

Cribl Stream offers different ways to optimize data, such as:
Formatting and cleaning whitespaces
Field Removal
Sampling
Filtering out based on granular criteria
Aggregating data
In this blog, I will focus on the Aggregation use case using the Aggregations function and how you can practically use the Aggregations function to format the output in different ways.
I will start with the simplest way of using Aggregations and gradually move into more complex data transformations to showcase how you can format the Aggregations output on Cribl Stream and have a minimal impact on your existing SIEM rules and searches, if any, while benefiting from the data optimization results.
Cribl is built on a shared-nothing architecture, meaning each worker process will operate separately. This will limit the expected reduction percentages, especially in large Cribl environments with many worker processes, as events arriving on separate Worker Processes will not be aggregated.
For optimal reduction benefits with the Aggregations function, it is highly recommended to use a caching tier, such as Redis, to share the state across the different processes.
This blog doesn’t cover Redis, but a good start with Redis and Cribl is the Redis Knowledge Pack on Cribl’s dispensary.
The Details
I’ve used the Palo Alto Networks Traffic data in this example. However, there are many other great candidates for Aggregations such as Network Firewalls, WAFs, Web Proxies, IIS and Cloud Flow Logs.
A sample of the PAN Traffic data in its CSV format looks like this:

PAN Traffic Sample
We will review three scenarios based on the same sample data, each outputting a different format. The scenarios are detailed enough for you to choose from them based on your needs and required output.
Scenario 1: Aggregations and Ingest-time Fields
We first need to parse the data and have Cribl Steam recognize the different fields so we can use them in the subsequent functions. For this, we will use the Parser function and leverage the embedded Parser Library.
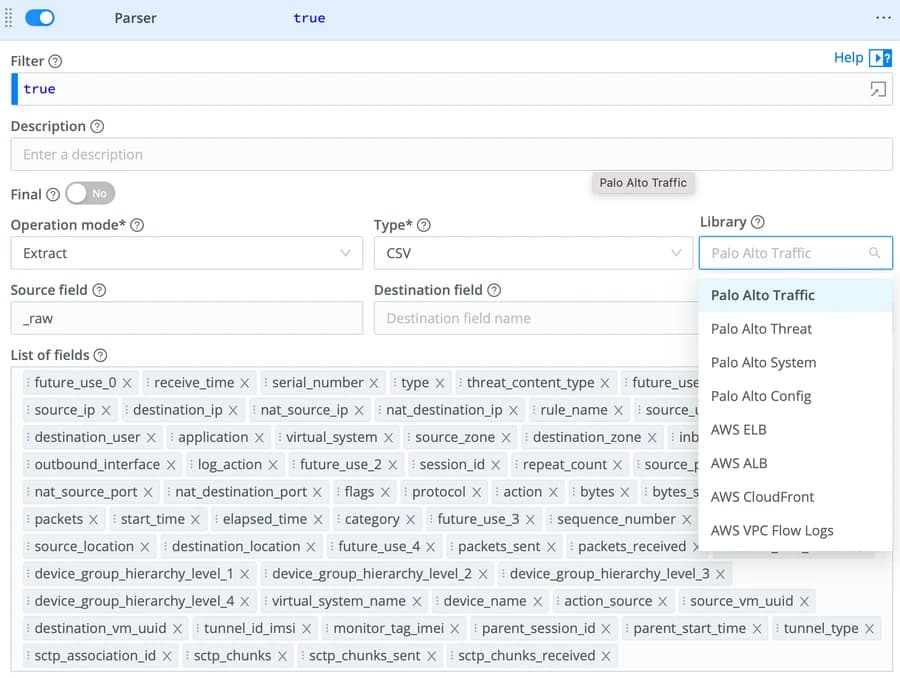
Parser Function
Now that we have parsed the data, we can see the different fields on the output.
