
Executive summary
DORA has moved from policy conversation to board agenda. For CISOs and their peers, it is no longer a question of whether you comply, but whether you can prove resilience, quickly and credibly, under supervisory scrutiny.
Most financial institutions already have “the right tools” on paper. What is missing is a single, trusted evidence layer that can stand up to questions like:
What exactly happened, across systems and suppliers, during this incident?
How do you know your controls actually work, not just that they exist?
Can you replay and explain the story six, twelve, or twenty‑four months later, without a war‑room of analysts
This guide is written for cybersecurity executives and leaders in security, IT, risk, and operational resilience who sit in the firing line for DORA outcomes. It is for people who are tired of fragmented telemetry, heroic investigations, and last‑minute DORA “gates” slowing strategic deals. It offers a pragmatic path from scattered logs to evidence‑grade telemetry, without pretending that anyone can “buy DORA” off the shelf or turn into a consulting firm overnight.
We will look at why DORA is hard in practice for security and resilience teams, translate DORA’s pillars into concrete telemetry requirements, define the capabilities a modern telemetry control plane needs, and show how Cribl — the data engine and AI platform for telemetry — fits as a vendor‑neutral resilience data layer across your existing tools. We end with a practical telemetry roadmap you can use to brief your organisation and your partners.
We will not offer legal advice, interpret specific clauses on your behalf, or certify anyone as “DORA compliant”. What we can do is help you put the telemetry foundations in place so that your lawyers, risk teams, and auditors have stronger evidence to work with.

If you take one idea away, make it this:
DORA will be won or lost on your telemetry. Controls, processes, and contracts all matter — but without evidence‑grade data under them, you are asking supervisors and boards to take your word for it.
The operational reality: why DORA is hard in practice
Most DORA conversations do not start with a regulation PDF. They start when a CISO, CIO, or Head of Operational Resilience runs into three uncomfortable truths inside their own organisation.
Fragmented telemetry, fractured stories
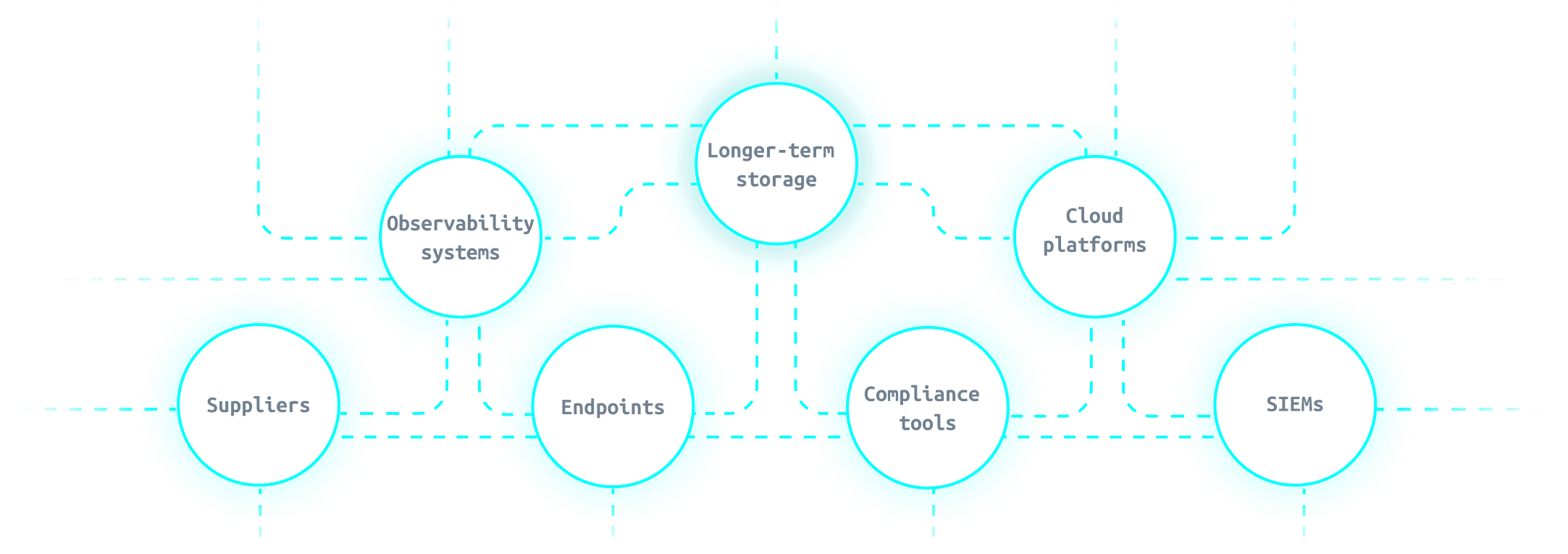
Over the years, organisations have accumulated a patchwork of SIEMs, XDRs, observability stacks, threat intelligence feeds, and compliance tools. Each system sees a slice of reality. None sees the whole story.
Ownership is split across security operations, incident response, IT operations, SRE and platform teams, risk and resilience, and central DORA programme offices. When something goes wrong, you do not have “one dataset with many views”. You have many datasets, many views, and no shared ground truth.
