:
What prompt or input led to this output?
Which model answered the request?
What documents were retrieved?
Which tools were called?
How long did the full request take?
How many tokens did it consume?
Did anything sensitive appear in the prompt or response?
Did behavior change after a model, prompt, or retrieval update?
Traditional observability tells you whether a system is up. AI observability helps you understand what the system actually did. That matters most for LLM apps and agents, where a request can look healthy in a dashboard and still produce a bad answer, leak sensitive data, or run up a surprising bill.
Cribl's view is that one AI interaction is never just one kind of event. It is a performance event, a cost event, a security event, a quality event, and a compliance event at the same time. Observability must support multiple stakeholders and multiple tools from the same underlying telemetry, not force every team into one destination or one retention model.
Why is AI observability necessary today?
AI adoption moved faster than visibility. Many teams already have LLM apps, copilots, retrieval pipelines, and agents in production, but their observability stack was built for APIs, services, and infrastructure, not for prompts, completions, reasoning steps, and model behavior. The result is a familiar problem: teams can see that the system responded, but not whether it responded well.
That gap shows up in a few ways.
First, AI failures do not look like normal software failures. An LLM can return a response quickly and still hallucinate, cite the wrong source, miss the user's intent, or call the wrong tool.
Second, one AI interaction matters to more than one team. SRE cares about latency and errors. Security cares about prompt injection and sensitive data. FinOps cares about token and GPU cost. AI engineers care about quality and drift. Compliance cares about retention and audit trails. One event, many consumers.
Third, the most important questions often arrive later. Did the model leak PII last quarter? Did quality drop after the team changed the system prompt? Which agent runs used a deprecated tool? Those are history questions, not just dashboard questions.
Fourth, shadow AI is real. Not every AI interaction flows through an approved app or a neatly instrumented stack. People use browser tools, personal accounts, model gateways, and ad hoc scripts. If you only watch sanctioned traffic, you get a partial story and may mistake it for full coverage.
Cribl treats AI telemetry as shared infrastructure rather than one more silo. Stream and Edge collect data from instrumented apps, providers, gateways, and infrastructure. Guard redacts PII, PHI, credentials, source code, and other sensitive content before that data crosses a trust boundary. Search gives teams a place to investigate the full picture across the data they centralize and the data that still lives elsewhere.
Who cares about AI observability?
More teams than you might think.
Platform engineering and AI platform teams need a practical way to collect and shape telemetry across providers, gateways, agents, and infrastructure without creating a new data engineering project. Observability and SRE teams need to connect latency, throughput, and failures to what the model or agent actually did. Security teams need to see prompt injection attempts, sensitive content exposure, shadow AI usage, and risky tool calls before those become incidents. Compliance and legal teams need defensible retention, redaction, and audit trails. FinOps and engineering finance teams need token and infrastructure cost tied to teams, apps, features, and model choices. AI engineering and product teams need to understand prompt behavior, retrieval quality, tool use, regressions, and what users are actually asking their copilots.
AI observability is a shared data problem. Different teams need different slices of the same AI event, at different cost tiers and in different tools. Some teams need dashboards. Some need flagged security events in a SIEM. Some need long-term history for audits or quality review. Some need to ask exploratory questions across prompts, traces, and infrastructure data. Cribl is built to route that telemetry once, then shape it for the teams and tools that need it.