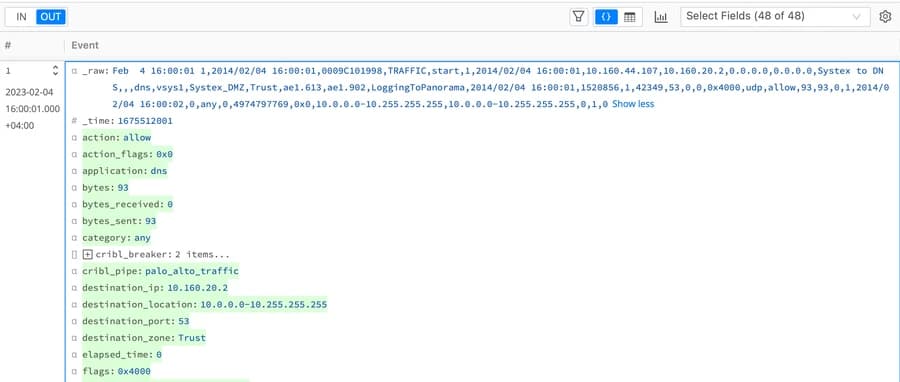
Parsed Fields
The “Aggregates” are the function(s) we will run on the data. They will allow us to maintain the accuracy of the numbers while sending out a single event out of many.They also allow us to pass the number of Aggregated logs into the SIEM destination. This is very powerful for SIEM use cases that rely on the number of events such as “Brute Force Attacks.”
We will then pick the following five fields to group aggregates by. Depending on your data, you may need to add more fields to achieve an accurate grouping.
source_ip
destination_ip
destination_port
action
protocol
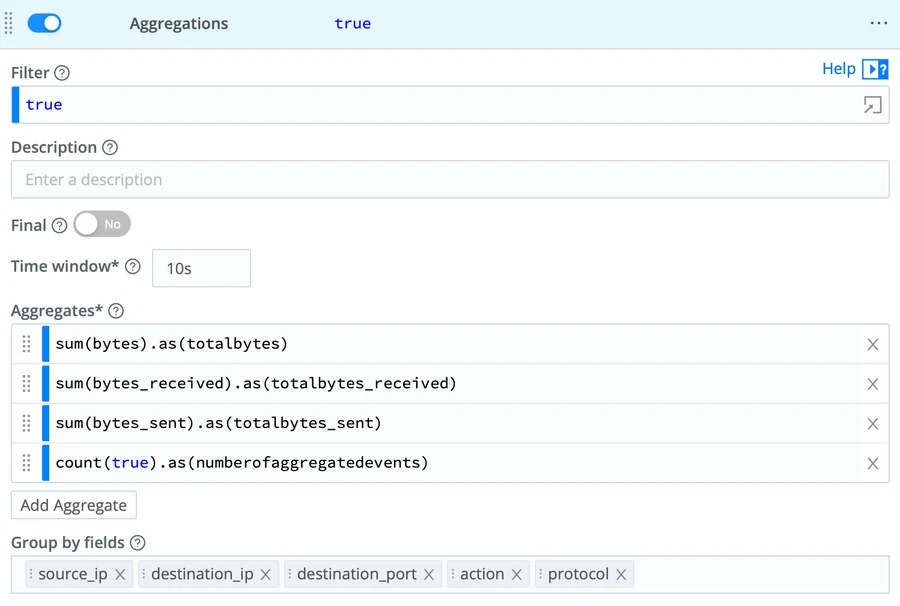
Aggregations Function
The output will look as follows:
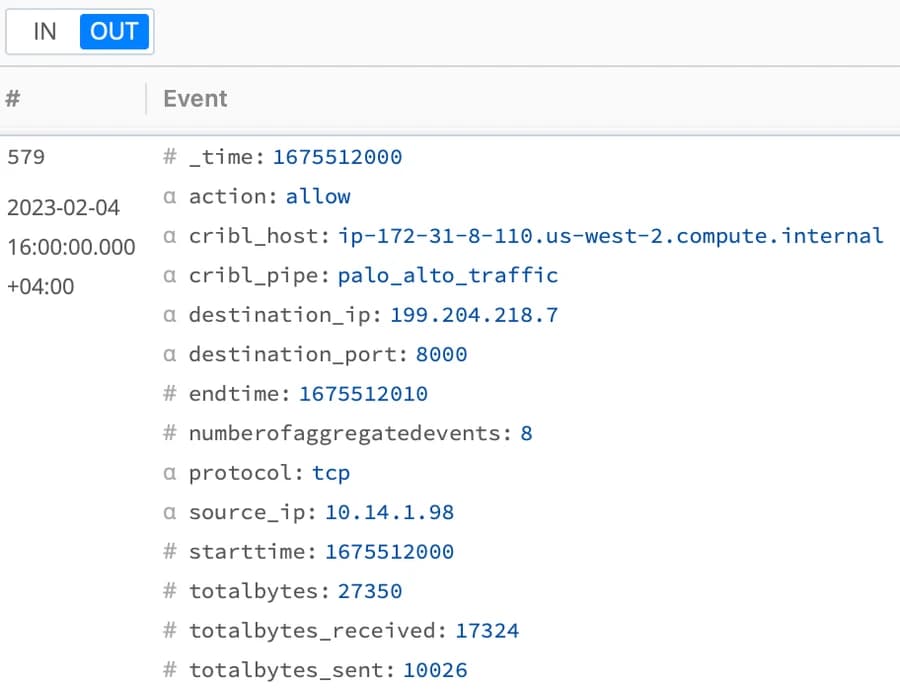
Aggregations Output
Scenario 2: _raw and Ingest-time fields
You may have noticed that we’ve lost the original _raw field after running the Aggregations. Depending on your use case, you may need to maintain the _raw field and pass it to your SIEM destination.