That might be manageable for internal reporting. It is far less comfortable when a supervisor, central bank, or internal audit committee asks you to show, step by step, what happened, how you know, and why different parts of the organisation are telling the same story.
“Store everything everywhere” meets flat budgets
Telemetry volume is growing much faster than budgets. Cribl’s own product overview notes that telemetry data is growing at about 30 percent compound annually, while budgets stay largely flat. At the same time, compliance mandates push you to retain more data, at finer granularity, than most analytics systems were designed to handle.
The result is familiar. SIEM and observability platforms are filled with data they are not optimised to analyse. Cold storage and backup strategies are bolted on as an afterthought. Retention decisions end up driven by cost and licence limits instead of risk and evidence value.
DORA widens the scope of what is “in play” — more systems, more logs, broader definitions of incidents, and longer time horizons to consider. Taken literally, that can explode your data and tooling costs unless you get much smarter about what you collect, how you route it, and where you store long‑term evidence.
When “good enough” incident management is not enough
Many organisations already run mature incident response processes. They classify incidents, follow playbooks, engage crisis teams, and produce post‑incident reports.
DORA raises the bar in several ways. It expects effective processes for consistent monitoring, handling, and follow‑up of ICT incidents, plus timely reporting to oversight bodies for major incidents. It pushes you towards standardised criteria and timelines, more structured reporting, and tighter links between incidents, resilience tests, and third‑party failures.
Without an evidence‑grade telemetry layer, even strong SOCs often rely on ad hoc data pulls. Teams rehydrate cold data into the SIEM at short notice, reconcile conflicting views from different tools, and rely on spreadsheets and screenshots to stitch together a narrative. It can work, but it does not scale and it certainly does not feel robust when someone outside the room starts asking detailed questions.
AI expectations on top of brittle data
Boards and regulators are increasingly asking not just whether you are using AI in detection, investigation, and reporting, but how you trust it. They want to know what data underpins any AI‑driven outputs and how you manage the associated risks.
If your telemetry is incomplete across entities and suppliers, hard to normalise and enrich, and expensive to query at historical depth, then AI risks amplifying gaps instead of simplifying DORA execution. You cannot have trustworthy AI until you have trustworthy data for DORA.
What DORA actually demands of telemetry
DORA reads like regulation, not architecture diagrams. To make it useful for a CISO, it helps to restate the pillars as questions about telemetry.
ICT risk management: do you know what is in scope and how it behaves?
DORA expects financial entities to treat ICT risk as a core operational discipline. That goes well beyond a list of systems.
From a telemetry angle, this means you should be able to identify your ICT assets, functions, and interdependencies, including cloud, SaaS, and critical third parties, and tie them to the data that describes their behaviour. You should know which logs, metrics, traces, and events you would rely on to understand a disruption for a given service, and you should be able to demonstrate that monitoring and logging coverage aligns with the organisation’s risk appetite and impact tolerances.
If nobody can answer “which data do we depend on to understand this critical function in practice?”, or conversely “how do we add configuration management (CMDB) insights to this telemetry to pinpoint risks?”, you have an ICT risk management gap as well as a telemetry gap.
ICT incident management and reporting: can you reconstruct and explain events?
DORA mandates effective monitoring, handling, and follow‑up of ICT incidents, together with structured reporting to authorities for major events. It expects you to classify incidents consistently and to explain what happened, how you responded, and what you learned.
Telemetry needs to support that by giving you rapid access to relevant events, the ability to reconstruct an incident timeline across hot and cold data, and a consistent view for internal and external reporting. When you build an incident narrative, it should be grounded in actual events, not in whatever data happened to be easiest to export that week.
If you only “pull the data” once a supervisor or board member asks, you are leaving too much to chance. Another benefit of using a single source is that actual incident responders can focus on restoring IT services. IT incident managers, DORA incident reporters, Crisis Communication, and other stakeholders can access the consistent data layer instead of querying responders and distracting them from their critical work.
Digital operational resilience testing: do you have data to test against?
Resilience testing under DORA is not just about security controls. It covers business continuity and disaster recovery scenarios, broader operational resilience exercises, and, for some entities, threat‑led penetration testing for critical functions.
To be useful, tests need to reflect how your systems and suppliers actually behave. Telemetry can help you do that by showing real patterns of partial failures, timeouts, and degradation, which you can turn into realistic scenarios. It can also capture test activity as if it were a real incident, so that you can analyse and improve, and can supply historical slices of data to replay into analytics tools to see how they respond under simulated stress.
Without that, testing risks becoming a paperwork exercise rather than a learning process.
Third‑party risk: do you understand and evidence ICT supply chain exposure?
One of DORA’s sharper edges is its focus on ICT third‑party risk and concentration. It expects financial entities to manage ICT providers throughout the lifecycle, maintain a register of arrangements, understand concentration risk, and include resilience and audit provisions in contracts.
