

Cribl Stream and Cribl Edge can send data to Splunk in several different ways. In this blog post, we’ll focus on the common scenario where you want to connect Cribl Stream’s Splunk Load Balanced Destination to many Splunk Indexers at once. (We’ll talk about Cribl Stream, but what we say applies to Cribl Edge, too.)
Cribl Destinations settings default to reasonable values. Sometimes Cribl Support recommends changing those values for better results in a given situation. In this blog, we’ll look at changing a few key settings to allow a single Splunk Load Balanced Destination to play nicely with many Splunk Indexers at once.
Before you dive in, you may want to read these Cribl blogs about Splunk performance considerations:
For Better Recovery from Splunk Outages, Use PQ with Strict Ordering Off
Downstream receivers like Splunk can experience outages – that’s why Cribl Destinations have the Persistent Queue (PQ) feature. Since Splunk has the ability to handle events that arrive out of order, PQ’s Strict ordering feature is not necessary. Turning it off improves recovery from Splunk outages.
Toggle Persistent Queue on, and in the Persistent Queue Settings:
Toggle Strict ordering off.
Set Drain rate limit (EPS) to roughly 5% of the Events Per Second (EPS) throughput rate.
See this blog to learn more about setup and calculating the right Drain rate limit (EPS) value

To Minimize Back-and-Forth Between Cribl and Splunk, Don’t Require Splunk to Acknowledge Every Request
By default, every request will check whether the indexer is shutting down, or is still alive and can receive data. This makes Cribl/Splunk interaction unnecessarily noisy. To fix this, you can configure Cribl to check whether the Splunk endpoint once per minute.
In Advanced Settings:
Toggle Minimize in-flight data loss off.
Leave Max failed health checks set to `1` (the default).
Set Max S2S version to `v4` – using S2S version 4 results in a less noisy communication between Cribl Destination and Splunk indexer.

Don’t Swamp Splunk Indexers with Too Many Connections from Cribl
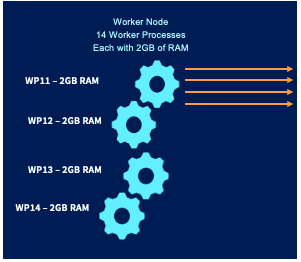
By default, every Worker Process in Cribl Stream makes a TCP connection to every Splunk indexer. This means that if (for example) you have 10 Cribl Stream Workers, each with 14 Worker Processes running, and these are connecting to 100 Splunk Indexers, each Splunk Indexer will have to handle 140 concurrent connections.
High numbers of concurrent connections can overwhelm a Splunk indexer. If this happens, the Cribl Stream Monitoring page should show a warning message that the connection to Splunk is unhealthy. The remedy is to control how many indexers a Cribl Stream Worker process will connect to at any given time.

Because the Max Connections defaults to `0`, meaning “unlimited” or “all indexers,” the Worker Process will open as many connections as it can, unless you set Max Connections to a value that’s smaller than the total number of indexers.
In Advanced Settings:
Set Max Connections to a subset of the total indexers.
In the example above, we had 100 indexers. If you set Max Connections to 75, any given Cribl Stream process will connect to only 75 instead of all 100 processes at any given time. Roughly 75% of the number of Splunk Indexers is a good value to start with.
How do you ensure that every indexer receives data from some Cribl Stream Worker at some point?
Here’s the answer: Assuming that your Destination connected successfully with Splunk before you started reading this blog, then you’ve made the entire pool of IP addresses (representing the complete set of indexers) available to your Destination. Cribl Stream will rotate through the IPs, choosing a random set of IPs for every DNS resolution period, and this distributes the data fairly among all the indexers over time.

Don’t Swamp Splunk Indexers, Continued
Beyond reducing concurrent connections, another way to resolve unhealthy connection warnings is to make the connection timeout longer.
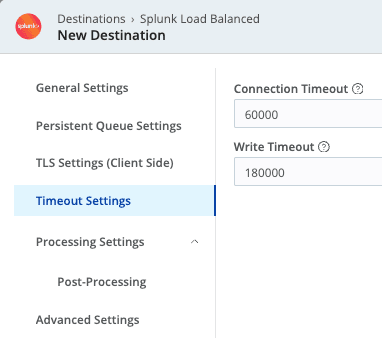
In Timeout Settings:
Set Connection timeout to
30000milliseconds (30 seconds) or60000milliseconds (1 minute), making the timeout longer than the default of `10000` milliseconds (10 seconds).Set Write timeout to
120000milliseconds (120 seconds) or180000milliseconds (180 seconds), making the timeout longer than the default of `60000` (60 seconds)).
Don’t Let Connections Use Too Much Memory
When you connect a Cribl Destination to a very large number of Splunk indexers, Cribl Stream can run out of memory. Why is this and how do you fix it?
In Cribl Stream:
Under the hood, memory allocation is done by Node.js.
Each Worker Process manages its its own memory independently – no memory is shared across the whole Worker Node.
Buffers are reserved from memory even when no events are passing through.
The general guideline for memory allocation is to start with the default `2048 MB` per Worker Process.
This translates to between 2 and 4 MB RAM per Splunk connection, per Worker Process.
For example, for 100 connections you’ll see between 0.25 GB and 0.5 GB of RAM per Worker Process.
You can see how a large number of connections from your Cribl Destination can demand lots of memory. If Cribl Stream starts running out of memory due to the number of destination connections, there are two remedies:
Allocating more memory to each Worker Process, and
Limiting the number of Splunk indexers a Worker Process can connect to at one time.
Allocating more memory to each Worker Process
By default, Cribl Stream allocates 2048 MB memory to each Worker Process.
In Group Settings:
Increase memory allocation for Worker Processes from `2048` MB to `3072` MB.
You may need to allocate more RAM on the hardware first.
In the illustration above, 14 Worker Processes times 3072 MB means that the hardware will require 44 GB of RAM per Worker Node.

Limiting the number of Splunk indexers a Worker Process can connect to at one time
In Advanced Settings:
Set Max Connections to a lower value as described in the Don’t Swamp Splunk Indexers section above.
Conclusion
In this post, we’ve seen how you can connect the Cribl Stream Splunk Load Balanced Destination to a large number of Splunk indexers, while avoiding unnecessarily noisy Cribl/Splunk interactions, not swamping Splunk with too many Cribl connections, and recovering gracefully from Splunk outages. Check out our Cribl Docs for more information!







