
Scaling up with NodeJS
This is the second post in a series aimed at describing how we designed Cribl Stream to scale to process 10s of PBs of machine data per day. If you want to read why such scale is important check out part 1.
In this post we’ll focus on scale-up, that is how Cribl Stream is able to efficiently use all the resources allocated to it, in a single instance. One important aspect of scale-up is the ability to respect a resource upper bound set by an admin – e.g. consume at most 6 out of 8 cores.
Whenever a scaling problem comes up we ask these 3 questions:
Can the problem be solved more efficiently, so as to avoid scaling altogether?
Can we achieve the required scale by scaling up?
To what degree do we need to scale out?
Asking these questions ensures that (a) we’ve tried our best to avoid scaling out unnecessarily and (b) we’re scaling out using highly efficient components. Generally, spending time on question #1 can usually improve performance by ~2x, on question #2 can yield another 10-100x (depending on number of cores) – thus, we can get significant scale improvements before scaling out.
Before diving into how we’ve scaled up, let’s look at what is that we’re trying to scale up. Cribl Stream is a streams processing engine built specifically for machine data. The following marchitecture diagram shows how data flows through the system.
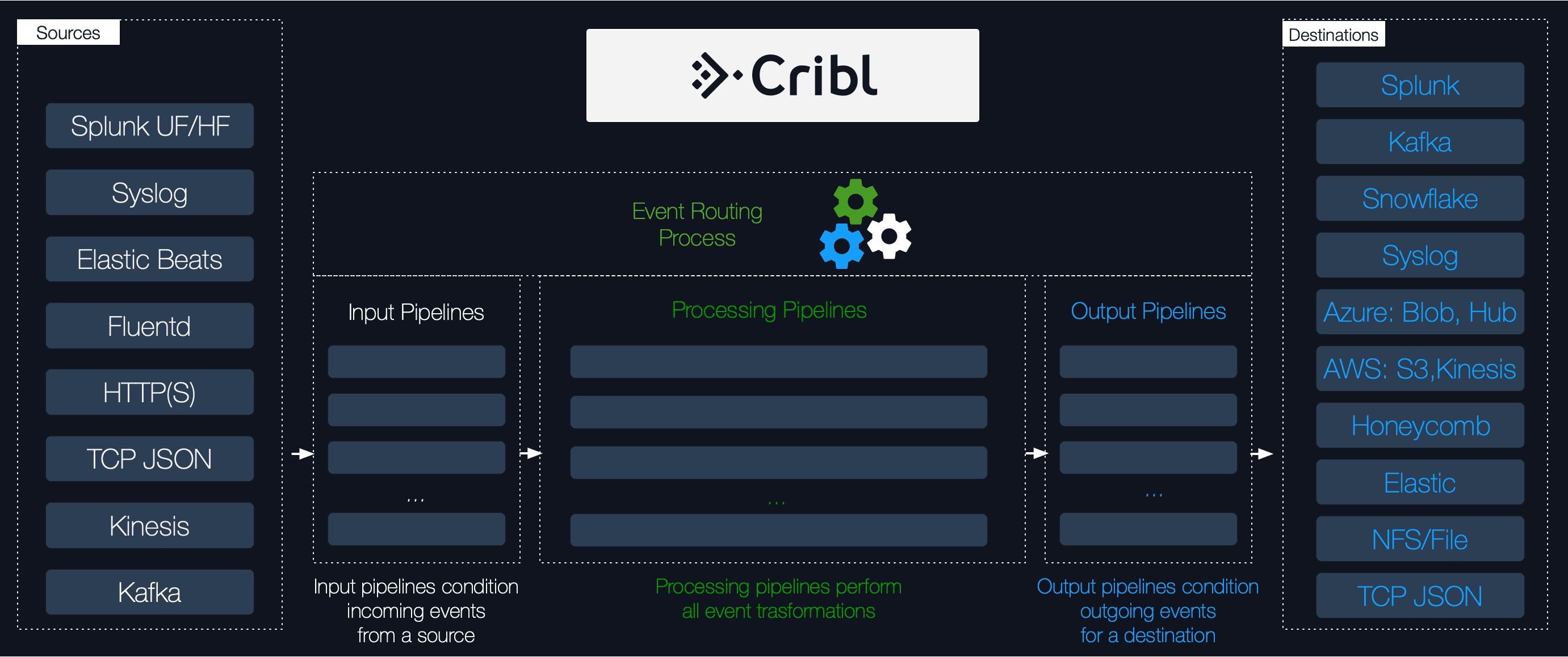
Generally data is pushed via TCP or UDP on a variety of different formats, Syslog, HTTP, Splunk, TcpJSON, SNMP etc. or pulled directly from external systems like Kafka, AWS S3 etc. The first order of operation is protocol parsing and creating objects that users can operate on (we call these events, not to be confused with NodeJS event emitting). Once we have a stream of events, we apply the logic that users specify in Routes & Pipelines, which can be things like: filtering, rewriting, extracting fields, masking, enriching, aggregations etc. Finally the processed events need to be serialized and sent to a destination system, which could be of different type than the incoming source (e.g data can come via Syslog but might need to go out to Kafka).