Telemetry has a role here too. It can show where third‑party services sit in critical paths, what telemetry you receive from them, and how you use it. It can help you demonstrate, with data, how a third‑party failure propagated through your environment and how your controls responded. If your only view of third‑party telemetry is whatever they choose to send into your SIEM, DORA will push you to strengthen that story.
Information and threat sharing: can you share without losing control?
DORA encourages financial entities to participate in trusted information sharing schemes and to notify significant cyber threats to authorities. Telemetry underpins this as well.
You need to extract relevant indicators and patterns without oversharing customer or proprietary data, preserve lineage so that you can explain where shared information came from, and feed insights from the wider ecosystem back into your own detection and testing programmes. Again, this is much easier if you have a clear evidence layer rather than a loose collection of exports.
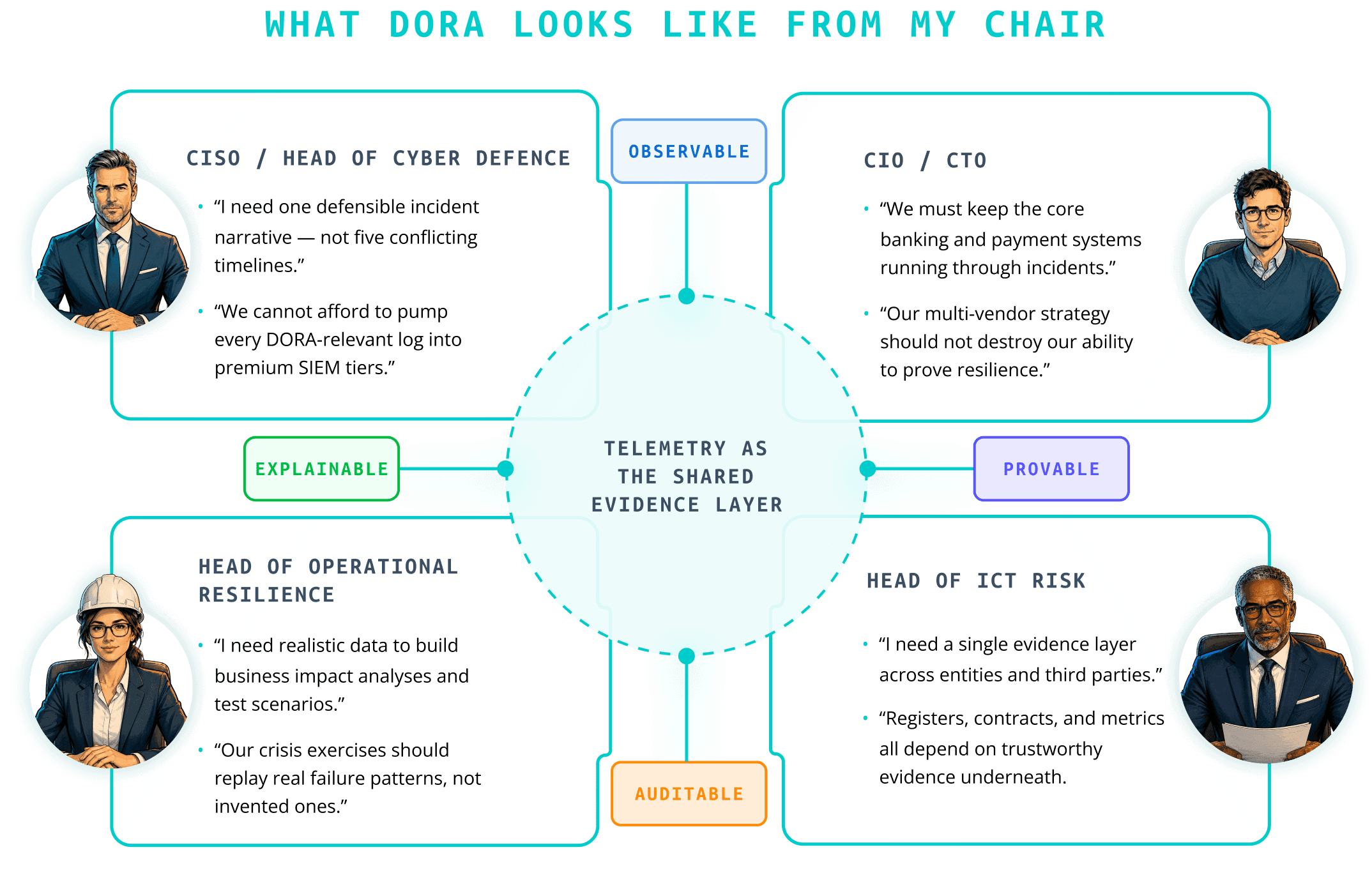
Across all five areas, DORA keeps circling back to the same idea: can you confidently show how your telemetry underpins your story about resilience, across tools, teams, and suppliers?
Required telemetry capabilities for DORA outcomes
Once you strip away legal language, DORA pushes institutions toward three strategic outcomes:
Make resilience provable under scrutiny.
Make resilience affordable at scale.
Make resilience joined‑up across security, IT operations, and third parties.
To get there, three core telemetry capabilities and one cross‑cutting enabler can help.