To do so, we will update the Aggregations function with two entries:
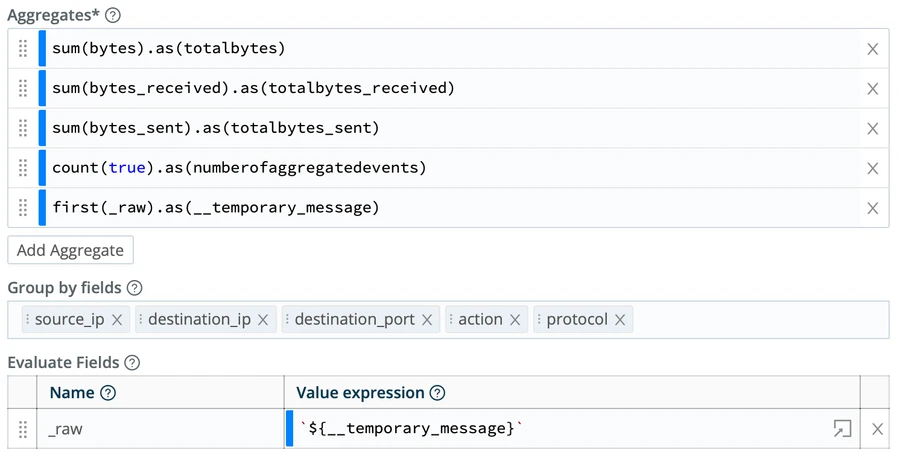
Add to the Aggregates the
_rawfield of the first aggregated log into a temporary message (notice the use of the__to make as an internal Cribl field.Then, use the Evaluate Fields option of the Aggregates function to put this temporary message into the
_rawof the aggregated output.
Maintain _raw
Our aggregated output format now looks almost similar to the original log format.
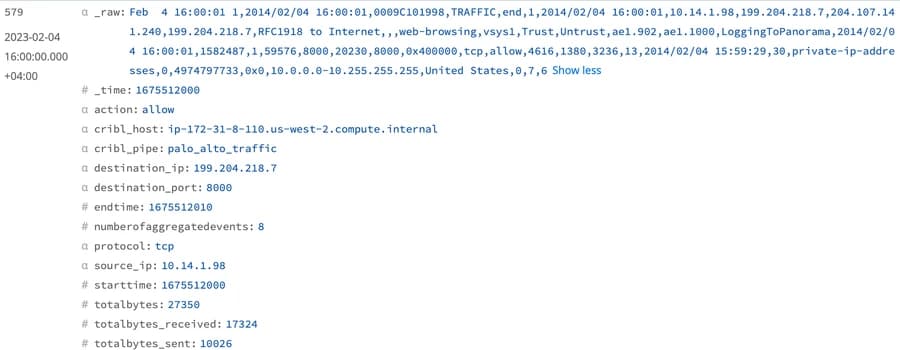
Output with _raw field
You can then run a separate Eval function to clean some of the fields that you don’t need.