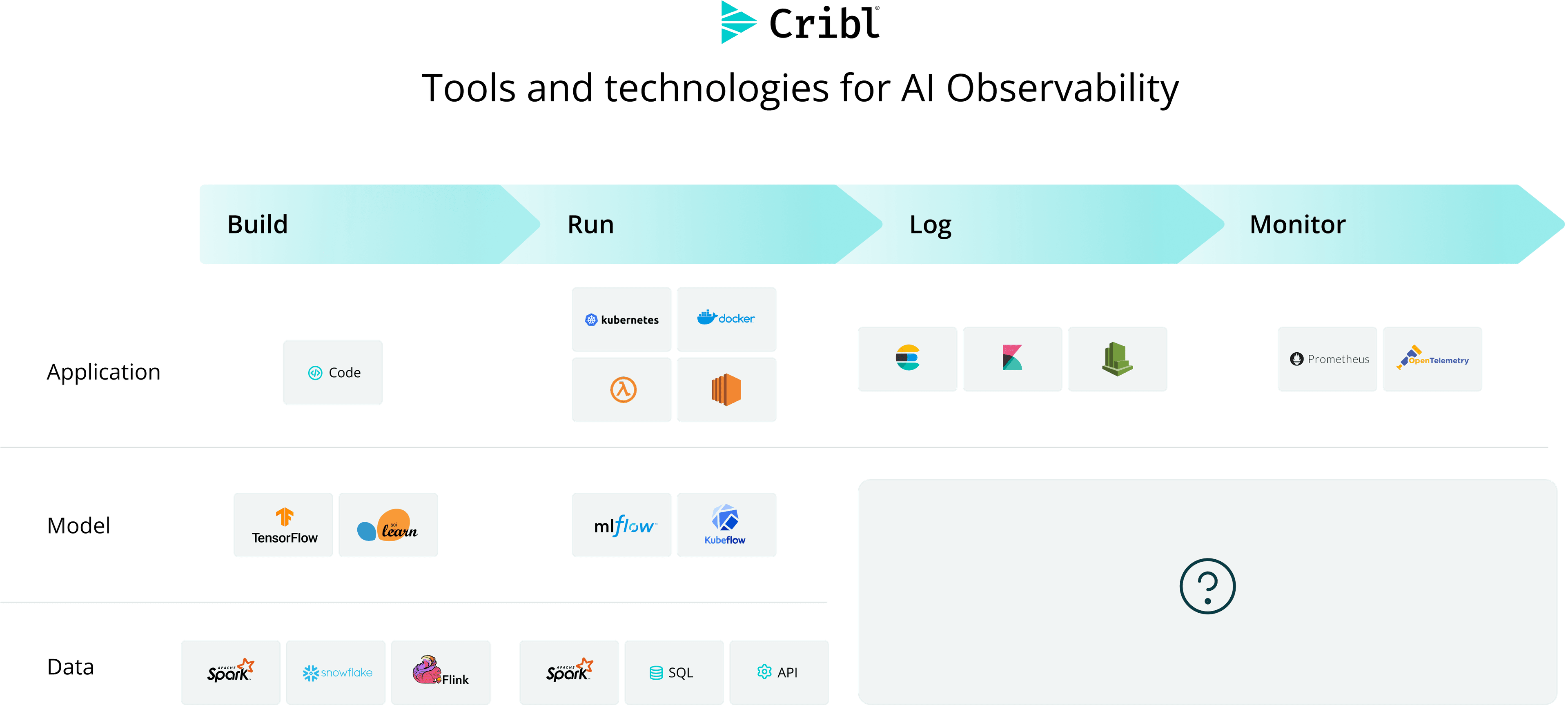
Tools and approaches for AI observability
There is no single magic console for AI observability. Most teams need a mix of approaches.
Step 1
Instrument the application and the model path
Start where the interaction happens. Capture traces, events, and metadata from the app, the model call, retrieval steps, and tool invocations. For LLM systems, that usually means treating prompts, completions, token usage, and model metadata as first-class signals. Cribl works well with OpenTelemetry here. OTel gives teams a common way to instrument LLM apps and agents, while Cribl provides a way to move, normalize, enrich, redact, and route that telemetry after it is emitted.
Step 2
Follow the full request, not just the final response
For agent and retrieval-heavy systems, the answer is only the endpoint. The real story sits in the chain of actions behind it: retrieval calls, reranking, tool calls, retries, fallbacks, and model switches. End-to-end tracing matters. Cribl Search gives teams a place to visualize and investigate the chain, not just store it. Teams can explore traces, correlate AI signals with other telemetry, and ask questions of their data instead of bouncing between separate tools and partial views.
Step 3
Track cost as part of system behavior
AI cost is not separate from performance. Token usage, model selection, context size, retries, and tool loops all affect spend. Good AI observability ties cost to user flows, teams, features, and model versions. Cribl can shape that telemetry on the way through the pipeline, enrich it with business context, and route the right level of detail to FinOps, observability, and long-term storage instead of forcing all of it into one expensive destination.
Step 4
Treat security and privacy as built-in concerns
Prompts and completions often contain customer data, source code, credentials, or regulated information. That means observability cannot be a capture-everything exercise. Teams need a way to inspect behavior while still masking or controlling sensitive content. Cribl Guard detects and redacts sensitive content in flight so teams can preserve useful signal without turning their observability stack into a new data-handling problem.
Step 5
Route data for different consumers
The same AI event does not need to land everywhere in the same form. Hot dashboards may need metadata and timing. Security tools may need flagged events. Evaluation tools may need sampled high-fidelity traces. Long-term investigation may need a fuller historical record stored at lower cost. This is a core use case for Cribl. The AI Platform for Telemetry idea is not just about collection. It is about routing one interaction to many stakeholders and many tools without duplicate collection, blind spots, or unnecessary cost.
Step 6
Keep history searchable
Some of the most valuable AI questions are retrospective. If you cannot revisit prompts, outputs, tool calls, and supporting context later, you lose the ability to investigate regressions, prove compliance, or learn from production behavior. Cribl Search and Cribl Lake are built for that kind of work. Search gives teams a way to investigate, visualize, and ask questions across current and historical telemetry. Lake keeps full-fidelity data at a lower cost so those long-tail questions stay answerable.
Step 7
Extend observability to AI infrastructure
AI observability is not just about prompts and completions. For teams running their own inference stacks, it also includes the infrastructure under the model: GPUs, serving layers, gateways, and edge environments. Cribl Edge extends the telemetry and policy layer closer to the source. That is useful for AI infrastructure, distributed environments, and cases where teams need to process or protect telemetry before it leaves the local boundary.
Key AI observability design goals
Good AI observability should aim for a few clear outcomes.