End‑to‑end visibility and control of data flows
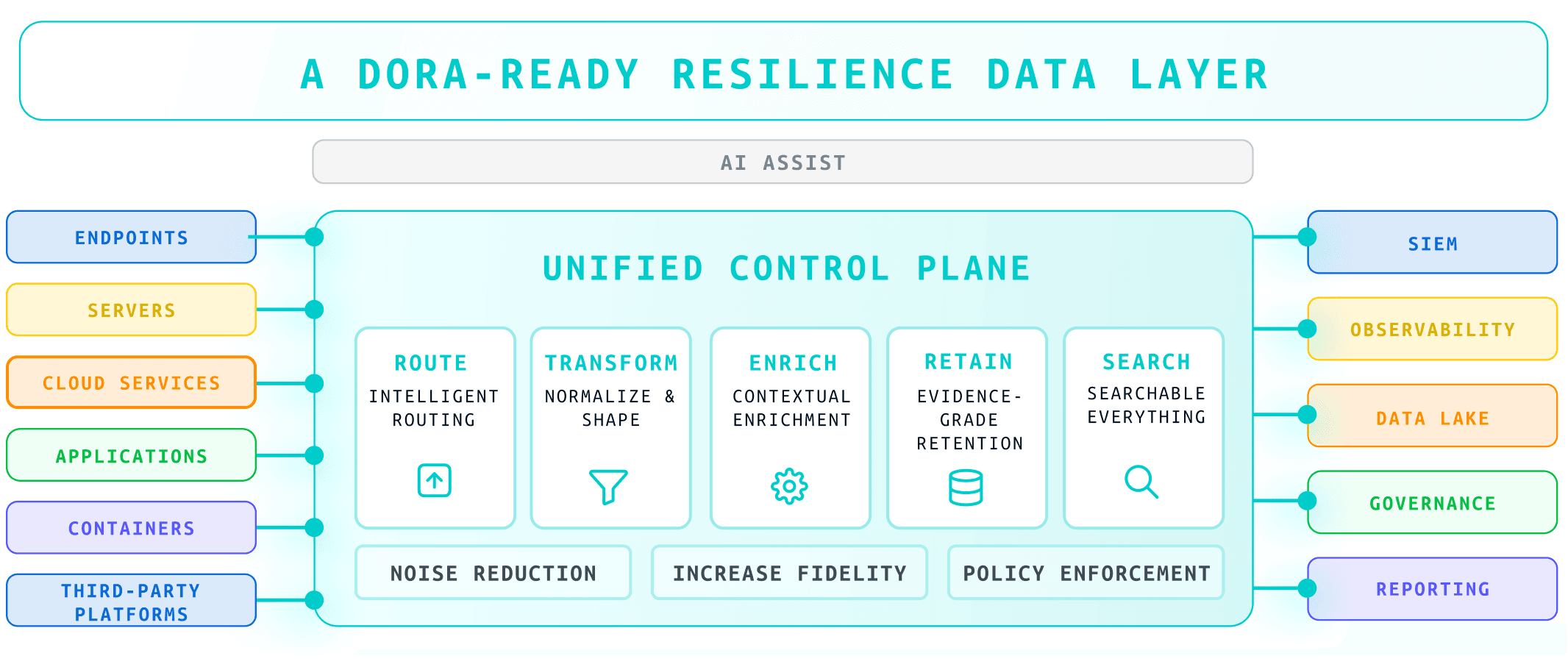
You cannot manage what you cannot see. For DORA, that means more than a network diagram. You should be able to see how telemetry flows across your estate, which sources feed which tools and reports, and how data changes along the way. The messaging brief calls this out explicitly in terms of data lineage and vendor‑neutral collection and routing.
In practice, this looks like a central place where you define how telemetry is collected from servers, endpoints, cloud services, and third‑party platforms; how it is reduced, enriched, and normalised; and where it is sent. It turns a set of ad hoc pipelines into a single control plane.
This is the foundation for showing ICT risk coverage, explaining incidents and tests, and managing third‑party data flows in ways that match your contracts and your risk appetite.
Evidence‑grade availability, retention, and replay
DORA extends how far back you may need to look and broadens the types of events that matter. You might need to reconstruct an incident that began small, spread quietly, and only became obviously material some time later. You may need to show resilience over several years, not just over the last quarter. Namely, if an incident is recurring, you must be able to look back across six months of telemetry.
Your telemetry layer should therefore support long‑term retention in open formats at sustainable cost, with retention policies based on risk and evidence value rather than storage discounts alone. It should also allow you to replay specific slices of history into SIEM, XDR, or analytics tools to reconstruct incidents and tests without running full rehydration projects each time.
When you design this properly, long‑term storage becomes an active part of resilience, testing, and assurance rather than a passive archive.
Faster detection, response, reporting, and audit readiness
DORA does not tell you which tools to buy, but it does care about how effectively you detect, classify, and respond to incidents, and how clearly you can explain your actions.