Scenario 3: Update the _raw field
Now that we have seen how we maintained the _raw field in the aggregated output, we can optimize our data further. For instance, the _raw field still maintains the values of the first event added to the Aggregations. More specifically, the values of “bytes”, “bytes_received” , and “byte_sent” are the original values of the first aggregated event which are logically not equal to the “totalbytes”, “totalbytes_received” , and “totalbytes_sent”. You can simply update your SIEM rules, reports, and dashboards to use these new fields.
But in many cases, you may want to limit the changes needed on your SIEM. In this case, you can use the power of Cribl Stream functions to update the _raw field with these aggregated numbers and save time on SIEM rule changes.
To do so, we will parse the _raw of the aggregated events, run an Eval function to replace the “bytes” with the “totalbytes” and serialize the data.
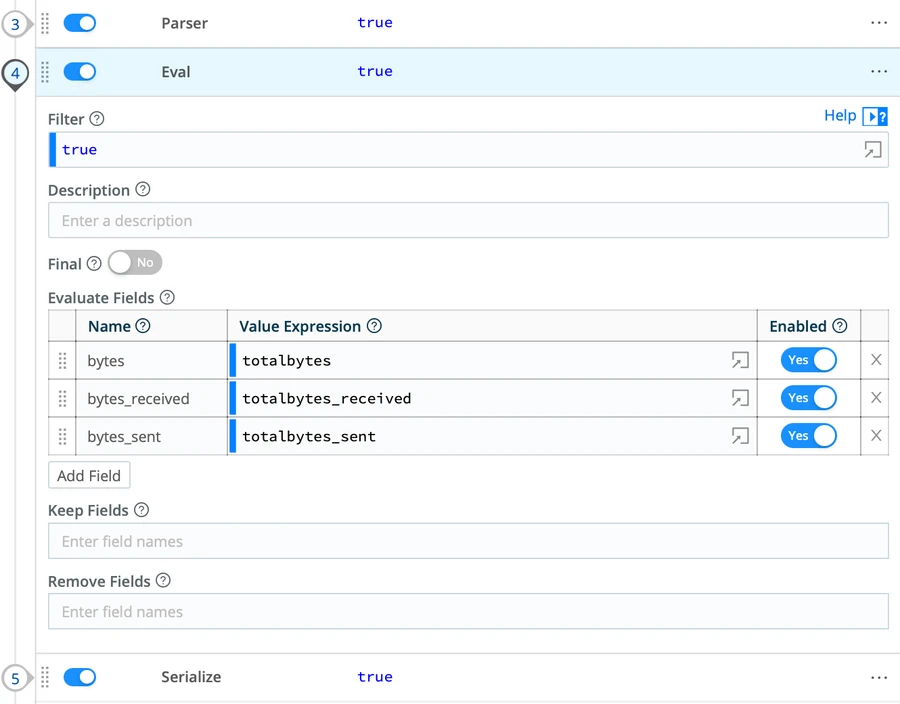
Aggregations back to _raw
We can finally run an Eval to clean the output and maintain only the _raw, _time, and the “number of aggregated events.”
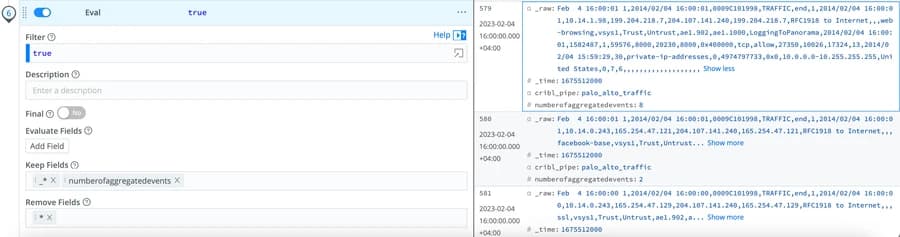
Final Eval
Wrap Up on the Aggregations Output
The Aggregations function allows you to optimize different types of security data before ingesting it into your SIEM. The flexibility of the Aggregations function, along with other Cribl Stream functions, helps you format the data output in different ways to satisfy your requirements. Consider using a caching tier, like Redis, to get optimal reduction results in production environments. While we focused on the SIEM and security data, these techniques can be applied to different datasets and Cribl destinations.