Explain behavior, not just uptime. You want enough context to answer why a system behaved the way it did. Preserve trust. Sensitive content should be controlled before it spreads into downstream tools and stores. Support many teams from one event. The same interaction should serve engineering, security, finance, and compliance without forcing everyone into the same tool or retention model. Control cost. Full-fidelity AI telemetry is valuable, but not every destination needs every byte. Keep history available. Teams need long-term records for audits, regressions, incident review, and product learning. Normalize across change. Providers, frameworks, and semantic conventions keep moving. Your observability approach should not break every time the stack changes. Cover both approved and unapproved usage. Instrumented traffic matters, but so does the shadow AI activity outside the clean path.
Cribl provides one telemetry layer for collecting and shaping AI data, one way to route that data to different stakeholders and tools, one place to apply policy, and one investigation surface in Search where the data becomes usable. That matters even more as the OpenTelemetry gen_ai conventions keep shifting. OTel points the community toward standardizing AI telemetry, but the schema is still changing. Cribl helps absorb that change by normalizing and adapting telemetry in the pipeline so downstream teams do not have to rebuild their dashboards, detections, and workflows every time the standards move.
Relevant technologies
Several technologies show up again and again in modern AI observability programs.
OpenTelemetry and emerging GenAI semantic conventions for common instrumentation patterns
OTLP for moving telemetry between sources and downstream systems
Traces, logs, metrics, and events enriched with AI-specific fields such as model, token usage, prompt metadata, tool calls, and retrieval context
Model gateways and LLM proxies that centralize policy, routing, and logging
Retrieval and vector infrastructure that adds context to model requests
Security controls such as redaction, data loss prevention, and policy enforcement
Object storage, lakehouse platforms, and federated search for long-term investigation
APM, SIEM, evaluation tools, and cost analytics tools that consume different slices of the same underlying telemetry
GPU and infrastructure telemetry for teams running model serving or high-volume inference environments
Cribl Stream, Cribl Edge, Cribl Guard, Cribl Lake, and Cribl Search as the telemetry, control, protection, storage, and investigation layers working together. This represents the AI platform for telemetry.
No matter which tools you choose, the principle is the same: collect the right signals once, shape them carefully, and make them usable by the teams that need them.
The bottom line
AI observability is the practice of making AI behavior visible, understandable, and governable in production. It helps teams move past shallow signals like uptime and into the questions that actually matter: what happened, why it happened, what it cost, whether it was safe, and how to fix it.
Cribl's argument is simple: this works best when AI observability is treated as an AI Platform for Telemetry problem. Collect once. Route to many stakeholders and tools. Redact sensitive data where appropriate. Keep history available. Then use Search to visualize, investigate, and ask better questions of the data. That is how AI observability becomes something teams can actually use, not just something they say they have.
What is the difference between AI observability and traditional observability?
Traditional observability tells you whether a system is up by tracking metrics like latency, throughput, and error rates. AI observability goes further, explaining what an AI system actually did: which model responded, what was retrieved, what the prompt contained, how many tokens were consumed, and whether the output was safe or accurate. A system can pass every traditional health check and still produce a wrong, unsafe, or costly AI response.
Why do multiple teams need access to the same AI telemetry?
One AI interaction is simultaneously a performance event, a cost event, a security event, a quality event, and a compliance event. SRE teams need latency and error data. Security teams need to detect prompt injection and sensitive content exposure. FinOps teams need token and GPU cost tied to specific apps and features. Compliance teams need defensible audit trails. AI engineers need quality and drift signals. Routing the same underlying telemetry to each team, shaped for their specific tools and needs, is more efficient than collecting it separately for each group.
How does shadow AI affect AI observability?
Shadow AI refers to AI interactions that happen outside sanctioned apps or instrumented pipelines, such as employees using personal accounts, browser-based tools, or ad hoc model gateways. If your observability only covers approved traffic, you get a partial picture and may mistake it for full coverage. Effective AI observability programs account for both instrumented and uninstrumented usage to avoid blind spots.
What role does OpenTelemetry play in AI observability?
OpenTelemetry provides a vendor-neutral standard for instrumenting applications and emitting telemetry. Emerging GenAI semantic conventions within OTel are extending that standard to cover AI-specific signals like model identifiers, token usage, prompt metadata, tool calls, and retrieval context. Because the schema is still changing, teams benefit from a telemetry layer that can normalize and adapt signals in the pipeline so downstream dashboards, detections, and workflows do not break every time the conventions change.
How does Cribl support AI observability?
Cribl approaches AI observability as an AI Platform for Telemetry problem. Cribl Stream and Edge collect telemetry from instrumented apps, model providers, gateways, and infrastructure. Cribl Guard detects and redacts sensitive content in flight before it reaches downstream tools. Cribl Lake stores full-fidelity historical data at lower cost. Cribl Search gives teams one place to investigate, visualize, and ask questions across current and historical AI telemetry. Together, these capabilities let teams collect once, route to many stakeholders and tools, and keep history available for audits, regressions, and product learning.