From a telemetry standpoint, two questions matter. First, are you able to route the right data to the right tools at the right fidelity, avoiding the trap of pushing everything everywhere at full detail? Second, can teams search across hot and cold data in a way that matches how they investigate and report, rather than being limited to whatever happens to sit in one platform?
If your analysts spend more time wrestling with where the data lives than with what the data means, DORA will be painful.
AI‑assisted investigation, reporting, and assurance (on trustworthy data)
AI belongs here as a multiplier rather than a magic solution. On top of a solid telemetry control plane, AI can help analysts ask natural‑language questions of telemetry, surface relevant events more quickly, and generate draft incident timelines and DORA‑aligned summaries for practitioners to refine.
AI can also help you scan for telemetry gaps that might undermine your evidence story and make complex data flows and dependencies easier to explain to non‑technical stakeholders, from boards to supervisors.
The important thing is sequence. If you would not trust the underlying data to defend your case in an audit, you probably should not trust it to drive your AI either.
Cribl as the resilience data layer and AI platform for telemetry
Cribl is the data engine for IT and security, designed to help organisations collect, process, route, and store telemetry from every corner of their infrastructure, on premises and in the cloud. For DORA, that engine becomes a resilience data layer: a vendor‑neutral telemetry control plane that sits upstream of your SIEM, XDR, observability, data lakes, and governance tools.
A reference architecture for DORA‑ready telemetry
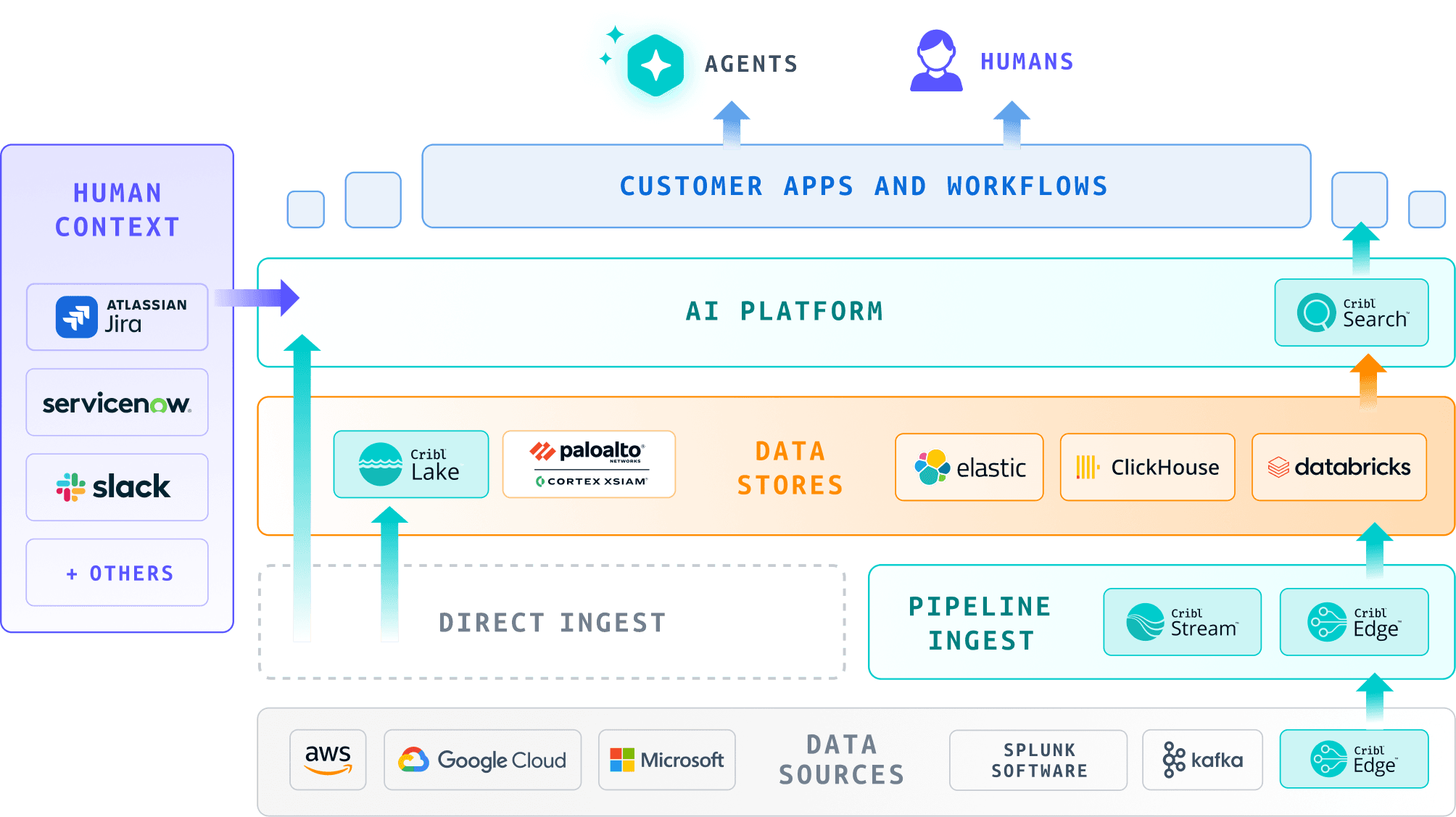
At a high level, a Cribl‑powered DORA architecture weaves together four main product pillars, with AI sitting across them.