Cribl Stream is written in TypeScript and runs on NodeJS, however it is shipped as a native binary, read more about why we chose to ship the runtime. NodeJS has proven tremendously helpful in enabling us not only get to market quickly, but also provide solid performance that compares to that of C/C++ code (read more about how the V8 JavaScript engine is able to do that). However, there is one wrinkle, that any CPU intensive work done in JavaScript code maxes out at a single core – it’s a wrinkle, because on the positive side one can confidently assert that a NodeJS application will consume at most one core (there are situations where this is not quite the case due to work done in the libuv’s thread pool, like de/compression etc, but our workloads are mostly JS bound). So, now the question is how do we scale up a system built in NodeJS?
In order to effectively answer that question, we first need to understand where in the data flow is most of the time spent. We ran a number of performance tests and observed that the bulk (50-80%) of the CPU time is spent on serializing and deserializing events to/from byte streams – therefore, any scale-up options that require an extra layer of serialize/deserialize are not viable.
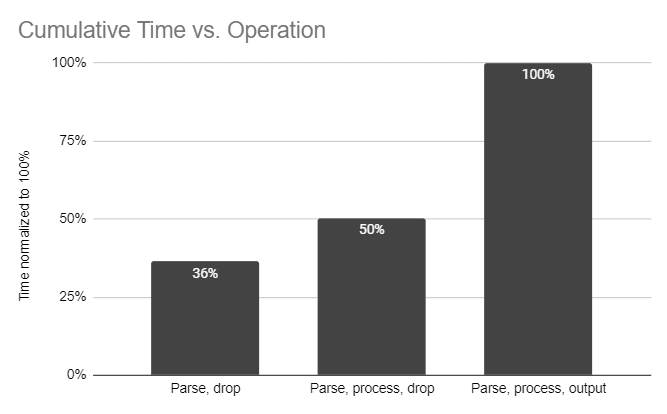
We’ll discuss two of the options we considered:
worker_threads – we’ve been following the fantastic work that Node community and especially Anna Henningsen have done to help with CPU intensive JavaScript code. Originally this seemed like the way to go. However we decided against it for two reasons:
memory sharing model is based on serialization and/or by using SharedArrayBuffer-s which would require serialization thus making worker threads pretty heavy weight in terms of getting data in/out
any instability of either the worker_threads module or our code causing the process to crash (an example we found much later) or get killed (OOM killer) would result in entire process going down
cluster – this module has been around since the early NodeJS days, it utilizes processes and IPC for passing messages and also file descriptors/handles – the latter being key.
We chose to go with cluster module and follow a process model where a master process is responsible for starting N worker processes – ie capping CPU consumption to N cores.