Cribl Edge handles collection close to sources. It gathers telemetry from servers, endpoints, containers, cloud services, and third‑party platforms in a vendor‑neutral way, so you are not tied to a specific analytics stack from the moment data is born.
Cribl Stream is the central processing and routing layer. It is here that you reduce noisy data, enrich events with context, normalise formats, and decide where each category of telemetry should go: SIEM, observability tools, data lakes, GRC platforms, or dedicated reporting stores.
Cribl Lake provides open, cost‑efficient storage for long‑term telemetry retention. It allows you to keep full‑fidelity copies of critical data in formats and locations that make sense for DORA evidence, with policies that reflect business risk rather than the quirks of individual tools.
Cribl Search lets analysts and engineers ask questions across these stores and others. Instead of forcing everything into a single SIEM before you can search it, Search supports a federated model where you can reach data where it already lives, including in Lake.
Across this fabric, Cribl AI adds assistive capabilities for search, triage, and summarisation, but always on top of the same evidence layer rather than as a separate side‑car.
Taken together, these components give you a single control point for DORA‑relevant telemetry without forcing you to replace downstream analytics platforms that already work.
How this supports the DORA pillars
Although no product on its own can “do DORA”, this architecture directly supports the work you need to do under each pillar.
For ICT risk management, Cribl helps you maintain end‑to‑end visibility of data flows and dependencies and provides the lineage needed to show which telemetry underpins which services and reports.
For ICT incident management and reporting, Stream ensures that time‑sensitive data reaches the right detection and response tools, while Lake and Search make it possible to reconstruct incidents across long horizons, replay telemetry into SIEM or XDR where appropriate, and base your narratives on evidence rather than guesswork.
For digital operational resilience testing, Lake supplies historical patterns and test data, Stream enforces consistent handling during exercises, and Search lets you compare test behaviour with production behaviour in a structured way.
For third‑party risk, Edge and Stream make it easier to onboard and tag third‑party telemetry, Lake provides independent records of behaviour within the limits of your contracts, and Search helps you understand which services and transactions truly depend on which providers.
For information and threat sharing, the same fabric can be used to extract, enrich, and sanitise threat‑relevant telemetry, while preserving lineage and control over what leaves the organisation.
Mapping DORA articles to Cribl capabilities
This section is not a legal interpretation. It is a practical map between:
DORA’s main areas and article clusters.
The telemetry behaviour they imply.
Where Cribl can help you achieve that behaviour.
A full matrix would be long, so let’s focus on some representative examples.
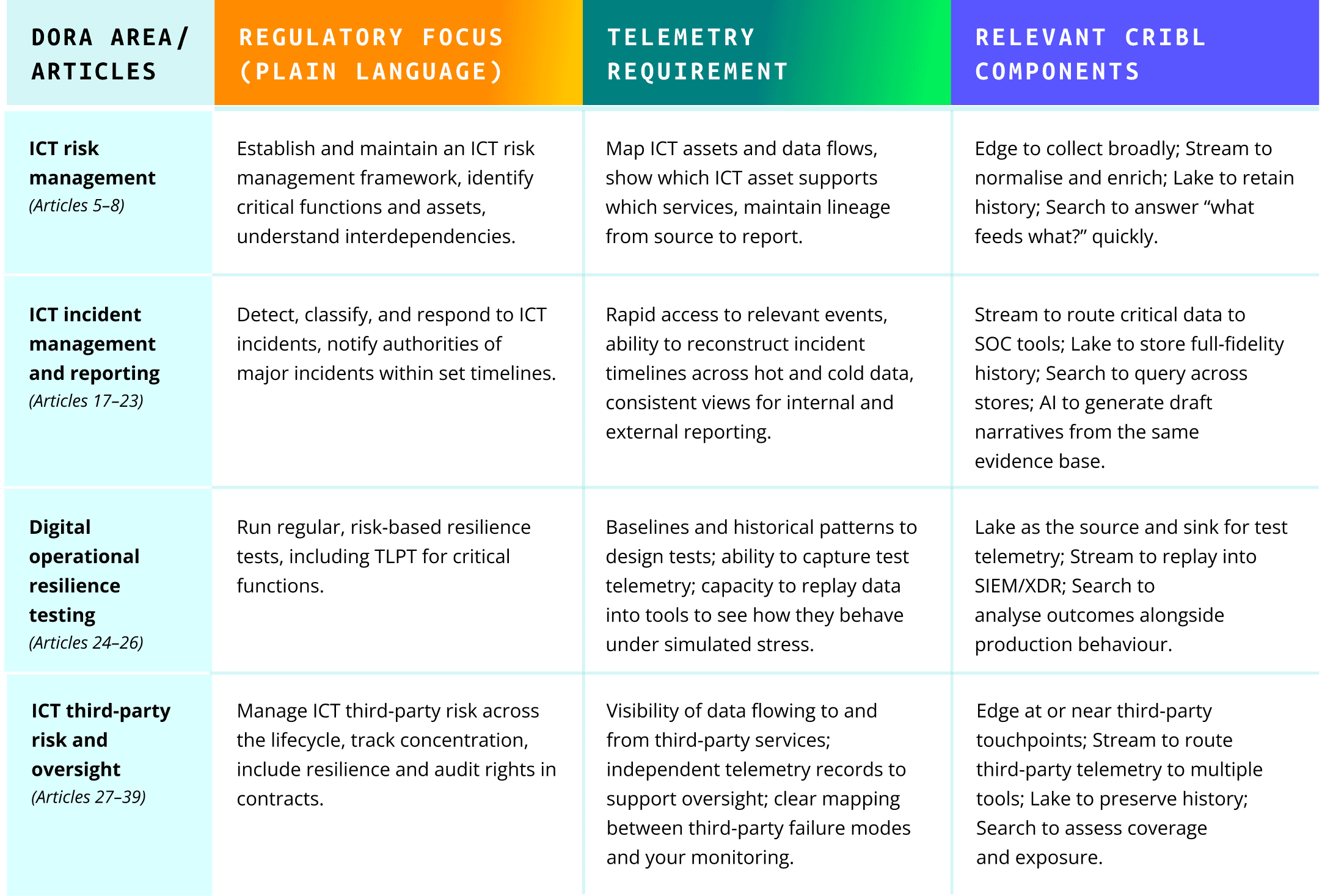
You can extend this mapping internally to align with your own control framework. The key is to keep the “telemetry requirement” dimension honest, then check where Cribl is the right solution, and where other systems must take the lead.
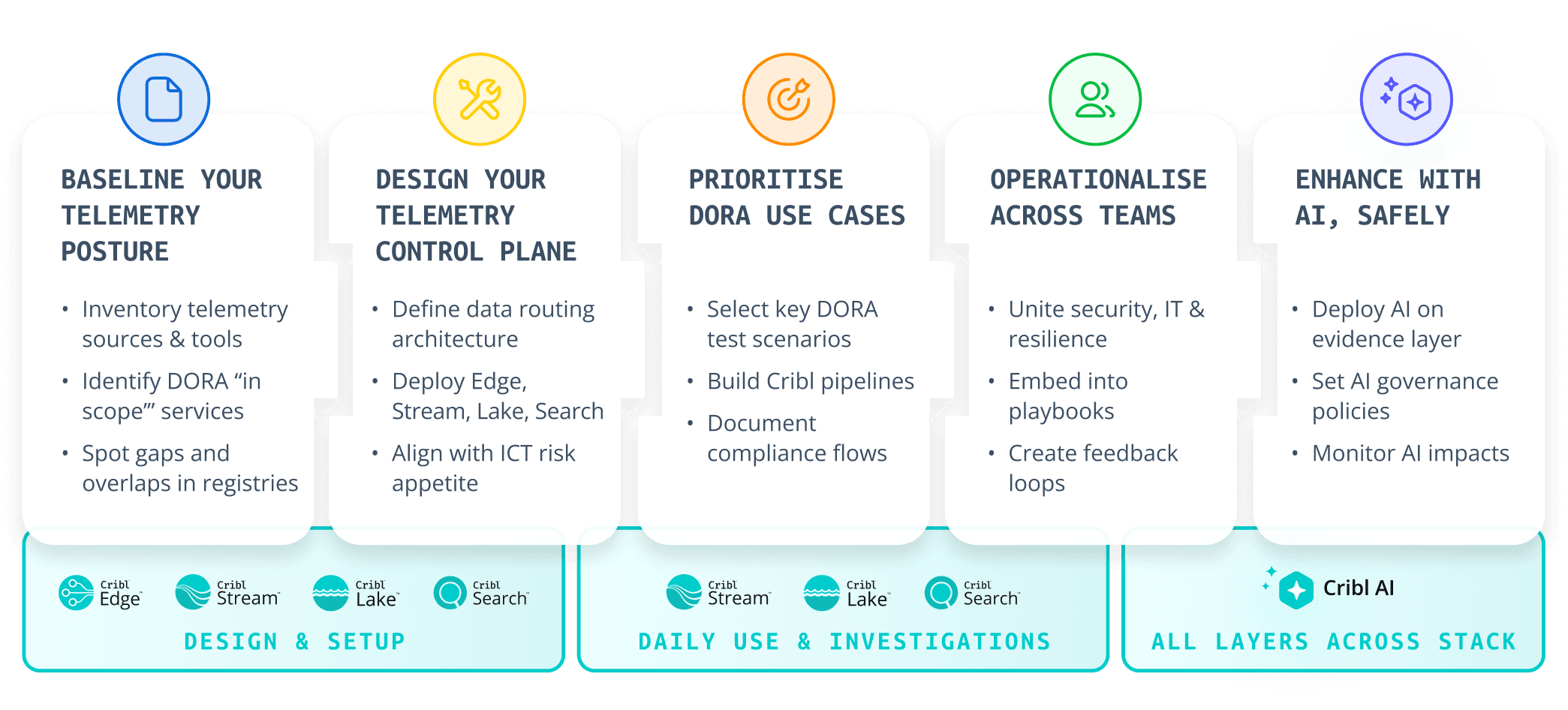
Implementation scenarios: how Cribl supports DORA in practice
Abstract mappings are useful. Concrete stories move people. Here are three scenarios demonstrating how you can leverage Cribl as an evidence layer.