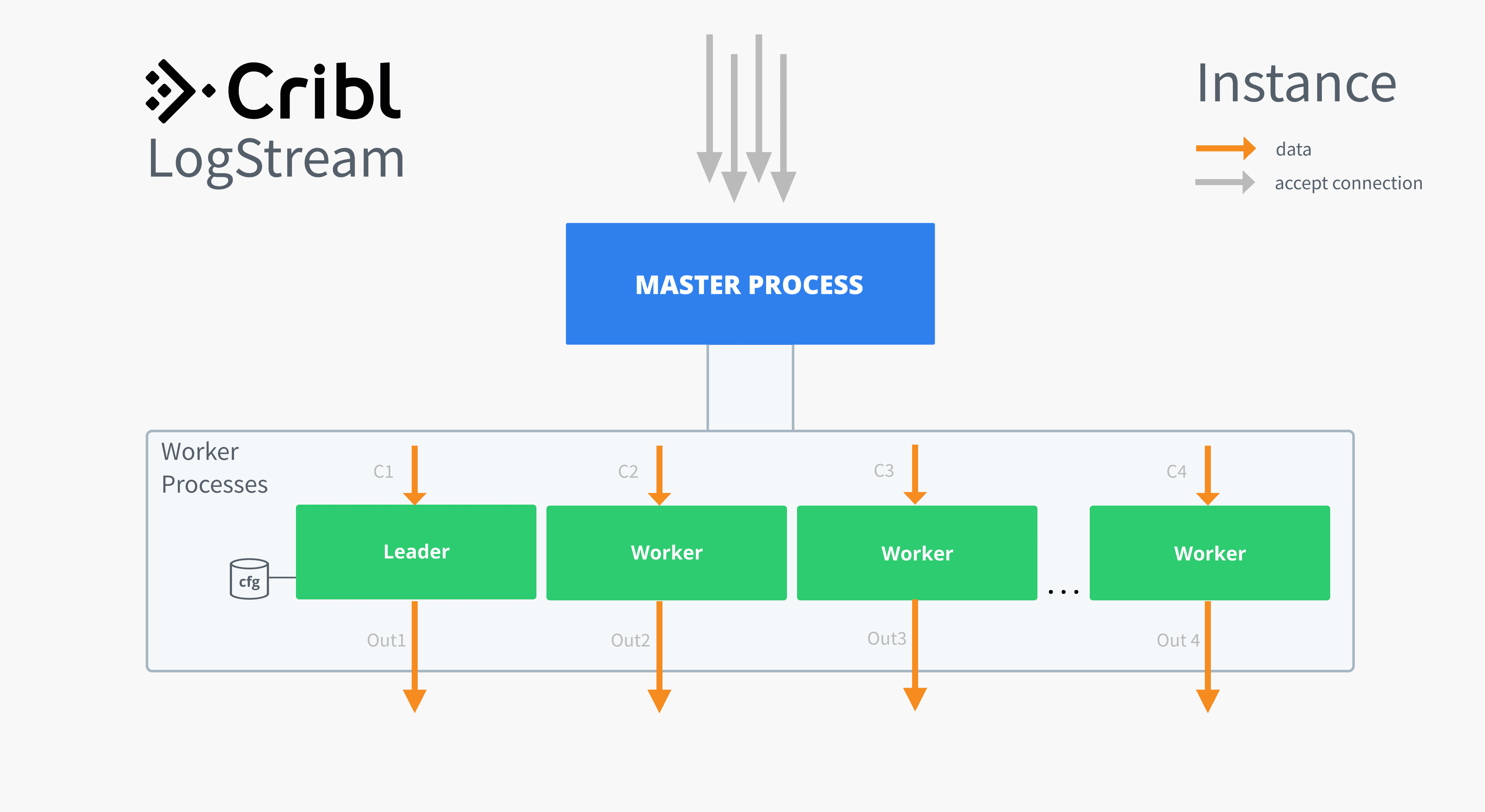
The master process stays completely out of the data path and is responsible for serving management API requests and keeping stats. To increase the system’s resiliency the master process also acts as a watchdog for worker processes, restarting any that exit or crash. Furthermore, the master process is responsible for listening on all the ports that Cribl Stream is configured for, it then accepts socket connections and assigns them to worker processes – this is why the ability to pass file descriptors to child processes is key, and NodeJS’s cluster module achieves this very elegantly.
Note, this model of scale-up is not novel by any means, e.g. a successful example system using this model is Nginx.
We’ve managed to scale up inside an instance using the same principles behind shared nothing distributed architecture – worker processes within a node act completely independently of other worker processes. Overall, we’ve seen the throughput of the system scale linearly up to about 100 worker processes – using AWS C5.24xlarge instances, we’ll retest once larger instances become available. An area of improvement we are currently researching is the ability to fairly load balance connections/requests to workers – currently we’re using a round-robin assignment of connections, however not all connections impose the same load on the worker-processes.
In the next post we’ll go over our scale-out architecture and design decisions we made along the way. Stay tuned …
One more thing, we’re hiring! If the problems above excite you, drop us a line at hello@cribl.io or better yet talk to us live by joining our Cribl Community.