Scenario 1 — Major incident, minor panic
Context:
Imagine a shared payments platform used across several entities suffers a disruptive event with signs of malicious activity. Under DORA, the incident clearly passes the threshold for major ICT incident reporting.
Before a telemetry control plane:
In a typical environment without a coherent telemetry layer, security, IT operations, and the DORA programme office each pull their own data from different tools. They mine SIEM logs, infrastructure metrics, application logs, cloud dashboards, and supplier status pages. They all ask questions to the incident responders, preventing them from actually restoring the services. There is no single shared event timeline. Rehydrating historical data into the SIEM takes time and money. Draft reports from different teams disagree on the sequence of events and even on what counts as “the” incident.
With Cribl as evidence layer:
With Cribl as an evidence layer, Stream has already been routing key payment telemetry, including flows to and from the shared platform, into both analytics tools and Lake. Search queries Lake directly to reconstruct the event path, including failed retries, fallback attempts, and error patterns, without waiting for large rehydration jobs. AI‑assisted workflows on top of Search and Lake generate a draft incident narrative and timeline that analysts can review and adjust. The same underlying dataset then feeds internal lessons‑learned, regulatory notifications, and audit follow‑up, reducing disputes about “what really happened”.
Scenario 2 — Resilience testing that actually teaches you something
Context:
Consider a Head of Operational Resilience planning an annual test of critical payment services. The scenario includes failure of a core messaging component and degraded performance at a cloud provider.
Without strong telemetry foundations:
Test scenarios are based on generic “what if the system is down?” questions, not observed failure modes.
Logging changes for the test are manual and brittle.
Analysing the test afterwards depends on what happens to be in the SIEM at the time, and often diverges from how real incidents behave.
With Cribl in place:
With Cribl in place, past telemetry stored in Lake shows real patterns of degradations and partial failures that can be turned into credible scenarios. Historical data can illuminate how specific change management activities or system updates previously triggered incidents, providing concrete evidence for more effective testing, ultimately improving resilience. During the exercise, Stream applies the same routing and enrichment rules it would in production, so test events pass through the same systems and playbooks. Afterward, Search allows teams to compare the test run with real incidents, highlight false positives and blind spots, and feed those insights back into both playbooks and telemetry policy. When supervisors or internal audit ask how you are testing resilience, you can point to a concrete trail of evidence rather than a slide deck.
Scenario 3 — Third‑party risk, finally illuminated
Context:
Now think about a DORA Programme Lead preparing an updated view of ICT third‑party arrangements and concentration risks for a class of cloud‑hosted applications.
Typical starting point:
Contract registers and procurement systems can show which providers you use and for what services. What they often cannot show is how deeply embedded those providers are in real‑world traffic. Telemetry is scattered across SIEMs, application logs, and cloud consoles, and nobody is quite sure which business services are genuinely critical on a given provider.
With Cribl as telemetry fabric:
Cribl Edge and Cribl Stream have been collecting and routing telemetry tagged with provider and service metadata.
A Search query shows which business services actually depend on a given provider, based on observed data flows rather than assumptions.
Lake holds history long enough to see trends in usage and incidents, supporting conversations about concentration risk and exit strategies.
The DORA team gets a register that is grounded in how the organisation really works, not just how contracts are written.
In all three scenarios, Cribl does not write your policies or negotiate your contracts. It gives you the data backbone to make those conversations faster, calmer, and more grounded.
Conclusion: from documentation to proof
DORA is part of a wider shift in Europe’s financial sector from static compliance towards operational resilience as a lived capability. For CISOs and their peers, that shift comes with a clear message: it will not be enough to say you have the right tools and policies. You will be expected to show, with data, how your controls behave in production, in tests, and across third‑party ecosystems.
You will need to explain how incidents unfolded, how you responded, and how you know that similar events in future will be handled at least as well and what you have learned from past events. If you use AI in detection, investigation, or reporting, you will need to explain what data it relies on and why you trust that data.
Cribl does not remove those obligations. What it can do is give you a vendor‑neutral telemetry control plane across a messy, multi‑vendor, multi‑entity environment, so that the evidence under your DORA story is consistent and explainable. It can turn scattered logs, metrics, traces, and configuration data into a coherent evidence layer that supports ICT risk management, incident response, resilience testing, and third‑party oversight. It can also provide an AI‑ready foundation for faster investigations and clearer reporting without locking you into a single analytics stack.
If you want to move from “we hope we can find the data” to “we know we can prove what happened”, now is a good moment to look at how your telemetry is organised.
To explore how Cribl’s AI platform for telemetry can underpin your DORA strategy as well as other resilience and security priorities, you can start here:
